はじめに
これは Kompira Enterprise 2.0 (KE2.0) の管理者マニュアルです。
システム管理以外の Kompira Enterprise の一般的な使用方法などについては、システム構築後に Kompira Enterprise のオンラインマニュアルを参照してください。
仕様情報や活用事例については、Kompiraシリーズ製品情報サイト を参照してください。
なお本マニュアルでは、読者が実際の値に置き換える箇所を <...> (山括弧)で示します。例えば docker exec ... manage.py <SUBCOMMAND> と記載している場合は、<SUBCOMMAND> の部分を実行したいサブコマンド名に置き換えてください。
最終更新日: 2026/07/15
改版履歴
未リリース
変更
- トラブルシュートガイドを再編しました。「症状から」「構成から」「コンポーネント別の原因と対処」から調べられるよう整理して診断手順の導線を改善し、高負荷時に環境変数の調整で改善しうる事象(DB 接続数の上限超過・Web ワーカ枯渇による応答遅延・重い処理のタイムアウト)の調査導線と高負荷時のチューニング(環境変数)の解説、解決しない場合に備えたサポートへの問い合わせ前に(情報収集)も追加しました。
- 各構成のアップデート手順に、環境変数や設定ファイル (パラメータ) の反映に関する注意を追記しました。設定の変更はコンテナの再作成で反映される (restart だけでは反映されない) こと、cluster/swarm 構成では setup_stack.sh を再実行して docker-swarm.yml を作り直す必要があることなどを説明しています。
- cluster/swarm 構成の構築ガイドに、実機構築で判明した注意点を追記しました。共有ディレクトリ (log/var/ssl) をセットアップ実行ユーザが書き込みできるようにする必要があること、Pgpool-II 起動直後は仮想IP の割り当てに数秒かかること、SSH 接続設定スクリプトは実行ユーザが全ホストへログイン・sudo できることが前提であること、VMware の vmxnet3 ネットワークインタフェースかどうかの見分け方を補足しています。
- 環境変数リファレンスに、高負荷時の応答性を改善するためのチューニング設定 (Web ワーカの並列度・タイムアウト、nginx のタイムアウト、PostgreSQL のチューニング) の説明を追加しました。調整が必要になる場面ごとの指針や、PostgreSQL の最大接続数の見積り方もあわせて示しています。
- 資格情報管理の章を新設しました。データベースや RabbitMQ のパスワードなどの資格情報について、各構成 (single/basic・外部DB・cluster/swarm) での指定方法、既定値の一覧、パスワードの変更手順、URL に使えない文字を含む場合の扱い、本番運用前のチェックリストなどをまとめています。あわせて外部DB構成・外部連携構成・cluster/swarm 構成の構築ガイドの記述と例示値も見直しました。
- マニュアル全体の誤字・脱字を修正しました。トラブルシュートガイドについては、助詞抜けや言い回しの誤りなど文章の誤りもあわせて修正しています。
- トラブルシュートガイドなどで、インデントが原因でコードブロックが正しく表示されずフェンス記号がそのまま見えていた箇所を修正しました。あわせて一部のコマンド例の誤り (引数の順序) も修正しました。
- ドキュメント全体で、読者が実際の値に置き換える箇所を示す
<...>プレースホルダの表記を統一しました。コマンド例などに現れるプレースホルダを英大文字表記にそろえ、記法の説明を「はじめに」に追加しています。
2025/08/01 (2.0.4)
変更
- SSL証明書の管理を更新しました。
- Let's Encryptの場合を追加しました。
2024/12/03 (2.0.2)
変更
- 保守ガイド/シングル構成の保守を更新しました。
- 保守ガイド/外部DBシングル構成の保守を追加しました。
- 管理ガイド/ログ管理/コンテナログ管理を更新しました。
- 管理ガイド/ログ管理/サービスログ管理を追加しました。
- トラブルシュートガイドを追加しました。
2024/10/16 (2.0.2)
コンテナイメージ
- KOMPIRA_IMAGE_TAG=2.0.2 に対応しました。
変更
- 暗号化秘密鍵の手順を更新しました。
- システム管理/システムステータスの確認を追加しました。
- クラスタ構成のアップデート手順を更新しました。
- クラスタ構成の保守ガイドを追加しました。
- ke2-docker に合わせて環境変数の説明を更新しました。
- 環境変数によるロギング設定について追記しました。
- pip install するときの kompira-sendevt のバージョン指定を更新しました。
- docker-compose-plugin について v2.24.6 以上が必要であることをシステム要件に追記しました。
2024/08/01 (2.0.0)
- KE2.0.0 リリース
用語
本マニュアルで登場する用語について説明します。
| 用語 | 説明 |
|---|---|
| KE | Kompira Enterprise の略称。 |
| Kompira Engine | KE を動作させるための中核機能。 |
| Kompira Jobmngrd | RabbitMQ から指示されたリモートコマンドを実行するためのデーモンプロセス。 |
| uwsgi | KE を Web 上で使用するためのアプリケーションサーバー。 |
| nginx | Web 上から KE を操作するための Web サーバーソフト。 |
| Redis | KE を Web 上で使用するにあたり必要なデータベース管理システム。キャッシュサーバーの役割を担う。 |
| RabbitMQ | 各システム間の処理上で必要となる処理メッセージを管理するためのソフト。 |
| PostgreSQL | KE のデータを保存するための DB サーバー。 |
| Docker | コンテナ型仮想環境用のプラットフォーム。 |
| Docker Compose | オンプレ環境において、コンテナ上で KE2.0 を動作させるためのツール。 |
| Docker Swarm | Docker に対応したクラスタリング用ツール。KE2.0 をクラスタ構成する際に用いる。 |
ライセンス
Kompira Enterprise を利用される場合は、必ず Kompira Enterprise ライセンス利用規約 をよくお読みください。
Kompira Enterprise を継続して利用される場合はライセンス登録が必要になります。詳しくは license@kompira.jp までご連絡ください。
システム概要
KE2.0 のシステム概要について示します。
システム要件
KE2.0 のシステム要件について記載します。
ホストのシステム要件
| 項目 | 必須 | 推奨 | 備考 |
|---|---|---|---|
| メモリ | 8GB 以上 | 16GB 以上 | |
| ディスク | 64GB 以上 | 256GB 以上 | |
| CPU コア数 | 4 コア以上 | ||
| Docker engine | version 24.0 以上 | ||
| Docker compose plugin | version 2.24.6 以上 | ||
| アーキテクチャ | x86_64 |
- 必要なスペックは Kompira 上で動作するジョブフロー規模、自動化の処理要件によって異なります。
- 記載要件は最低レベルで記載しております。お客様の運用環境によっては異なる場合がございますのでご了承ください。
動作確認済みホストOS一覧
- Rocky Linux 8.10 (x86_64)
- Rocky Linux 9.4 (x86_64)
コンテナ構成
KE2.0 のコンテナ構成を以下に示します。
コンテナ一覧
| コンテナ名 | コンテナイメージ | 役割 |
|---|---|---|
| kompira | kompira-enterprise/latest | Kompiraアプリケーション |
| kengine | kompira-enterprise/latest | ジョブフローの実行 |
| jobmngrd | kompira-enterprise/latest | リモートジョブの実行 |
| postgres | postgres/16.3-alpine | データベース |
| rabbitmq | rabbitmq/3.13-alpine | AMQP メッセージング |
| nginx | nginx/1.27-alpine | HTTP(S) フロントエンド |
| redis | redis/7.2-alpine | キャッシュ |
※ 実際のコンテナ名は構成によって ke2- とプレフィックスが付くなど多少異なります。
コンテナレジストリ
KE2.0 のコンテナイメージ自体は、Azure Container Registry 上で以下の名称で公開されます。
fixpoint.azurecr.io/kompira-enterprise
イメージにはバージョン(2.0.0 など)がタグ付けされます。また、最新バージョンのイメージには latest というタグが別名として付与されます。
ネットワーク構成
公開ポート一覧
Kompira システムをセットアップしたサーバ上では、以下のポートがデフォルトで外部から接続可能になります。
| ポート番号 | 説明 |
|---|---|
| 80/TCP | HTTP |
| 443/TCP | HTTPS |
| 5671/TCP | AMQPS |
コンテナ間の連携に用いているポートは外部公開にならないため、ここでは省略しています。
ke2-docker
KE2.0 のデプロイに必要になるファイル一式をまとめた ke2-docker パッケージについて示します。
ke2-docker パッケージ
KE2.0 をデプロイするためには docker compose ファイルや各種設定ファイルなどが必要になります。 ke2-docker パッケージは、こうしたファイルのサンプルを含んでおり以下で公開しています。
https://github.com/fixpoint/ke2-docker
デプロイするサーバー上に上記リポジトリを git clone するか、あるいは ZIP ダウンロードして展開することで、KE 2.0 のデプロイができるようになります。
ke2-docker の内容
ke2-docker パッケージには以下のものが含まれます。
README.md
configs/ # 設定ファイル
ke2/ # KE2 各構成ファイル
single/ # シングル構成用のファイル一式
basic/ # - 標準シングル構成
extdb/ # - 外部DBシングル構成
cluster/ # クラスタ構成用のファイル一式
swarm/ # - Swarmクラスタ構成
cloud/ # クラウド構成用のファイル一式
azureci/ # - AzureCIクラウド構成
scripts/ # スクリプトファイル
ssl/ # SSL 証明書配置ディレクトリ
本マニュアルでは、この ke2-docker パッケージを利用した手順を説明します。 ke2-docker パッケージは KE 自体のバージョンとは独立してバージョン管理されます。基本的には最新版をご利用ください。
構築ガイド
ここでは KE2.0 の標準的なシステム構成についての概要および構築手順を示します。
標準構成一覧
| 分類 | 標準構成 | ノード構成 | データベース構成 | ファイル共有 | コンテナ管理 |
|---|---|---|---|---|---|
| シングル | 標準シングル構成 | 1台 | 内部 postgresql | docker volume | docker compose |
| 外部DBシングル構成 | 1台 | 外部 postgresql | docker volume | docker compose | |
| クラスタ | Swarmクラスタ構成 | 3台以上 | Pgpool-II | GlusterFS | docker swarm |
| クラウド | AzureCI構成 (準備中) | N/A | Azure Database | Azure Files | Azure CI |
Docker Engine のインストール
いずれの構成でも Docker を用いますので、クラウド以外ではサーバに Docker Engine のインストールが必要になります。 以下の公式サイトを参考に構築環境に合わせて Docker Engine をインストールしてください。
参考までに RHEL 環境では以下のような手順になります。
$ sudo yum install -y yum-utils
$ sudo yum-config-manager --add-repo https://download.docker.com/linux/rhel/docker-ce.repo
$ sudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
$ sudo systemctl enable --now docker
Proxy の設定
プロキシ環境下における Docker イメージのプル
Docker daemon がイメージを pull する際に、以下に示す方法によってプロキシの設定が必要となります。 (/etc/systemd/system/docker.service.d/http-proxy.conf に HTTP_PROXY, HTTPS_PROXYの設定を行う)
https://docs.docker.jp/config/daemon/systemd.html#systemd-httphttps-proxy
設定が正しくなされているかどうかは、docker info コマンドで確認することができる。
さらに、DOCKER_BUILDKIT が有効だとビルドに失敗するため、以下のようにDOCKER_BUILDKIT環境変数に 0 をセットしてビルドする。
$ DOCKER_BUILDKIT=0 docker compose -f <COMPOSE_FILE> build
プロキシ環境下におけるDocker クライアントの設定
Kompira 実行時にコンテナ内からプロキシ接続する場合、以下にあるように Docker クライアントの設定を行う必要がある。
https://docs.docker.jp/network/proxy.html#proxy-configure-the-docker-client
オンプレシングル構成
オンプレシングル構成では簡単に KE2.0 システムを構築することが出来ます。
本ガイドでは以下の構成について、その構築手順を紹介します。
標準シングル構成 (ke2/single/basic)
もっともシンプルな標準シングル構成について説明します。
以下のような場合には、この構成が便利です。
- とにかく簡単に KE2.0 環境をセットアップしたい。
- 処理負荷の分散などよりも、単純なシステム構成で使いたい。
構成図
本構成では、1 つの Docker ホストに全てのコンテナを配置して動作させます。

特徴
本構成には、以下の通り構成上の特徴があります。
- nginx, kompira, kengine, jobmngrd の各コンテナは、docker ボリューム
kompira_varをコンテナ内の/var/opt/kompiraディレクトリに共有でバインドします。静的ファイルや Python ライブラリなどを共有します。 - postgresql コンテナは、docker ボリューム
kompira_dbをコンテナ内の/var/lib/postgresql/dataディレクトリにバインドします。postgresql コンテナを新たに作成しても、当該ボリュームが残されていればデータを引き継ぐことができます。
セットアップの流れ
本構成のセットアップの流れは以下のようになります。詳細については各ページを参照してください。
サーバーの準備
オンプレ環境に KE2.0 を動作させるサーバーを準備します。
サーバーの準備
システム要件 を参考に、Linux など対応するサーバーを1台用意してください。 以後の手順ではサーバーに対する root 権限が必要になりますのでご注意ください。
Docker Engine の準備
https://docs.docker.com/engine/install/ を参考に環境に合わせて Docker Engine をインストールして、Docker を起動してください。たとえば RHEL 環境では以下のような手順になります。
$ sudo yum install -y yum-utils
$ sudo yum-config-manager --add-repo https://download.docker.com/linux/rhel/docker-ce.repo
$ sudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
$ sudo systemctl enable --now docker
KE2 のセットアップ
標準シングル構成 (ke2/single/basic) の基本的なセットアップ手順を説明します。
ke2-docker パッケージの準備
KE2.0 の構築に必要な docker compose ファイルなどを含む ke2-docker パッケージを用意してください。 ke2-docker リポジトリ から、以下のいずれかの方法でサーバー上に展開してください。
- 以下のコマンドを実行して git リポジトリをクローンしてください。(git コマンドが必要です)
$ git clone https://github.com/fixpoint/ke2-docker.git
- ZIP ファイルとしてダウンロードし、用意したサーバー上に配置して展開してください。(unzip コマンドが必要です)
ke2-docker パッケージを展開できたら、標準シングル構成用の docker-compose.yml ファイルを含むディレクトリに移動します。
$ cd ke2/single/basic
コンテナイメージの取得
以下のコマンドを実行してコンテナイメージを取得してください。
$ docker compose pull
※ インターネットに接続できない環境の場合は「オフライン環境での構築」を参考にしてください。
SSL 証明書の生成
以下のコマンドを実行して自己署名 SSL 証明書を生成してください。
$ ../../../scripts/create-cert.sh
コンテナの作成と開始
以下のコマンドを実行してコンテナを作成および開始を行なってください。
$ docker compose up -d
セットアップ後の動作確認
セットアップが完了したら、KE2.0 システムが正常に動作しているかを確認してください。 ブラウザで以下のアドレスにアクセスします。
https://<KOMPIRA_SERVER>/.login
ログイン画面が表示されるため、以下の通り入力してログインしてください。
- ユーザ名:
root - パスワード:
root
ログインが確認できたら、動作確認は完了です。
KE2 のアップデート
標準シングル構成 (ke2/single/basic) の基本的なアップデート手順を説明します。
リリースによっては特別なアップデート手順が指定される場合がありますので、アップデート作業前には必ずリリースノートを確認するようにしてください。
アップデート時のパラメータ適用について
環境変数や設定ファイルの変更は、コンテナの再作成によって反映されます (
restartしただけでは反映されません)。以下のアップデート手順は再作成を伴うため、手順どおりに実施すれば反映されます。また、リリースによっては新しい環境変数 (既定値つき) が追加されることがあります。既定値のまま利用する場合は特別な操作は不要ですが、既定値から変更している場合や独自にカスタマイズしている場合は、更新後に各構成の指定方法に従って改めて適用してください。
ke2-docker パッケージの更新
システム構築に用いた ke2-docker パッケージが改版されている場合は、基本的には事前に更新しておいてください。
- github からクローンしている場合は、
git pullコマンドで更新してください。 - ZIP ファイルから展開している場合は、改めてダウンロードしなおして展開してください。
システム構築時に docker-compose.yml ファイルや各種設定ファイルなどをカスタマイズしている場合は、更新後に改めてカスタマイズしなおしてください。
ke2-docker ディレクトリへの移動
システム構築に用いた docker-compose.yml ファイルを含むディレクトリに移動してください。
$ cd ke2/single/basic
コンテナの削除
以下のコマンドを実行してコンテナを削除してください。
$ docker compose down
このときボリュームは削除しない(-v オプションは付けない)ことに注意してください。 これによりデータベースの内容などはアップデート後も引き継がれます。
コンテナイメージの更新
以下のコマンドを実行してコンテナイメージを更新してください。
$ docker compose pull
※ インターネットに接続できない環境の場合は「オフライン環境での構築」を参考にしてください。
コンテナの作成と開始
以下のコマンドを実行してコンテナを作成および開始を行なってください。
$ docker compose up -d
外部DBシングル構成 (ke2/single/extdb)
先の標準シングル構成では 1 つの Docker ホスト上にすべてのコンテナを配置して動作させていましたが、 この外部DBシングル構成はそこからデータベースのコンテナを除外したような構成になっています。 データベースについてはコンテナ外部に別途用意して、コンテナ内部の各機能からアクセスするようにセットアップします。
以下のような場合には、この構成が便利です。
- 別環境に独自にデータベースを構築したい
- 既存のデータベースと連携した構成をとりたい
- データベース処理の負荷をオフロードしたい
構成図
本構成では、1 つの Docker ホストにデータベース以外のコンテナを配置して動作させます。

前提条件
本構成を利用するには以下のような前提条件があります。
- 外部データベースとして連携できるのは PostgreSQL 12 以上となります。
- コンテナ環境から外部データベースまでネットワーク的に直接到達できる必要があります。
- 外部データベースには、ホスト名、ポート番号、ユーザ名、パスワード、データベース名の指定だけで接続できる必要があります。
- Kompira のデータベースでは拡張モジュール pgcrypto を利用しますので、外部配置の PostgreSQL に拡張モジュールを追加する機能と権限が必要になります。
セットアップの流れ
本構成のセットアップの流れは以下のようになります。詳細については各ページを参照してください。
サーバーの準備
オンプレ環境に KE2.0 を動作させるサーバーを準備します。
サーバーの準備
システム要件 を参考に、Linux など対応するサーバーを1台用意してください。 以後の手順ではサーバーに対する root 権限が必要になりますのでご注意ください。
Docker Engine の準備
https://docs.docker.com/engine/install/ を参考に環境に合わせて Docker Engine をインストールして、Docker を起動してください。たとえば RHEL 環境では以下のような手順になります。
$ sudo yum install -y yum-utils
$ sudo yum-config-manager --add-repo https://download.docker.com/linux/rhel/docker-ce.repo
$ sudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
$ sudo systemctl enable --now docker
データベースの準備
この構成では、外部データベースとして以下の要件を満たす PostgreSQL が必要になります。
- バージョン: 12 以上
- その他: 拡張モジュール pgcrypto がインストールされていること (RHEL系 であれば、postgresql-contrib パッケージをインストールしておく必要があります)
Docker が動作しているホストサーバ、あるいは別のサーバ上に要件を満たす PostgreSQL を準備してください。
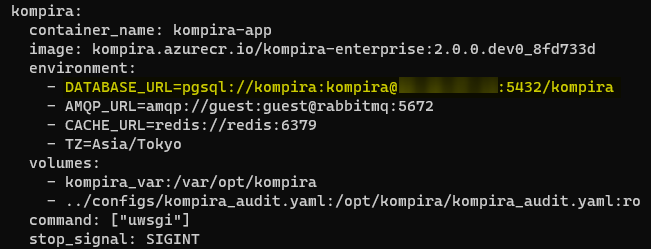
接続仕様の準備
この構成では、Docker コンテナで動作するサービスからデータベースに接続するための情報を、環境変数 DATABASE_URL で指定する必要があります。
DATABASE_URL='pgsql://<DB_USER>:<DB_PASSWORD>@<DB_HOST>:<DB_PORT>/<DB_NAME>'
注: 以下のユーザ名・パスワード・データベース名・IP アドレス・ポート番号はあくまで「設定する値の形式」を示す例示です。 任意の値を使用できますので、お使いの環境のセキュリティポリシーに合わせて設定してください。特にパスワードは推測されにくい十分に強いものを指定してください。ポート番号は PostgreSQL のデフォルト
5432を使うことが多いですが、変更している場合はそれに合わせて指定してください。
以下では具体的な手順例として、次の値で構成した場合の例を示します。
| 設定項目 | 例示値 |
|---|---|
| ユーザ名 | kompira_user |
| パスワード | <DB_PASSWORD> |
| IPアドレス | 10.20.0.10 |
| ポート番号 | 5432 |
| データベース名 | kompira_db |
このとき DATABASE_URL は以下のように指定します。
DATABASE_URL='pgsql://kompira_user:<DB_PASSWORD>@10.20.0.10:5432/kompira_db'
実際に準備した、またはこれから準備する PostgreSQL サーバの構成に合わせて、DATABASE_URL に指定する値を準備しておいてください。
ユーザ名・パスワード・DB 名に URL 安全でない文字 (
@:/%や空白等、RFC 3986 unreserved 以外の文字) を含める場合: RFC 3986 に従いパーセントエンコード (@→%40,:→%3A,/→%2F等) が必要です (パスワードに限らず、userinfo / path のいずれの部分も対象)。詳細な変換規則と例は 資格情報管理 §5 を参照してください。なお、上記コマンド例は値全体をシングルクオートで囲む形式のため、
#/ 空白 /$/!等のシェル特殊文字を含むパスワードでも安全にコピペできますが、値自体に'(シングルクオート) を含む場合は閉じてしまうため別途エスケープが必要です。対処方法は同じく 資格情報管理 §5 (シェル例で'を含む値を扱う場合) を参照。
PostgreSQL の準備
PostgreSQL のインストールについては準備する環境に合わせて、OS のマニュアルなどを参考にして実施してください。
以下では、PostgreSQL の最低限必要になる設定手順について記述しますので、用意した PostgreSQL サーバ上で実施してください。 詳細な設定方法については PostgreSQL のホームページや公式ドキュメントを参照してください。
(1) ユーザとデータベースの作成
ユーザを作成します。ここでは例として "kompira_user" という名前で作成します。パスワードの設定も求められるので、上で準備した値を入力してください。
$ sudo -i -u postgres createuser -P "kompira_user"
注: 上記の
createuserには CREATEDB 権限を付与する-dオプションを付けていません。データベース自体は次の手順でpostgresユーザから作成するため、KE2.0 の通常運用では Kompira 接続ユーザに CREATEDB 権限は不要です。テストデータベースを Django から作るなど、DB 作成権限が必要なケースのみ-dを付加してください。
上で作成したユーザをオーナーとするデータベースを作成します。ここでは例として "kompira_db" という名前で作成します。
$ sudo -i -u postgres createdb --owner="kompira_user" --encoding=utf8 "kompira_db"
(2) PostgreSQL サーバの接続設定
ローカルホスト以外からも PostgreSQL サーバに接続できるように設定します。 postgresql.conf (RHEL系標準パッケージをインストールした場合は /var/lib/pgsql/data/postgresql.conf) の listen_address を以下のように設定してください。
listen_address = '*'
(3) PostgreSQL のクライアント認証の設定
手順 (1) で作成したユーザからパスワード接続できるように、pg_hba.conf (RHEL系標準パッケージをインストールした場合は /var/lib/pgsql/data/pg_hba.conf) に host 設定を追加してください。 たとえば Docker が動作しているホストが PostgreSQL サーバと同じネットワークに配置している場合は、以下のような行を追加してください(フィールドは順に「接続種別 / データベース名 / ユーザ名 / 接続元アドレス / 認証方式」の 5 列)。
host kompira_db kompira_user samenet scram-sha-256
あるいは、Docker が異なるネットワークに配置されている場合は、"samenet" の部分を CIDR 形式などで指定するようにしてください。
host kompira_db kompira_user 10.10.0.0/16 scram-sha-256
(4) PostgreSQL の再起動
これらの設定を行なった後は、一度 postgresql サービスを再起動してください。
$ sudo systemctl restart postgresql-<PG_VERSION>
KE2 のセットアップ
外部DBシングル構成 (ke2/single/extdb) の基本的なセットアップ手順を説明します。
ke2-docker パッケージの準備
KE2.0 の構築に必要な docker compose ファイルなどを含む ke2-docker パッケージを用意してください。 ke2-docker リポジトリ から、以下のいずれかの方法でサーバー上に展開してください。
- 以下のコマンドを実行して git リポジトリをクローンしてください。(git コマンドが必要です)
$ git clone https://github.com/fixpoint/ke2-docker.git
- ZIP ファイルとしてダウンロードし、用意したサーバー上に配置して展開してください。(unzip コマンドが必要です)
ke2-docker パッケージを展開できたら、外部 DB シングル構成用の docker-compose.yml ファイルを含むディレクトリに移動します。
$ cd ke2/single/extdb
コンテナイメージの取得
以下のコマンドを実行してコンテナイメージを取得してください。
$ docker compose pull
※ インターネットに接続できない環境の場合は「オフライン環境での構築」を参考にしてください。
SSL 証明書の生成
以下のコマンドを実行して自己署名 SSL 証明書を生成してください。
$ ../../../scripts/create-cert.sh
秘密鍵ファイルの準備
データベース上でのパスワード情報などの暗号化に用いる秘密鍵をファイル .secret_key に準備します。
Kompira 用データベースを新規に構築する場合は、たとえば以下のようにして空のファイルを用意してください。
$ touch .secret_key
※ 外部データベースとして既に構築されている Kompira データベースを用いる場合は、そのデータベースにおける秘密鍵を .secret_key に書き込んでおいてください。
$ echo -n 'xxxxxxxxxxxxxxxx' > .secret_key
コンテナの作成と開始
以下のコマンドを実行してコンテナを作成および開始を行なってください。
このとき先に準備した接続情報を反映した DATABASE_URL を 必ず指定 してください。未指定で起動した場合は docker compose config の段階で即エラー停止します。
$ DATABASE_URL='pgsql://<DB_USER>:<DB_PASSWORD>@<DB_HOST>:<DB_PORT>/<DB_NAME>' docker compose up -d
DATABASE_URL に埋め込むユーザ名・パスワード・DB 名に URL 安全でない文字 (
@:/%や空白等、RFC 3986 unreserved 以外の文字) を含む場合: パーセントエンコードが必要です (パスワードに限らず、userinfo / path のいずれの部分も対象)。詳細は 資格情報管理 §5 を参照してください。なお、上記コマンド例は値全体をシングルクオートで囲む形式のため、シェル特殊文字 (
#/ 空白 /$/!等) を含むパスワードでも安全にコピペできますが、値自体に'(シングルクオート) を含む場合は閉じてしまうため別途エスケープが必要です。対処方法は同じく 資格情報管理 §5 (シェル例で'を含む値を扱う場合) を参照。
セットアップ後の動作確認
セットアップが完了したら、KE2.0 システムが正常に動作しているかを確認してください。 ブラウザで以下のアドレスにアクセスします。
https://<KOMPIRA_SERVER>/.login
ログイン画面が表示されるため、以下の通り入力してログインしてください。
- ユーザ名:
root - パスワード:
root
ログインが確認できたら、動作確認は完了です。
KE2 のアップデート
外部DBシングル構成 (ke2/single/extdb) の基本的なアップデート手順を説明します。
リリースによっては特別なアップデート手順が指定される場合がありますので、アップデート作業前には必ずリリースノートを確認するようにしてください。
アップデート時のパラメータ適用について
環境変数や設定ファイルの変更は、コンテナの再作成によって反映されます (
restartしただけでは反映されません)。以下のアップデート手順は再作成を伴うため、手順どおりに実施すれば反映されます。また、リリースによっては新しい環境変数 (既定値つき) が追加されることがあります。既定値のまま利用する場合は特別な操作は不要ですが、既定値から変更している場合や独自にカスタマイズしている場合は、更新後に各構成の指定方法に従って改めて適用してください。
ke2-docker パッケージの更新
システム構築に用いた ke2-docker パッケージが改版されている場合は、基本的には事前に更新しておいてください。
- github からクローンしている場合は、
git pullコマンドで更新してください。 - ZIP ファイルから展開している場合は、改めてダウンロードしなおして展開してください。
システム構築時に docker-compose.yml ファイルや各種設定ファイルなどをカスタマイズしている場合は、更新後に改めてカスタマイズしなおしてください。
ke2-docker ディレクトリへの移動
システム構築に用いた docker-compose.yml ファイルを含むディレクトリに移動してください。
$ cd ke2/single/extdb
コンテナの削除
以下のコマンドを実行してコンテナを削除してください。
$ docker compose down
このときボリュームは削除しない(-v オプションは付けない)ことに注意してください。 これによりデータベースの内容などはアップデート後も引き継がれます。
コンテナイメージの更新
以下のコマンドを実行してコンテナイメージを更新してください。
$ docker compose pull
※ インターネットに接続できない環境の場合は「オフライン環境での構築」を参考にしてください。
コンテナの作成と開始
以下のコマンドを実行してコンテナを作成および開始を行なってください。
$ docker compose up -d
オンプレクラスタ構成
オンプレクラスタ構成では Kompira エンジンなどのコンテナを複数のノードで動作させることで、可用性の向上やジョブフローの並列実行によるスループット向上が狙えます。
本ガイドでは以下の構成について、その構築手順を紹介します。
Swarmクラスタ構成
この Swarm クラスタ構成では、クラスタ管理に Docker Swarm を採用しており、シングル構成同様に docker compose ファイルによってクラスタ構成を定義します。
前提条件
Swarm クラスタ構成には、以下の前提条件があります。
- 同一 LAN 上に配置するホスト(Linux サーバ)が最小で3台必要になります。
- この 3台のホスト上にそれぞれ Docker Swarm のマネージャノードを起動してクラスタを構成します。
- 外部データベース構成を取る必要があります。
- 外部DBシングル構成と同様に PostgreSQL データベースを準備する必要があります。
- 各ホストでディレクトリを共通出来るように、ネットワークファイルシステムを用意する必要があります。
セットアップの流れ
ここでは、以下のようなシステム構成をセットアップする手順を紹介します。
- 3台のサーバーによる Docker Swarm クラスタ構成
- GlusterFS による共有ファイルシステム
- PostgreSQL/Pgpool-II によるクラスタ型外部データベース
上記条件での本構成のセットアップの流れは以下のようになります。詳細については各ページを参照してください。
なお、以降の説明では、ホストとして RHEL 9 系 (CentOS Stream 9、AlmaLinux 9、RockyLinux 9も含む) サーバの利用を想定しています。Ubuntu など別のディストリビューションを利用する場合は、適宜、コマンド等を読み替えてください。
コマンド実行手順表示について
本構成のセットアップ手順では、すべてのホストサーバ上でコマンドを実行する場合や、あるいは特定のホストサーバ上でだけコマンドを実行する場合などがあります。
以後の手順説明において、以下のように表示されている手順はすべてのホストサーバ上でコマンドを実行するようにしてください。とくに指定がない場合は実行順は問いません。
[全ホスト]$ command ...
以下のように表示されている手順については、[ホスト名] に記されたホストサーバ上でコマンドを実行するようにしてください。
[ホスト名]$ command ...
サーバーの準備
Docker Swarm (24.0以降) が動作する Linux サーバ 3台を準備します。
以降の構築手順では、3台のホストのホスト名と IP アドレスを以下のように想定しています。
- ke2-server1: 10.20.0.1
- ke2-server2: 10.20.0.2
- ke2-server3: 10.20.0.3
また、Pgpool-II クラスタに設定する仮想 IP アドレスとしては 10.20.0.100 を使用します。
名前解決の準備
各サーバはお互いにホスト名で名前解決できる必要があります。 DNS サーバに名前登録するか、各サーバ上の /etc/hosts に設定を追加してください。
Swarm クラスタの準備
Docker CE のインストール
Docker の公式リポジトリを追加し、Docker CE を各ホストにインストールしてください。 各ホスト上で以下のコマンドを実行します。
[全ホスト]$ sudo dnf config-manager --add-repo=https://download.docker.com/linux/centos/docker-ce.repo
[全ホスト]$ sudo dnf install docker-ce
次に、Docker サービスの有効化と起動を行います。
[全ホスト]$ sudo systemctl enable --now docker
ユーザの docker グループへの追加
現在のユーザーが sudo せずに dockerコマンドを実行できるように、現在のユーザを docker グループに所属させます。(本手順は省略してもかまいません)
[全ホスト]$ sudo usermod -aG docker $USER
なお、上記の設定を反映させるには、一度ログアウトしてから、再度ログインし直す必要があります。
ファイアウォールの設定
本構成では以下のポートを用いた通信ができるようにする必要があります。
- TCP ポートの 2377: クラスター管理における通信のため
- TCP および UDP ポートの 7946: ノード間の通信のため
- UDP ポートの 4789: オーバーレイネットワークのトラフィックのため
各ホスト上で、以下のコマンドを実行してポートを開放してください(システムによってはデフォルトで開放されている場合もあります)。
[全ホスト]$ sudo firewall-cmd --permanent --add-port=2377/tcp
[全ホスト]$ sudo firewall-cmd --permanent --add-port=7946/tcp --add-port=7946/udp
[全ホスト]$ sudo firewall-cmd --permanent --add-port=4789/udp
[全ホスト]$ sudo firewall-cmd --reload
ただし、VMWare 環境で構築する場合は、注意事項があります。
Docker Swarm クラスタの初期化
最初のマネージャノード(ここでは ke2-server1 を想定します)となる Docker ホスト上で以下を実行してください。
[ke2-server1]$ docker swarm init
ただし、VMWare 環境で構築する場合や、サーバが複数ネットワークに属する場合には、以下の注意事項があります。
VMWare 環境での注意事項
VMWare の仮想サーバでネットワークインタフェースに vmxnet3 を利用している場合、 Swarm のオーバーレイネットワークが利用する 4789 番ポートと衝突し、Swarm ノード間の TCP 通信ができない問題が報告されています。 これを回避するためには、docker swarm init に --data-path-port オプションで 4789 以外のポート番号を指定する必要があります。 合わせて、ファイアウォールの設定も、ここで指定したポートでノード間の通信を許可するように追加します。
ヒント: 利用中の NIC ドライバが vmxnet3 かどうかは、クラスタ通信に使うインタフェースに対して
ethtool -i <INTERFACE> | grep driverを実行し、driver: vmxnet3と表示されるかどうかで確認できます (インタフェース名はip -o link等で確認してください)。
標準の 4789 ポートではなく例えば 14789 ポートを利用する場合は、docker swarm init 時に以下のように --data-path-port オプションで指定してください。
[ke2-server1]$ docker swarm init --data-path-port=14789
標準ではないポートを --data-path-port に指定した場合は、そのポートでノード間通信が出来るようにファイアウォールの設定も加えて実施してください。
[全ホスト]$ sudo firewall-cmd --permanent --add-port=14789/udp
[全ホスト]$ sudo firewall-cmd --reload
複数ネットワーク環境での注意事項
サーバが複数の IP アドレスを持つような環境では、docker swarm init コマンド実行時に --advertise-addr オプションの指定を求められる場合があります。 クラスタ構成を組む(すべてのノードが属している)ネットワークの IP アドレスを --advertise-addr オプションで指定するようにしてください。
[ke2-server1]$ docker swarm init --advertise-addr=10.20.0.1
※ VMWare 環境では --data-path-port オプションも合わせて指定するようにしてください。
マネージャノードの追加
続いて、以下のコマンドを実行して、マネージャノードを追加するコマンドを取得します。
[ke2-server1]$ docker swarm join-token manager
このコマンドを実行すると、次のような表示があるはずです。
To add a manager to this swarm, run the following command:
docker swarm join \
--token <TOKEN> \
<SWARM_MANAGER_IP>:2377
ここに表示されているコマンドを次の手順で、他のホスト上で実行することになります。
マネージャノードの追加
先の手順を実行したときに表示された docker swarm join コマンドを、2つ目、3つ目の Docker ホスト上でそれぞれ実行してください。
[ke2-server{2,3}]$ docker swarm join --token <TOKEN> <SWARM_MANAGER_IP>:2377
ノード一覧の確認
任意の Docker ホスト上で以下のコマンドを実行すると、Swarmクラスタに参加しているノード一覧を表示することができます。
[ke2-server1]$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
ee5c0f5j5dt1m2x6vemrz7dxy * ke2-server1 Ready Active Reachable 25.0.4
ypqsarfbtuwrit9hekiqac03u ke2-server2 Ready Active Reachable 25.0.4
t8zhg0ez1xezj0942d7zb4u6h ke2-server3 Ready Active Leader 25.0.4
3台のノードの STATUS が Ready になっていること、いずれかのノードの MANAGER STATUS が Leader になっていることを確認してください。
GlusterFS の準備
クラスタ構成では Docker Swarm 上で動作する各ホスト上の Kompira のコンテナからアクセス可能な共有ディレクトリが必要になります。 すでに、利用可能な共有ファイルサーバがある場合は、そのサーバ上のディレクトリを Docker Swarm の各ホストからマウントして利用することもできます。
ここでは、GlusterFS 分散ファイルシステムを用いて共有ディレクトリを準備します。
GlusterFS インストールと設定
各ホスト上で以下のコマンドを実行して、GlusterFS をインストールします。
[全ホスト]$ sudo dnf install centos-release-gluster10
[全ホスト]$ sudo dnf install glusterfs-server
次に、GlusterFS サービスの有効化と起動を行います。
[全ホスト]$ sudo systemctl enable --now glusterd
ファイアウォールの設定
各ホスト上で、以下のコマンドを実行してポートを開放します。
[全ホスト]$ sudo firewall-cmd --add-service=glusterfs --permanent
[全ホスト]$ sudo firewall-cmd --reload
プールの構築
どれか1つのノードで、gluster peer probe コマンドを実行し、他のサーバをプールに追加します。
ke2-server1 上で実行する場合:
[ke2-server1]$ sudo gluster peer probe ke2-server2
[ke2-server1]$ sudo gluster peer probe ke2-server3
プールを構成するサーバの一覧は、以下のコマンドで確認することができます。
[ke2-server1]$ sudo gluster pool list
UUID Hostname State
9d593742-d630-48b0-8570-066d15822c4d ke2-server2 Connected
9b7f2c39-a0ce-498f-9939-4fcf55a36fac ke2-server3 Connected
d47ce78a-0ffd-468f-9218-32fa2d97c431 localhost Connected
GlusterFS ボリュームの作成
ボリューム gvol0 を作成してスタートします。 GlusterFS クラスタ内のどれか1つのノード上で(以下の例では ke2-server1 を想定)以下を実行します。 (ここでは root パーティションに作成しているため、force オプションが必要です)
[ke2-server1]$ sudo gluster vol create gvol0 replica 3 ke2-server1:/var/glustervol0 ke2-server2:/var/glustervol0 ke2-server3:/var/glustervol0 force
[ke2-server1]$ sudo gluster vol start gvol0
ボリュームの マウント
作成した gvol0 ボリュームを各ノード上でマウントします。
[全ホスト]$ sudo mkdir /mnt/gluster
[全ホスト]$ sudo mount -t glusterfs localhost:/gvol0 /mnt/gluster
再起動時に自動的にマウントされるように以下を /etc/fstab に追加しておきます。
localhost:/gvol0 /mnt/gluster glusterfs _netdev,defaults 0 0
Pgpool-II の準備
各 Swarm ノード上で実行している Kompira エンジンや Kompira アプリケーションサーバのコンテナからアクセス可能なデータベースとして、 PostgreSQL/Pgpool-II クラスタを構築する手順について説明します。
Pgpool-II を用いたデータベースクラスタには最低で 3台 のホストが必要となります。
ここでは、Docker Swarm クラスタのホスト上にデータベースクラスタを同居した形で構築していますが、Docker Swarm クラスタとは別にデータベースクラスタを構築しても構いません。
PostgreSQL/Pgpool-II のセットアップ
ここでは、ke2-docker パッケージに附属するセットアップ用のスクリプトを用いて構築する手順を示します。このスクリプトは RHEL 9系 (CentOS Stream 9、Rocky Linux 9、AlmaLinux 9など互換 OS を含む) のサーバを対象としています。その他の OS 上にセットアップする場合は、スクリプトの内容を参考にして構築してください。
なお、本セットアップスクリプトでは、PostgreSQL/Pgpool-II の各ユーザとパスワードをデフォルトで以下のように設定します。
| ユーザ名 | パスワード | 備考 |
|---|---|---|
kompira | kompira | Kompiraアクセス用のユーザ |
pgpool | pgpool | Pgpool-IIでの以下用途の専用ユーザ レプリケーション遅延チェック(sr_check_user) ヘルスチェック(health_check_user) |
postgres | postgres | オンラインリカバリの実行ユーザ |
repl | repl | PostgreSQLのレプリケーション専用ユーザ |
重要: 上記のユーザ名・パスワードは setup_pgpool.sh のデフォルト値(検証・初期構築向けの弱いパスワード)です。本番運用では必ず独自の強いパスワードに変更してください。
強いパスワードを設定する方法は 2 通りあります。構築後の同期作業が不要でミスが起きにくいため、初期構築時に指定する方法を推奨します。
- 推奨: 初期構築時に指定する — setup_pgpool.sh の実行時に環境変数
PG_KOMPIRA_PASS/PG_POOL_PASS/PG_PASS/PG_REPL_PASSで各ユーザのパスワードを指定すると、その値で初期化されます(次の (2) を参照)。- 構築後に変更する — すでにデフォルト値で構築してしまった場合は、資格情報管理 §4.3 の手順で変更します。この場合、PostgreSQL 側だけでなく Pgpool-II の
pool_passwdを全ノードで同期する必要があります。
(1) 各ホストへのスクリプトファイル転送
ke2-docker パッケージの ke2/cluster/swarm ディレクトリに含まれる以下のスクリプトファイルを、クラスタを構成する各ホストに転送してください。
- setup_pgpool.sh
- setup_pgssh.sh
(2) PostgreSQL/Pgpool-II のインストール
各ホストで setup_pgpool.sh スクリプトを実行します。このスクリプトでは、PostgreSQL 16、および、Pgpool-II のインストールと初期設定を行います。setup_pgpool.sh 起動時には以下の環境変数を指定する必要があります。
CLUSTER_VIP: Pgpool-II で使用する仮想IPアドレスCLUSTER_HOSTS: クラスタを構成するホスト名(空白区切り)。各ホストのhostnameコマンドの出力と一致させてください(FQDN で運用している場合は FQDN を指定します)。
CLUSTER_HOSTS の最初のホストを「プライマリサーバ」として、残りのホストを「セカンダリサーバ」としてセットアップします。また CLUSTER_HOSTS の順番に Pgpool-II 上でのノード ID を 0, 1, 2,... と割り当てます。したがって、各ホスト上で setup_pgpool.sh を実行する際に、CLUSTER_HOSTS のホスト順序は同一にする必要があることに注意してください。
さらに、本番運用では以下の環境変数で各ユーザの初期パスワードを指定してください(省略すると前掲のデフォルトの弱いパスワードになります)。
PG_KOMPIRA_PASS:kompiraユーザのパスワードPG_POOL_PASS:pgpoolユーザのパスワードPG_PASS:postgresユーザのパスワードPG_REPL_PASS:replユーザのパスワード
注意: これらのパスワードは全ホストで同一の値を指定してください。 プライマリサーバが指定値でユーザを作成し、各ホストは自身に指定された値で Pgpool-II の認証情報 (
pool_passwd) を生成するため、ホスト間で値が異なると認証に失敗します。
以下に実行例を示します(デフォルトの弱いパスワードのままセットアップする例)。
[全ホスト]$ CLUSTER_VIP=10.20.0.100 CLUSTER_HOSTS='ke2-server1 ke2-server2 ke2-server3' ./setup_pgpool.sh
本番運用向けに、初期パスワードを指定してセットアップする例を以下に示します(<...> は実際の強いパスワードに置き換え、全ホストで同じ値を指定してください)。
[全ホスト]$ CLUSTER_VIP=10.20.0.100 CLUSTER_HOSTS='ke2-server1 ke2-server2 ke2-server3' \
PG_KOMPIRA_PASS='<KOMPIRA_PASSWORD>' PG_POOL_PASS='<PGPOOL_PASSWORD>' \
PG_PASS='<POSTGRES_PASSWORD>' PG_REPL_PASS='<REPL_PASSWORD>' \
./setup_pgpool.sh
一般ユーザで実行する場合、起動後に sudo のパスワードの入力を求められます。
(3) Pgpool-II 用の SSH 接続設定
各ホストで setup_pgssh.sh スクリプトを実行します。このスクリプトでは Pgpool-II の自動フェイルオーバおよびオンラインリカバリ機能を利用するため、各ノード間で postgres ユーザが公開鍵認証で SSH 接続できるように設定します。 先ほどの手順と同様に CLUSTER_HOSTS 環境変数を指定して setup_pgssh.sh スクリプトを実行してください。
[全ホスト]$ CLUSTER_HOSTS='ke2-server1 ke2-server2 ke2-server3' ./setup_pgssh.sh
setup_pgssh.sh は postgres ユーザの SSH 鍵ファイルを作成し、公開鍵ファイルを CLUSTER_HOSTS で指定された各ホストの ~postgres/.ssh/authorized_keys に追加することで、パスワード無しで SSH 接続できるようにします。 一般ユーザで実行する場合、起動後に sudo のパスワードを入力、および、実行ユーザがクラスタを構成する各リモートホストにログインするためのパスワードとリモートホストでの sudo パスワードの入力を求められます。
パスワード入力を間違えるなどで公開鍵の転送に失敗していると、Pgpool-II が正常に機能しなくなるので注意してください。
前提: setup_pgssh.sh を実行するユーザは、CLUSTER_HOSTS に指定した全ホストへ SSH ログインでき、かつ各ホストで sudo できる必要があります。 上記の対話パスワード入力は、実行ユーザが各ホストへログインできることが前提です。SSH ログインできないホストがあると公開鍵を配布できず、Pgpool-II が正常に機能しません。事前に全ホスト間で実行ユーザの SSH ログインが可能なことを確認しておいてください。
Pgpool-II の起動とオンラインリカバリ
ここでは、Pgpool-II を起動して PostgreSQL のクラスタ構成を行ないます。
(1) Pgpool-II の起動
プライマリサーバ(ここでは ke2-server1 を想定)から順番に、各ホスト上で以下のコマンドを実行して Pgpool-II を起動してください。
[全ホスト]$ sudo systemctl start pgpool
注意: Pgpool-II の起動直後は、watchdog による仮想IP (VIP) の割り当てに数秒程度かかることがあります。 起動直後に VIP 経由の接続(次の手順の
psql -h $CLUSTER_VIPなど)を行うと "No route to host" 等で失敗する場合があります。その場合は数秒待ってから再度実行してください。
(2) プライマリサーバの状態確認
プライマリサーバでは setup_pgpool.sh の実行によって、既に PostgreSQL サーバが起動しています。 いずれかのホスト上で以下のコマンドを実行して、プライマリサーバで PostgreSQL がプライマリモードで動作していることを確認してください。
[任意のホスト]$ psql -h $CLUSTER_VIP -p 9999 -U pgpool postgres -c "show pool_nodes"
$CLUSTER_VIP の部分は Pgpool-II で使用する仮想IPアドレスに置き換えるか、シェル変数 CLUSTER_VIP
としてそのアドレスを設定しておいてください。下記の例では、プライマリサーバである ke2-server1 で PostgreSQL
がプライマリモードで起動しており(pg_status が "up"、pg_role が "primary")、ke2-server2 と ke2-server3
では PostgreSQL がまだ起動していないこと(pg_status が "down")が分かります。
[ke2-server1]$ psql -h 10.20.0.100 -p 9999 -U pgpool postgres -c "show pool_nodes"
ユーザー pgpool のパスワード:
node_id | hostname | port | status | pg_status | lb_weight | role | pg_role | select_cnt | load_balance_node | replication_delay | replication_state | replication_sync_state | last_status_change
---------+-------------+------+--------+-----------+-----------+---------+---------+------------+-------------------+-------------------+-------------------+------------------------+---------------------
0 | ke2-server1 | 5432 | up | up | 0.333333 | primary | primary | 0 | true | 0 | | | 2024-06-11 18:18:20
1 | ke2-server2 | 5432 | down | down | 0.333333 | standby | unknown | 0 | false | 0 | | | 2024-06-11 18:16:06
2 | ke2-server3 | 5432 | down | down | 0.333333 | standby | unknown | 0 | false | 0 | | | 2024-06-11 18:16:06
(3 行)
(3) スタンバイサーバのオンラインリカバリ
Pgpool-II のオンラインリカバリ機能を利用し、ke2-server2 と ke2-server3 をスタンバイサーバとして起動させて、Pgpool-II 管理下に追加します。
オンラインリカバリさせるには、以下のように pcp_recovery_node コマンドを実行してください。
[任意のホスト]$ pcp_recovery_node -h $CLUSTER_VIP -p 9898 -U pgpool -n <NODE_ID> -W
<NODE_ID> の部分はオンラインリカバリさせるノード ID に置き換えてください。上で確認したとおり ke2-server1 がノードID 0
でプライマリサーバとして動作していますので、ここではノード ID に 1 および 2 を指定して ke2-server2 と ke2-server3
をオンラインリカバリさせています。
[ke2-server1]$ pcp_recovery_node -h 10.20.0.100 -p 9898 -U pgpool -n 1 -W
Password:
pcp_recovery_node -- Command Successful
[ke2-server1]$ pcp_recovery_node -h 10.20.0.100 -p 9898 -U pgpool -n 2 -W
Password:
pcp_recovery_node -- Command Successful
(4) スタンバイサーバの状態確認
オンラインリカバリによって PostgreSQL のスタンバイサーバが起動していることを、再び以下のコマンドで確認してください。
[任意のホスト]$ psql -h $CLUSTER_VIP -p 9999 -U pgpool postgres -c "show pool_nodes"
以下の例では、ke2-server2 と ke2-server3 で PostgreSQL がスタンバイサーバとして起動していること(pg_status が "up"、pg_role が "standby")が分かります。
[ke2-server1]$ psql -h 10.20.0.100 -p 9999 -U pgpool postgres -c "show pool_nodes"
ユーザー pgpool のパスワード:
node_id | hostname | port | status | pg_status | lb_weight | role | pg_role | select_cnt | load_balance_node | replication_delay | replication_state | replication_sync_state | last_status_change
---------+-------------+------+--------+-----------+-----------+---------+---------+------------+-------------------+-------------------+-------------------+------------------------+---------------------
0 | ke2-server1 | 5432 | up | up | 0.333333 | primary | primary | 0 | false | 0 | | | 2024-06-11 18:18:20
1 | ke2-server2 | 5432 | up | up | 0.333333 | standby | standby | 0 | true | 0 | streaming | async | 2024-06-11 18:22:54
2 | ke2-server3 | 5432 | up | up | 0.333333 | standby | standby | 0 | false | 0 | streaming | async | 2024-06-11 18:22:54
(3 行)
セットアップ手順
Swarm クラスタ構成 (ke2/cluster/swarm) の基本的なセットアップ手順を説明します。
本ページの手順は Docker Swarm クラスタを構成するいずれかのマネージャノード上で実行してください。
デプロイの準備
クラスタ構成の KE2.0 を開始するための準備を行ないます。 ke2-docker パッケージの、Swarm クラスタ構成用のディレクトリに移動します。
[ke2-server1]$ cd ke2/cluster/swarm
コンテナイメージの取得
以下のコマンドを実行してコンテナイメージを取得してください。
[ke2-server1]$ docker compose pull
※ インターネットに接続できない環境の場合は「オフライン環境での構築」を参考にしてください。
SSL 証明書の生成
以下のコマンドを実行して自己署名 SSL 証明書を生成してください。
[ke2-server1]$ ../../../scripts/create-cert.sh
共有ディレクトリの作成
ネットワークファイルシステム上に共有ディレクトリ (SHARED_DIR) と以下に示すサブディレクトリを作成してください。
- ${SHARED_DIR}/
- log/
- var/
- ssl/
SHARED_DIR を /mnt/gluster とする場合は、例えば以下のようにディレクトリを作成できます。
[ke2-server1]$ mkdir -p /mnt/gluster/{log,var,ssl}
注意: これらのサブディレクトリ (
log/var/ssl) は、後述のsetup_stack.shを実行するユーザが書き込みできる必要があります。setup_stack.shは各ディレクトリの書き込み可否を確認し、sslには SSL 証明書をコピーします。共有ファイルシステムのマウント先が root 所有になっているなどで一般ユーザが作成・書き込みできない場合は、sudoで作成したうえで実行ユーザが書き込めるよう所有者・パーミッションを調整してください(例:sudo chown "$USER" /mnt/gluster/{log,var,ssl})。
秘密鍵ファイルの準備
データベース上でのパスワード情報などの暗号化に用いる秘密鍵をファイル ${SHARED_DIR}/var/.secret_key に準備します。
Kompira 用データベースを新規に構築する場合は、たとえば以下のようにして空のファイルを用意してください。
[ke2-server1]$ touch /mnt/gluster/var/.secret_key
※ 外部データベースとして既に構築されている Kompira データベースを用いる場合は、そのデータベースにおける秘密鍵を ${SHARED_DIR}/var/.secret_key に書き込んでおいてください。
[ke2-server1]$ echo -n 'xxxxxxxxxxxxxxxx' > .secret_key
docker-swarm.yml の生成
docker-swarm.yml を生成するために、以下のコマンドを実行してください。 このとき少なくとも環境変数 SHARED_DIR で共有ディレクトリを指定するようにしてください。
[ke2-server1]$ SHARED_DIR=/mnt/gluster ./setup_stack.sh
Swarm クラスタの開始
エラーが無ければ docker-swarm.yml というファイルが生成されているはずです。 これでシステムを開始する準備ができました。以下のコマンドを実行して Kompira Enterprise 開始をします。
[ke2-server1]$ docker stack deploy -c docker-swarm.yml ke2
正常に動作しない場合は、以下のコマンドでクラスタを停止させて、設定を見直してみてください。
[ke2-server1]$ docker stack rm ke2
セットアップ後の動作確認
セットアップが完了したら、KE2.0 システムが正常に動作しているかを確認してください。 ブラウザで以下のアドレスにアクセスします。
https://<KOMPIRA_SERVER>/.login
ログイン画面が表示されるため、以下の通り入力してログインしてください。
- ユーザ名:
root - パスワード:
root
ログインが確認できたら、動作確認は完了です。
カスタマイズ
環境変数によるカスタマイズ
setup_stack.sh を実行するときに環境変数を指定することで、簡易的なカスタマイズを行なうことができます。
[ke2-server1]$ 環境変数=値... ./setup_stack.sh
| 環境変数 | 備考 |
|---|---|
SHARED_DIR | 共有ディレクトリ(各ノードからアクセスできる必要があります) |
DATABASE_URL | 外部データベースの接続 URL(未指定の場合はホスト上に外部データベースがある想定の設定になります) |
AMQP_USER | 内部 RabbitMQ コンテナのユーザ名(デフォルト: guest) |
AMQP_PASSWORD | 内部 RabbitMQ コンテナのパスワード(デフォルト: guest、本番運用前に変更を強く推奨) |
AMQP_URL | RabbitMQ 接続 URL を直接指定(指定した場合は AMQP_USER / AMQP_PASSWORD より優先。URL 安全でない文字を含む場合はパーセントエンコードして指定) |
KOMPIRA_LOG_DIR | ログファイルの出力先ディレクトリ(未指定の場合は ${SHARED_DIR}/log に出力されます) |
カスタマイズ例:
[ke2-server1]$ DATABASE_URL='pgsql://<DB_USER>:<DB_PASSWORD>@10.20.0.100:9999/<DB_NAME>' SHARED_DIR=/mnt/gluster ./setup_stack.sh
パスワードやユーザ名に URL 安全でない文字 (
@:/%等) を含める場合の注意: 個別変数AMQP_USER/AMQP_PASSWORDには RFC 3986 の unreserved set(英数字と-_.~)のみを使用してください。URL 安全でない文字が必要な場合は、パーセントエンコード済みのAMQP_URL/DATABASE_URLを直接指定します。詳細な規則・例、および AMQP でこれを行う場合に必要な KE2.0 コンテナイメージ v2.0.5.post2 以降 の要件は 資格情報管理 §5 を参照してください。
注意:
AMQP_USER/AMQP_PASSWORDは内部 RabbitMQ コンテナの初期化時(データボリュームが空の初回起動時)にのみ反映されます。 これは RabbitMQ 公式イメージの仕様で、既存のボリュームが残ったまま値だけを変更しても RabbitMQ 内のユーザは更新されません。初回構築時に指定するか、変更する場合は 資格情報管理 §4.4 の手順で RabbitMQ 側のユーザも更新してください。
詳細なカスタマイズ
コンテナ構成などを詳細にカスタマイズしたい場合は、setup_stack.sh スクリプトで生成された docker-swarm.yml ファイルを、目的に合わせてカスタマイズしてください。
アップデート手順
Swarm クラスタ構成 (ke2/cluster/swarm) の基本的なアップデート手順を示します。
リリースによっては特別なアップデート手順が指定される場合がありますので、アップデート作業前には必ずリリースノートを確認するようにしてください。
アップデート時のパラメータ適用について
環境変数や設定ファイルの変更は、コンテナの再作成によって反映されます (
restartしただけでは反映されません)。以下のアップデート手順は再作成を伴うため、手順どおりに実施すれば反映されます。また、リリースによっては新しい環境変数 (既定値つき) が追加されることがあります。既定値のまま利用する場合は特別な操作は不要ですが、既定値から変更している場合や独自にカスタマイズしている場合は、更新後に各構成の指定方法に従って改めて適用してください。
ここでは GlusterFS や Pgpool-II/PostgreSQL のアップデートについては対象外としています。
注意事項
クラスタ構成を部分的に順次アップデートしていくローリングアップデートには対応していません。 システム全体を停止させてアップデートを行なう手順をとるため、アップデート作業中はサービス停止状態になりますのでご注意ください。
また、実行中のジョブフロープロセスが存在すると強制的に異常終了となります。 可能であれば、すべてのジョブフロープロセスを適切に停止させてから、アップデート手順を実施することをお勧めします。
クラスタシステムの削除
Swarm クラスタのいずれかのマネージャーノード上(以下の例では ke2-server1)で、docker stack rm ke2 コマンドを実行してください。
[ke2-server1]$ docker stack rm ke2
Removing service ke2_jobmngrd
Removing service ke2_kengine
Removing service ke2_kompira
Removing service ke2_nginx
Removing service ke2_rabbitmq
Removing service ke2_redis
Removing config swarm_rabbitmq-config-cluster
Removing config swarm_kompira-config
Removing config swarm_rabbitmq-config-auth
Removing config swarm_kompira-audit
Removing config swarm_rabbitmq-config-ssl
Removing config swarm_bootstrap-rabbitmq
Removing config swarm_nginx-config
Removing network swarm_default
このコマンドを実行すると、クラスタで動作している全てのコンテナが停止して、クラスタスタックと構成サービスの定義などが削除されます。
この時点で、ノードの再起動や docker サービスの再起動を行なっても Kompira サービスは起動しない状態になっています。そのため以後の手順に進む前に、GlusterFS や Pgpool-II/PostgreSQL など Kompira 以外のミドルウェアのアップデートを実施することも可能です。ただし、その場合は、次の手順に進む前に、手を加えたシステム・ミドルウェアなどが再び正常に動作していることを確認するようにしてください。
ke2-docker パッケージの更新
システム構築に用いた ke2-docker パッケージが改版されている場合は、基本的には事前に更新しておいてください。
- github からクローンしている場合は、
git pullコマンドで更新してください。 - ZIP ファイルから展開している場合は、改めてダウンロードしなおして展開してください。
システム構築時に docker-compose.yml ファイルや各種設定ファイルなどをカスタマイズしている場合は、更新後に改めてカスタマイズしなおしてください。
ke2-docker ディレクトリへの移動
システム構築に用いた docker-compose.yml ファイルを含むディレクトリに移動してください。
[ke2-server1]$ cd ke2/cluster/swarm
クラスタ構成の再セットアップ
ke2-docker パッケージにアップデート/変更点がなかった場合は、この手順はスキップすることができます。
注意: ke2-docker に変更があるリリース、特に
configs/配下の設定ファイルや各サービス定義 (ke2/services/*.yml) が変わるリリースでは、この再セットアップ (setup_stack.shの再実行によるdocker-swarm.ymlの再生成) を必ず実施してください。以前生成した古いdocker-swarm.ymlのまま Swarm クラスタを開始すると、環境変数の不整合により、一部のコンテナが正しく起動しない、または変更した設定が反映されないことがあります。
ke2-docker にアップデートがある場合、セットアップ手順 を注意深く確認してください。
- セットアップ手順の「Swarm クラスタの開始」の一つ手前の手順までを、必要に応じて実施してください。
- すでに同じ内容で実施済みの手順についてはスキップすることができます。
- 例えば「共有ディレクトリの作成」という手順の場合、作成すべきディレクトリ構成が同じであり、すでに作成済みであればスキップできます。
- ただし「アップデート時の注意点」といった記述がある場合は、それに従ってください。
setup_stack.sh はその時点の環境変数から docker-swarm.yml を生成します。そのため、初回構築や前回までのアップデートで指定していた環境変数 (DATABASE_URL、資格情報・チューニング系など) を、今回も指定してください。 指定を省くと、再生成される docker-swarm.yml がそれらの既定値に戻り、接続先・資格情報・チューニング設定が意図せず変わることがあります。
※ docker-swarm.yml を生成しなおしていてカスタマイズが必要な場合は、この段階で改めてカスタマイズを適用してください。
Swarm クラスタの開始
以前生成した/または新たに生成した docker-swarm.yml ファイルを指定して、Swarm クラスタを開始してください。
[ke2-server1]$ docker stack deploy -c docker-swarm.yml ke2
問題なければ、アップデートした Kompira が起動しているはずです。
クラウド構成
クラウド構成の構築ガイドについては準備中です。
外部連携構成
いずれかの構成でセットアップした KE2.0 システムの外部に、ジョブマネージャを単体で配置したり、kompira_sendevt をインストールしてメッセージ送信に利用したい場合があります。ここでは、こうした外部連携の構成について説明します。
KE2.0 側での準備
外部にジョブマネージャや kompira_sendevt を配置して、KE2.0 システムと連携させたい場合、KE2.0 システム側で以下の準備が事前に必要になります。
- AMQPS 接続を許可するファイヤーウォールの設定
- rabbitmq に外部接続用のユーザの追加とパーミッションの設定
AMQPS の接続許可
まず OS ごとの手順で AMQPS (5671番ポート) の許可設定を行なってください。firewall-cmd を使う場合の例は以下のようになります。KE2.0 がクラスタ構成の場合は全てのノードで許可設定を行なってください。
$ sudo firewall-cmd --add-service=amqps --permanent
$ sudo firewall-cmd --reload
rabbitmq へのユーザ追加
続けて rabbitmq に外部から接続するためのユーザーを追加し、パーミッションを設定してください。
$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl add_user '<AMQP_USER>' '<AMQP_PASSWORD>'
$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl set_permissions --vhost / '<AMQP_USER>' '.*' '.*' '.*'
注: 上記のユーザ名・パスワードはあくまで「設定する値の形式」を示す例示です。任意の値を使用できますので、お使いの環境のセキュリティポリシーに合わせて設定してください。特にパスワードは推測されにくい十分に強いものを指定してください。
具体例として、ユーザ名を kompira_mq で設定する場合は以下のようになります。
$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl add_user kompira_mq '<AMQP_PASSWORD>'
$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl set_permissions --vhost / kompira_mq '.*' '.*' '.*'
ここで設定したユーザ名・パスワードは、外部 jobmngrd や kompira_sendevt 側で AMQP_URL に埋め込んで接続に使用します。ユーザ名・パスワードのいずれかに URL 安全でない文字を含むケースの取り扱いについては 資格情報管理 §5 を参照してください。
注: 上記コマンド例は値をシングルクオートで囲む形式のため、シェル特殊文字 (
#/ 空白 /$/!等) を含むパスワードでも安全にコピペできますが、値自体に'(シングルクオート) を含む場合は閉じてしまうため別途エスケープが必要です。対処方法は同じく 資格情報管理 §5 (シェル例で'を含む値を扱う場合) を参照。
外部 jobmngrd 構成
サーバ上でジョブマネージャだけをコンテナで動作させる構成について示します。
外部 jobmngrd の動作環境
動作環境の要件については KE2.0 本体と同様ですが、リソース要件については以下のように緩和します。
| 項目 | 必須 | 推奨 | 備考 |
|---|---|---|---|
| メモリ | 4GB 以上 | 8GB 以上 | |
| ディスク | 16GB 以上 | 64GB 以上 | |
| CPU コア数 | 1 コア以上 | ||
| Docker Version | version 24.0 以上 |
コンテナとして動作させるため、ホストサーバ上に事前に Docker のインストールは行なっておいてください。
外部 jobmngrd のセットアップ
外部 jobmngrd 構成をセットアップする手順について説明します。
KE2.0 システム側の事前準備については、KE2.0 側での準備 を参考に実施しておいてください。
ke2-docker パッケージの準備
KE2.0 の構築に必要な docker compose ファイルなどを含む ke2-docker パッケージを用意してください。 ke2-docker リポジトリ から、以下のいずれかの方法でサーバー上に展開してください。
- 以下のコマンドを実行して git リポジトリをクローンしてください。(git コマンドが必要です)
$ git clone https://github.com/fixpoint/ke2-docker.git
- ZIP ファイルとしてダウンロードし、用意したサーバー上に配置して展開してください。(unzip コマンドが必要です)
ke2-docker パッケージを展開できたら、外部 jobmngrd 構成用の docker-compose.yml ファイルを含むディレクトリに移動します。
$ cd ke2/extra/jobmngrd
コンテナイメージの取得
以下のコマンドを実行してコンテナイメージを取得してください。
$ docker compose pull
※ インターネットに接続できない環境の場合は「オフライン環境での構築」を参考にしてください。
コンテナの作成と開始
以下のコマンドを実行してコンテナを作成および開始を行なってください。
$ AMQP_URL=... docker compose up -d
このとき KE2.0 が動作しているシステムの rabbitmq に接続できるように、rabbitmq に追加したユーザやパスワードに合わせて AMQP_URL を指定してください(ユーザ名・パスワードは KE2.0 側で rabbitmqctl add_user で追加した値を使用します)。
$ AMQP_URL='amqps://<AMQP_USER>:<AMQP_PASSWORD>@<RABBITMQ_HOST>:5671' docker compose up -d
AMQP_URL に埋め込むユーザ名・パスワードに URL 安全でない文字 (
@:/%や空白等、RFC 3986 unreserved 以外の文字) を含む場合: RFC 3986 に従いパーセントエンコード (@→%40,:→%3A,/→%2F等) が必要です (パスワードに限らず userinfo 全体が対象)。詳細な変換規則と例は 資格情報管理 §5 を参照。なお、AMQP_URL の userinfo (ユーザ名・パスワード) に URL 安全でない文字を含む場合、KE2.0 コンテナイメージは v2.0.5.post2 以降が必要です。コンテナイメージのバージョン指定方法はKOMPIRA_IMAGE_NAME/KOMPIRA_IMAGE_TAGを、変更後の反映にはdocker compose pullの再実行が必要なことを併せて確認してください。また、上記コマンド例は AMQP_URL 全体をシングルクオートで囲む形式のため、シェル特殊文字 (
#/ 空白 /$/!等) を含むパスワードでも安全にコピペできますが、値自体に'(シングルクオート) を含む場合は閉じてしまうため別途エスケープが必要です。対処方法は同じく 資格情報管理 §5 (シェル例で'を含む値を扱う場合) を参照。
セットアップ後の動作確認
ブラウザで KE2.0 の「管理領域設定 > デフォルト」 (/config/realms/default) を確認して、「ジョブマネージャ状態」一覧にこのホストがステータス「動作中」として表示されていれば、外部 jobmngrd 構成のセットアップは成功です。
外部 kompira_sendevt
KE2.0 に対して外部からメッセージを送信するために、kompira_sendevt を使う方法について説明します。
Kompira-sendevt パッケージ
kompira_sendevt コマンドを含む Python パッケージ Kompira-sendevt は pypi.org で公開しています。
https://pypi.org/project/Kompira-sendevt/
なお、kompira_sendevt 専用の Docker イメージを配布する予定はありません。
Python のインストール
Python パッケージ Kompira-sendevt をインストールするには、インストール先に Python 自体がインストールされている必要があります。
そのため、まずはインストール先のサーバに Python をインストールしておいてください。Python のインストール方法については Python の公式ページを参照してください。
Python の対応バージョンは 3.8 以上とします。
外部 kompira_sendevt のインストール
Linux 環境へのインストール
Kompira-sendevt 用の独立した Python 仮想環境 (venv) を作成します。
ここでは /opt/kompira に作成する前提で説明します。
$ python -m venv /opt/kompira
ログファイルの出力先としてディレクトリ /var/log/kompira を作成します。
$ mkdir -p /var/log/kompira
pip コマンドで Kompira-sendevt パッケージをインストールしてください。
$ /opt/kompira/bin/pip install Kompira-sendevt~=2.0
kompira_sendevt コマンドは /opt/kompira/bin にインストールされますので、
次のように kompira_sendevt コマンドを実行してみてください。
$ /opt/kompira/bin/kompira_sendevt --version
kompira_sendevt (Kompira version 2.0.0)
正しくインストールされていれば、バージョン番号が出力されます。
Windows 環境へのインストール
Kompira-sendevt 用の独立した Python 仮想環境 (venv) を作成します。
ここでは C:\Kompira に作成する前提で説明します。
C:\> python -m venv C:\Kompira
ログファイルの出力先としてディレクトリ C:\Kompira\Log を作成します。
C:\> mkdir C:\Kompira\Log
pip コマンドで Kompira-sendevt パッケージをインストールしてください。
C:\> C:\Kompira\Scripts\pip.exe install Kompira-sendevt~=2.0
kompira_sendevt コマンドは C:\Kompira\Scripts にインストールされますので、
次のように kompira_sendevt コマンドを実行してみてください。
C:\> C:\Kompira\Scripts\kompira_sendevt.exe --version
kompira_sendevt (Kompira version 2.0.0)
正しくインストールされていれば、バージョン番号が出力されます。
オフライン環境での構築
インターネットに接続できない環境で KE2.0 をセットアップする必要がある場合、次のような手順が必要になります。
- オンライン環境でコンテナイメージを pull してファイルにセーブする
- オフライン環境のサーバにセーブファイルを転送してロードする
コンテナイメージのセーブ
オンライン環境で ke2-docker パッケージのいずれかの構成のディレクトリで、docker compose pull を実行してコンテナイメージを取得してください。
$ docker compose pull
docker images コマンドでいくつかのイメージが存在していることを確認してください。
$ docker images
docker save コマンドでコンテナイメージをセーブしてください。ファイルサイズが大きくなるのでここでは gzip で圧縮しています。
$ docker save $(docker images --format "{{.Repository}}") | gzip > ke2-docker-images.gz
このときコマンドを実行した docker 環境に存在する全てのコンテナイメージがセーブされます。 不要なコンテナイメージが含まれている場合は不要なイメージを削除してから実行するか、 docker save コマンドのオプションに必要なコンテナイメージだけを指定するようにしてください。
$ docker save kompira.azurecr.io/kompira-enterprise registry.hub.docker.com/library/{rabbitmq,postgres,redis,nginx} | gzip > ke2-docker-images.gz
イメージファイルの転送
インストール先となるオフライン環境のサーバに、上でセーブした ke2-docker-images.gz ファイルを転送してください。
コンテナイメージのロード
ke2-docker-images.gz ファイルを転送したサーバ上で docker load コマンドを実行して、コンテナイメージをロードしてください。
$ zcat ke2-docker-images.gz | docker load
docker images コマンドでいくつかのイメージが存在していることを確認してください。
$ docker images
この環境で各構成のセットアップ手順を実施するとき、docker compose pull 手順はスキップできるようになります。
設定ガイド
ここに設定ガイドを書きます。
システム設定
環境変数
デプロイ時に環境変数を設定しておくことで、Kompira の動作環境を指定することが出来ます。 以下では各構成で共通的な環境変数について示します。 各構成で独自の環境変数が定義されている場合もありますので、それぞれの説明を参照してください。
| 環境変数名 | デフォルト | 意味 |
|---|---|---|
HOSTNAME | (下記参照) | ホスト名 |
KOMPIRA_IMAGE_NAME | "kompira.azurecr.io/kompira-enterprise" | Kompira イメージ |
KOMPIRA_IMAGE_TAG | (下記参照) | Kompira タグ |
DATABASE_URL | "pgsql://kompira@//var/run/postgresql/kompira" | データベースの接続先 |
AMQP_URL | "amqp://guest:guest@localhost:5672" | メッセージキューの接続先 |
CACHE_URL | "redis://localhost:6379" | キャッシュの接続先 |
TZ | "Asia/Tokyo" | タイムゾーン |
LANGUAGE_CODE | "ja" | 言語設定 |
MAX_EXECUTOR_NUM | "0" | Executor の最大数 |
KOMPIRA_LOG_DIR | (下記参照) | ログ保存先 (ホスト側) |
LOGGING_XXX | (下記参照) | プロセスログの設定 |
AUDIT_LOGGING_XXX | (下記参照) | 監査ログの設定 |
UWSGI_XXX | (下記参照) | Web ワーカの並列度・タイムアウト |
KOMPIRA_NGINX_UWSGI_READ_TIMEOUT | "300" | nginx→uWSGI の read タイムアウト (秒) |
KOMPIRA_NGINX_UWSGI_SEND_TIMEOUT | "300" | nginx→uWSGI の send タイムアウト (秒) |
POSTGRES_XXX | (下記参照) | PostgreSQL のチューニング |
HOSTNAME
デプロイする各コンテナには、ホストサーバのホスト名をベースにしたホスト名を内部的に付与するようにしています。
そのため、デプロイ時にホストサーバのホスト名を環境変数 HOSTNAME で参照しています。
環境変数 HOSTNAME でホストサーバのホスト名を参照できない環境の場合は、デプロイ前に環境変数 HOSTNAME を設定するようにしてください。
KOMPIRA_IMAGE_NAME / KOMPIRA_IMAGE_TAG
デプロイする Kompira コンテナのイメージとタグを指定します。 独自に用意したコンテナイメージや、特定のバージョンのコンテナイメージを利用したい場合にこの環境変数で指定することができます。
KOMPIRA_IMAGE_TAG のデフォルト値は ke2-docker 更新時点で公開されていた最新の kompira コンテナイメージを示しています(例えば "2.0.2" など)。KOMPIRA_IMAGE_TAG に "latest" と指定すると、デプロイ時に公開されている最新の kompira コンテナイメージを利用することができます。
DATABASE_URL / AMQP_URL / CACHE_URL
Kompira に必要なサブシステムである、データベースやメッセージキューおよびキャッシュへの接続先を URL 形式で指定します。 デフォルト値ではそれぞれ以下のように接続します。
- データベース: 同じサーバ上の PostgreSQL に Unix ドメインソケットで接続します。
- メッセージキュー: 同じサーバ上の RabbitMQ に TCP 接続します。
- キャッシュ: 同じサーバ上の Redis に TCP 接続します。
参考: https://django-environ.readthedocs.io/en/latest/types.html#environ-env-db-url
TZ / LANGUAGE_CODE
各コンテナのタイムゾーンと言語コードを設定します。
- タイムゾーンは、画面やログで表示される時刻のタイムゾーンの指定になります。
- 言語コードは "ja" (日本語) または "en" (英語) が指定できます。この値は、初回起動時にインポートする初期データの言語の指定になります。
MAX_EXECUTOR_NUM
Kompira エンジン (kengine) 上で動作する Executor プロセスの最大数を、1 つの kengine あたりで指定します。未設定または 0 の場合は、その kengine コンテナの CPU コア数に従います。明示的に上限を指定する場合は 1 以上の整数を指定してください。
1 つの kengine が起動する Executor 数は、その kengine の CPU コア数 (本値を指定した場合は CPU コア数と本値の小さい方) までです。さらに、システム全体で動作する Executor の合計数は、導入されているライセンスで付与される最大 Executor 数に制限されます。複数の kengine を動作させる構成 (Swarm など) では、各 kengine への割り当ては起動時にシステム全体の残り枠から配分されます。
ジョブフローの並列実行数を増やしてスケールしたい場合は、ライセンスの購入とサーバリソース (CPU コア数・ノード) の増強で対応します。なお各 Executor は PostgreSQL への接続を 1 つ保持するため、Executor 数を増やす構成では接続先 PostgreSQL の最大接続数 (内部 postgres 構成では POSTGRES_MAX_CONNECTIONS、外部データベース構成では接続先 DB サーバ側で設定) の見積りにも反映してください。
KOMPIRA_LOG_DIR
ログを保存する ホスト側のディレクトリ を指定します。指定するとコンテナ内の /var/log/kompira にバインドマウントされます。未指定の場合は、標準シングル構成・外部DBシングル構成では名前付きボリューム kompira_log に、Swarm 構成では共有ディレクトリ (SHARED_DIR) 配下の log ディレクトリに保存されます。(コンテナ内のログ出力パス自体は下記 LOGGING_DIR で指定します。)
LOGGING_XXX / AUDIT_LOGGING_XXX
Kompira コンテナイメージにおけるプロセスログおよび監査ログの設定について指定します。
| 環境変数名(プロセスログ) | 環境変数名(監査ログ) | 意味 |
|---|---|---|
| LOGGING_LEVEL | AUDIT_LOGGING_LEVEL | ログレベル |
| LOGGING_DIR | AUDIT_LOGGING_DIR | ログ出力ディレクトリ |
| LOGGING_BACKUP | AUDIT_LOGGING_BACKUP | ログバックアップ数 |
| LOGGING_WHEN | AUDIT_LOGGING_WHEN | ログローテートタイミング |
| LOGGING_INTERVAL | AUDIT_LOGGING_INTERVAL | ログローテートインターバル |
LOGGING_LEVEL: プロセスログの記録レベルを指定します。- デフォルトは "INFO" です。
AUDIT_LOGGING_LEVEL: 監査ログの記録レベルを指定します。- デフォルトは 2 です。
LOGGING_DIR/AUDIT_LOGGING_DIR: ログの出力先ディレクトリを指定します。- デフォルトは "/var/log/kompira" です。標準的なデプロイ手順ではこのディレクトリはホストの kompira_log ボリュームにマウントされます。
- デフォルト (
/var/log/kompira) から変更する場合は、変更先の出力ディレクトリがコンテナから書き込める形で用意されていることを確認してください。
LOGGING_BACKUP: ログローテート時に保存されるバックアップ数を指定します。LOGGING_BACKUPのデフォルトは 7 です。AUDIT_LOGGING_BACKUPのデフォルトは 365 です。
LOGGING_WHEN/AUDIT_LOGGING_WHEN: ログローテートのタイミングを指定します。デフォルトは "MIDNIGHT" です。LOGGING_INTERVAL/AUDIT_LOGGING_INTERVAL: ログローテートのインターバルを指定します。デフォルトは 1 です。
ログのローテーションは LOGGING_WHEN および LOGGING_INTERVAL の積に基づいて行います。
LOGGING_WHEN は LOGGING_INTERVAL の単位を指定するために使います。使える値は下表の通りです。大小文字の区別は行いません。
| LOGGING_WHEN の値 | LOGGING_INTERVAL の単位 |
|---|---|
| "S" | 秒 |
| "M" | 分 |
| "H" | 時間 |
| "D" | 日 |
| "W0"-"W6" | 曜日 (0=月曜) |
| "MIDNIGHT" | 深夜0時 |
UWSGI_XXX / KOMPIRA_NGINX_UWSGI_READ_TIMEOUT / KOMPIRA_NGINX_UWSGI_SEND_TIMEOUT
Kompira コンテナで動作する uWSGI (アプリケーションサーバ) のワーカ並列度・タイムアウトと、その前段の nginx から uWSGI へのタイムアウトを指定します。 いずれも未設定なら従来どおりのデフォルト値で動作するため、通常はそのままで構いません。
これらのパラメータは、目的別に (1) 同時処理数 (並列度)、(2) タイムアウト、(3) 接続の受け付け の 3 系統に分かれます。まず一覧を示し、続いて調整が必要になる場面ごとの指針を示します。
| 環境変数名 | デフォルト | 意味 |
|---|---|---|
UWSGI_PROCESSES | "5" | uWSGI のワーカプロセス数 |
UWSGI_THREADS | "1" | 1 ワーカあたりのスレッド数 |
UWSGI_LISTEN | "100" | ソケットの listen キュー長 |
UWSGI_HARAKIRI | "0" | 処理がこの秒数を超えたリクエストを打ち切り、ワーカを再起動 (0 で無効)。全 HTTP リクエストが対象 |
UWSGI_THUNDER_LOCK | "false" | thunder-lock (accept の公平化) を有効化するか。UWSGI_THREADS を増やす場合は有効化 (true) を推奨 |
uWSGI 系パラメータを調整すべき代表的な場面と対応は次のとおりです。
(1) 同時処理数を上げたい — 高負荷で画面や API の応答が全体的に遅い、あるいはジョブフローの .wait / .recv を画面/API (HTTP) 経由で多用してワーカが長時間占有される場合。
- 同時に処理できるリクエスト数は
UWSGI_PROCESSES×UWSGI_THREADSです。CPU を使い切る処理はプロセス数を、.wait/.recvのような待ち中心の処理はスレッド数を増やすのが基本です。 - スレッドを増やす場合は
UWSGI_THUNDER_LOCKをtrueにすることを推奨します。デフォルト (false) では新規接続時に複数ワーカが一斉に起きて処理が一部に偏る (thundering herd) ことがあり、スレッドを増やしても性能が伸びにくくなります。有効化すると accept が直列化され、各ワーカへ接続が公平に配分されます。
注意 (
POSTGRES_MAX_CONNECTIONSの見積り): DB 接続数はおおむね「処理中の Web リクエスト数 (同時上限 =UWSGI_PROCESSES×UWSGI_THREADS。アイドル時はほぼ 0) + kengine (エンジン本体 + Executor 数。1 Executor = 1 接続で、並行ジョブフロー数では増えません) + 管理・保守用のわずかな接続」です。実機検証では、同時 K 件のブロッキング要求 (.wait/.recv等) を捌くにはPOSTGRES_MAX_CONNECTIONS≧ K + 約 15 が目安です。デフォルト 100 は標準構成には十分ですが、UWSGI_PROCESSES×UWSGI_THREADSを大きく上げる場合は連動して引き上げてください。不足すると "FATAL: sorry, too many clients already" で接続が拒否され、画面や API が 500 エラーになります。(外部データベース構成ではPOSTGRES_MAX_CONNECTIONS環境変数は無効なので、接続先 DB サーバのmax_connectionsで同様に見積もってください。)
(2) 個々のリクエストの処理が長い — 大きなエクスポート・重いクエリ・HTTP 経由の長い .wait / .recv など、1 リクエストの処理に時間がかかる場合。
- 途中で打ち切られないよう
KOMPIRA_NGINX_UWSGI_READ_TIMEOUT/KOMPIRA_NGINX_UWSGI_SEND_TIMEOUT(各デフォルト 300 秒) を想定する最長リクエスト時間以上に延ばします。逆に、枯渇時に早期に失敗させたい場合は短めにします。 UWSGI_HARAKIRIはデフォルトで無効です。有効化すると全 HTTP リクエストが対象になり、この秒数を超えたリクエストはワーカごと強制終了・再起動されます。有効化する場合は、想定最長時間かつKOMPIRA_NGINX_UWSGI_READ_TIMEOUT/KOMPIRA_NGINX_UWSGI_SEND_TIMEOUTの長い方以上の値にしてください。
メモ:
UWSGI_HARAKIRIと nginx のタイムアウトは役割が異なります。UWSGI_HARAKIRIは張り付いたリクエストを打ち切って ワーカを回収 するためのもの (処理時間のハードリミット)、nginx の read/send タイムアウトは応答しない upstream を待ち続けず クライアントにエラーを返す ためのもの (I/O 間の無通信時間) です。ワーカ枯渇の緩和は (1) の並列度引き上げが基本で、UWSGI_HARAKIRIは想定を超えて張り付いたリクエストに対する安全網として使います。
(3) 短時間に大量の接続が集中する — バースト的なアクセスで接続が待たされる/拒否される場合。
UWSGI_LISTEN(接続待ち行列 = listen backlog の長さ) を増やします。待ち行列を超えて到着した接続は待たされたり失敗したりします。実効値はカーネルのnet.core.somaxconnが上限となります (KE2.0 のコンテナデフォルトは 4096)。
POSTGRES_XXX
postgres コンテナの主要なチューニング項目を指定します。 いずれも未設定なら PostgreSQL の標準値で動作するため、通常はそのままで構いません。 上記の Web ワーカ並列度を引き上げる場合や、大規模環境でメモリを活用したい場合に調整します。
なお、これらは内部 postgres コンテナを持つ標準シングル構成でのみ有効です。 外部データベース構成 (single/extdb・cluster/swarm) では効果がなく、 チューニングは接続先の外部 DB サーバ側で行ってください。
| 環境変数名 | デフォルト | 対応する postgres 設定 |
|---|---|---|
POSTGRES_MAX_CONNECTIONS | "100" | max_connections |
POSTGRES_SHARED_BUFFERS | "128MB" | shared_buffers |
POSTGRES_EFFECTIVE_CACHE_SIZE | "4GB" | effective_cache_size |
POSTGRES_WORK_MEM | "4MB" | work_mem |
POSTGRES_MAINTENANCE_WORK_MEM | "64MB" | maintenance_work_mem |
POSTGRES_MAX_CONNECTIONS: 受け付ける最大同時接続数です。上記の Web ワーカ並列度と連動させて設定します。POSTGRES_SHARED_BUFFERS/POSTGRES_EFFECTIVE_CACHE_SIZE/POSTGRES_WORK_MEM/POSTGRES_MAINTENANCE_WORK_MEMはメモリ関連のチューニングパラメータです。いずれもホストの搭載メモリを基準に決める値で、特にPOSTGRES_EFFECTIVE_CACHE_SIZEのデフォルト "4GB" は一定以上の搭載メモリを前提とするため、小規模なホストや他コンテナが同居する構成では実メモリに合わせて見直してください。POSTGRES_WORK_MEMはクエリのソート/ハッシュ処理ごとに確保されるため、実効的なメモリ使用量はおおよそPOSTGRES_WORK_MEM× 同時接続数 × クエリ内の並行ソート数まで膨らみます。POSTGRES_WORK_MEMとPOSTGRES_MAX_CONNECTIONSを同時に引き上げる際はホストの空きメモリに注意してください。- 各パラメータの詳細は PostgreSQL のドキュメントを参照してください。
kompira.conf
AMQP 接続やジョブマネージャの動作に関する設定を行なう設定ファイルで、コンテナ内の /opt/kompira/kompira.conf に配置されます。 ke2-docker パッケージで KE2.0 システムを構築する場合、同パッケージの configs/ ディレクトリに含まれる kompira.conf が /opt/kompira/kompira.conf にバインドされます。
kompira.conf ファイル形式
kompira.conf は以下のようなファイル形式で、Windows における INI ファイル形式に近いものになっています。
[セクション名A]
項目名A1 = 値1
項目名A2 = 値2
[セクション名B]
項目名B1 = 値1
項目名B2 = 値2
kompira.conf セクション一覧
kompira.conf には以下のセクションがあります。
[kompira]: Kompiraシステム関連の設定[logging]: ログ出力関連の設定[amqp-connection]: RabbitMQ の接続情報関連の設定[agent]: ジョブマネージャの動作に関する設定[event]: イベント送信の設定
kompira.conf 項目一覧
kompira.conf で設定できる項目を以下に示します。
| セクション | 項目名 | デフォルト値 | 内容 |
|---|---|---|---|
| [kompira] | site_id | 1 | 本バージョンでは未使用 |
| [logging] | loglevel | INFO | ログ出力レベルの設定 |
| (DEBUG, INFO, WARNING, ERROR, CRITICAL) | |||
| logdir | /var/log/kompira | ログファイルのディレクトリ | |
| logbackup | kompirad: 7 | ログバックアップの世代数 | |
| kompira_jobmngrd: 7 | |||
| kompira_sendevt: 10 | |||
| logmaxsz | kompirad: 0 | ログファイルの最大サイズ(単位はbyte) | |
| kompira_jobmngrd: 0 | 0に設定すると日次ローテートとなる | ||
| kompira_sendevt: 1024 * 1024 * 1024 | |||
| [amqp-connection] | server | localhost | 接続ホスト名 |
| port | (5671 or 5672) | 接続ポート番号 | |
| user | (guest or kompira) | 接続ユーザー名 | |
| password | (guest or kompira) | 接続パスワード | |
| ssl | (true or false) | SSLで接続するかどうか | |
| ssl_verify | false | SSLでサーバ証明書を検証するかどうか | |
| ssl_cacertfile | SSLでサーバ証明書を検証するCA証明書ファイル | ||
| ssl_certfile | SSL接続するときの証明書ファイル | ||
| ssl_keyfile | SSL接続するときの秘密鍵ファイル | ||
| heartbeat_interval | 10 | ハートビートの送信間隔 (単位は秒) | |
| max_retry | 3 | 接続断時に再接続する最大試行回数 | |
| retry_interval | 30 | 接続断時に再接続する間隔 (単位は秒) | |
| [agent] | name | default | ジョブマネージャの名称 |
| pool_size | 8 | 同時プロセスワーカー数 (1~80) | |
| disable_cache | false | リモート接続キャッシュの無効化 | |
| cache_duration | 300 | リモート接続キャッシュの有効期限 (秒) | |
| [event] | channel | /system/channels/Alert | イベント送信先チャネルのKompira上のパス |
なお、Windows 環境では以下のようにデフォルト値が変化します。
[logging] logdir:C:\Kompira\Log
注釈: リモート接続キャッシュは、リモートコマンド実行時のリモート接続を再利用することで、同一ノード、同一アカウントでの連続するリモートコマンド実行の処理を高速化する機能です。ただし、WinRS 接続では高速化の効果が得られないため、disable_cache の設定にかかわらずリモート接続キャッシュは使用しません。
監査ログの設定 (kompira_audit.yaml)
監査ログに関する設定を行なう設定ファイルで、コンテナ内の /opt/kompira/kompira_audit.yaml に配置されます。
ke2-docker パッケージで KE2.0 システムを構築する場合、同パッケージの configs/ ディレクトリに含まれる kompira_audit.yaml が /opt/kompira/kompira_audit.yaml にバインドされます。
kompira_audit.yaml の形式
設定ファイルは kompira_audit.yaml は YAML 形式で記述します。全体としては辞書構造で、以下の設定項目が必要になります。
| 名称 | 形式 | 説明 |
|---|---|---|
logging_level | 整数 | 監査ログの記録レベル値 |
operation_levels | 辞書 | 操作ごとの操作レベル基準値テーブル |
target_levels | 配列 | オブジェクト操作等における操作対象ごとの操作レベル基準値テーブル |
環境変数による記録レベル値の設定
ke2-docker パッケージでデプロイ時に環境変数 AUDIT_LOGGING_LEVEL を指定すると、その値が監査ログの記録レベル値 (logging_level) として適用されます。これは設定ファイル kompira_audit.yaml での設定より優先します。
kompira_audit.yaml の自動再読み込み
監査ログの設定ファイルをサーバー上で更新すると、次の監査ログ記録のタイミングで自動的に再読み込みされます。サービスの再起動などは不要です。
デフォルトの kompira_audit.yaml
#--------------------------------------------------------------------
# kompira_audit.yaml
#
# Configuration file to control audit log output.
#--------------------------------------------------------------------
#
# logging_level: recording level value
#
# If the calculated operation level value is less than the recording
# level value, no audit log will be recorded.
#
logging_level: 2
#
# operation_levels: basic operation level table
#
# Table of operation level reference values for each operation.
# The operation level value for an operation is the maximum of
# several operation level criteria values.
#
operation_levels:
interface:
web: 1
api: 1
mng: 2
class:
session: 3
user: 3
group: 3
object: 1
task: 1
incident: 1
process: 1
schedule: 1
packages: 1
type:
login: 3
logout: 3
create: 3
rename: 3
copy: 3
move: 3
export: 3
import: 3
execute: 3
suspend: 3
resume: 3
terminate: 3
read: 1
list: 1
search: 1
edit: 1
confirm: 1
update: 2
clear: 2
recv: 2
send: 2
delete: 3
permit:
allowed: 1
denied: 3
result:
succeeded: 1
failed: 1
#
# target_levels: operation level table for object operation
#
# Operation level reference value to be applied to each target
# during object manipulation.
#
target_levels:
- {path: '/config/*', type: null, level: 2}
- {path: '/system/*', type: '/system/types/Config', level: 2}
Kompira 画像
ブラウザ画面で表示される画像は kompira コンテナ内の以下に配置されています。
/var/opt/kompira/html/kompira/img/
ここに配置されている画像ファイルは以下の通りです。画像ファイルを直接置き換えることで、画面の見た目を変更することができます。
| ファイル名 | 用途 | サイズ | 説明 |
|---|---|---|---|
| favicon.svg | ファビコン (SVG形式) | 16x16 | ブラウザタブやお気に入り登録したときのアイコンに利用されます |
| favicon.ico | ファビコン (ICO形式) | 16x16 | 同上(SVG 形式に対応していないブラウザに利用されます) |
| brand-logo.svg | ブランドロゴ画像 | 40x40 | メニューバー左上に表示されます |
| login-logo.svg | ログインロゴ画像 | 128x128 | ログイン画面およびログアウト画面の中央に表示されます |
| console-loading.gif | コンソールローディング画像 | 20x20 | プロセス詳細画面でプロセスがアクティブな間コンソールに表示されます |
サイズは一般的な解像度のディスプレイで表示される時のピクセル数を参考値として示しています。
nginx 設定
nginx-default.conf
nginx のコンフィグファイル。
ホスト側で設定した nginx-default.conf を kompira-web (nginx) コンテナの /etc/nginx/conf.d/default.conf にバインドされるように docker-compose.yml の設定を行う。
ロギング設定
デフォルトのログ出力
KE2.0 はデフォルトでは以下のようなログ出力の構成になっています。
- 各コンテナのメインログは docker のコンテナログとして記録されます。
- 【要確認】コンテナログはデフォルトでは、20MB ごと 5世代分が保持されます。
- コンテナログの確認方法については コンテナログ管理 を参照してください。
- プロセスログおよび監査ログについては、docker の kompira_log ボリュームにファイルとして記録されます。
docker 外部でのログ記録
(WIP) fluentd などを用いて docker 外部でログを記録する設定方法について記載します。
管理ガイド
ここに運用ガイドを書きます。
管理コマンド
運用ガイドの説明において管理コマンド manage.py を実行する場面がたびたび登場します。
KE2.0 では基本的に manage.py は kompira コンテナ内部で実行する必要があるため、動作中の kompira コンテナのコンテナ ID を知る必要があります。
なお、docker コマンドはコンテナ ID でなくコンテナ名を指定して実行することもできますが、構成によってコンテナ名が変わるため本マニュアルではコンテナ ID を指定して実行する手順で説明を共通化しています。
コンテナID とコンテナ名
コンテナ ID とコンテナ名は例えば以下のように docker ps コマンドで確認できます。
$ docker ps --format "{{.ID}} {{.Names}}"
aa5314b683e1 ke2-nginx-1
38dac7c77f60 ke2-kompira-1
a5caf7bd1ab6 ke2-kengine-1
dcadb5893a30 ke2-jobmngrd-1
bbdf0ed2bf9f ke2-postgres-1
2825a9737c12 ke2-rabbitmq-1
865c495d50b6 ke2-redis-1
上の結果では ke2-kompira-1 が該当して、コンテナ ID が 38dac7c77f60 であることが分かります。
kompira コンテナの実際のコンテナ名はシステム構成や構築した手順によって変わりますが、以下のように docker ps コマンドを使って名前に "kompira" という文字列を含むコンテナのコンテナIDを知ることができます。
$ docker ps -q -f name=kompira
38dac7c77f60
この手法を用いて、kompira コンテナ内部で manage.py コマンドを実行したい場合は以下のように行ないます。
$ docker exec $(docker ps -q -f name=kompira) manage.py <SUBCOMMAND> ...
クラスタ構成での管理コマンドの実行
【要確認】 クラスタ構成の場合は、どのノード上で管理コマンドを実行するべきかという疑問が生じますが、対象とするコンテナが正常に動作しているノードであればどこで実行しても問題ありません。
ライセンス管理
KE2.0 におけるライセンス管理について示します。
ライセンス情報
Kompira のライセンス情報にはいくつかのフィールドが含まれています。 ライセンス管理画面で確認できる項目の一覧を以下に示します。
| フィールド | 説明 |
|---|---|
| ライセンスID | ライセンスファイルの固有ID |
| エディション | ライセンスの種類 |
| システムID | Kompira システム固有ID |
| 有効期限 | ライセンスの有効期限 |
| 登録済みノード数 | ジョブフローから接続したことのあるノードの数 |
| エグゼキュータ数 | ジョブフローを実行するエグゼキュータの数 |
| ジョブフロー数 | オブジェクトとして登録されているジョブフローの数 |
| スクリプト数 | オブジェクトとして登録されているスクリプトジョブの数 |
| 使用者 | ライセンスの使用者 |
| 署名 | ライセンスファイル署名 |
ここの「システムID」がライセンスを管理する上でのシステム固有IDとなっており、ライセンス申請する際に必要な情報となります。 また発行されたライセンスファイルにもシステムIDが含まれており、システムIDが一致していないとライセンスを更新することができません。
KE2.0 のライセンス情報では、v1.6 までのライセンス情報から以下の変更があります。
- ライセンス管理がノード単位からシステム単位に変更になり、ライセンス対象を特定する情報が「ノードID」から「システムID」に変更になりました。
- ジョブフローの並列実行が可能になり、「エグゼキュータ数」フィールドが追加になりました。
システムID の算出について
KE2.0 のシステムID は、Kompira システムごとに固有の値となるよう、接続先データベースの情報を元に算出されます。具体的には、Django のデータベース接続設定における HOST と NAME(環境変数 DATABASE_URL から取得される値)をシードとして UUID v5 形式で生成されます。
このため、以下のような操作を行うとシステムID が変化することがあります。
- 接続先データベースのホストを変更する
- 接続先データベース名を変更する
- 環境変数
DATABASE_URLの HOST 部分または NAME 部分が変わるように変更してデプロイし直す (パスワードやユーザ名のみの変更ではシステムID は変化しません)
注: ここで言う HOST / NAME は、
DATABASE_URLをパースして得られる Django 内部の接続設定(DATABASES['default']のHOST/NAMEフィールド)を指します。ke2-docker の compose ファイル側でDATABASE_URLを組み立てるために利用される個別環境変数(DATABASE_USER/DATABASE_PASSWORD/DATABASE_NAME)とは別レイヤであり、システムID 算出時には実際にパースされたDATABASE_URLの値が使われます。
システムID が変わるとライセンスとの不一致が発生し、ライセンス再発行が必要となります。これらの操作を行う際は事前に運用ポリシーを確認してください。
ライセンスの管理
ライセンスの確認、申請、および更新の手順については以下のページを参照してください。
ライセンスの確認
ブラウザまたは管理コマンドでライセンスの確認を行なうことができます。
ライセンス管理ページ
ブラウザでライセンス管理ページ (/config/license) を開くと、ライセンス情報を確認することができます。
license_info 管理コマンド
kompira コンテナで license_info 管理コマンドを用いて Kompira のライセンス状態を確認することもできます。
docker exec $(docker ps -q -f name=kompira) manage.py license_info
以下はライセンスが登録されている場合の実行例です。
*** Kompira License Information ***
License ID: KE2-0000XXXX
Edition: Development
System ID: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
Expire date: 2025-12-31
The number of registered nodes: 2 / 100
The number of registered executors: 2 / 2
The number of registered jobflows: 3
The number of registered scripts: 0
Licensee: kompira@example.co.jp
Signature: XXXXXXXXXXXXXXXX....XXXXXXXXXXXXXXXX
ライセンスが登録されていない場合は、仮ライセンス情報が表示されます。
*** Kompira License Information ***
License ID: KP-TEMP-0000000000
Edition: temporary
System ID: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
Expire date: 2024-07-07
The number of registered nodes: 0 / 100
The number of registered executors: 2 / 2
The number of registered jobflows: 2 / 100
The number of registered scripts: 0 / 100
Licensee:
Signature: None
Kompira is running with temporary license.
ライセンスの申請
Kompira Enterprise を継続して利用される場合はライセンス登録が必要になります。 詳しくは license@kompira.jp までご連絡ください。
その際、ライセンスの確認 で表示されたシステム ID (System ID) をお伝えください。
ライセンスの更新
ブラウザまたは管理コマンドでライセンスの更新を行なうことができます。
ライセンス管理ページ
ライセンス管理ページ (/config/license) で「編集」ボタンを押下すると、ライセンスファイルを登録する画面に遷移します。 発行されたライセンスファイルを選択して「保存」を押下すると、ライセンス情報を更新することができます。
license_update 管理コマンド
ライセンスファイルをコマンドから更新する場合、ライセンスファイルをコンテナのファイルシステム上にコピーしてから、license_update コマンドを実行する。
$ docker cp <FILENAME> $(docker ps -q -f name=kompira):/tmp/
$ docker exec $(docker ps -q -f name=kompira) manage.py license_update /tmp/<FILENAME>
license_update コマンドのオプション
license_update コマンドには以下のオプションがあります。
| オプション | 説明 |
|---|---|
--force | ライセンスファイルの検証に失敗しても強制的に更新します |
なお、KE2.0 ではライセンス情報はデータベース上で管理されています。 KE1.6 までのようにファイルコピー操作でライセンスを適用することは出来ないのでご注意ください。また、license_update コマンドにおける --no-backup オプションは廃止されています。
システム管理
KE 2.0 におけるシステム管理について示します。
システムステータスの確認
エンドポイント /.status に HTTP/HTTPS アクセスすることで、システムを構成する各コンテナのステータスを確認することができます。
監視システムで Kompira の状態を監視したい、また、クラスタ構成で前段でロードバランサーを設定してステータスによって振り分けたい、といった場合に利用することができます。
注意: このエンドポイントは認証無しにアクセスすることができるようになっています。外部からのアクセスを防ぐ必要がある場合は、Kompira システムの外部のファイアーウォールなどでブロックするようにしてください。
※ システムステータスの確認は KE v2.0.1 から対応しました。
ステータスコード
システムステータス /.status にアクセスすると、レスポンスのステータスコードでシステムの全体的な状況を示します。
- 200 OK: 正常
- 503 Service Unavailable: 重要なコンテナ (redis, postgres) が動作していない。
- 504 Gateway Timeout: kompira コンテナが動作していない、または、ステータス取得にタイムアウトした。
※ kompira コンテナより前段のコンポーネントが上記以外のエラーコードを返す場合も考えられます。
応答がない場合は、Kompira システムのホストサーバがダウンしている、ネットワークが導通していない、Docker およびコンテナが正常に動作していない、といった障害が発生していることが考えられます。
システムステータスが異常を示している、またはシステムステータスが取得できない、といった場合は、システムに何らかの問題が生じていると考えられます。トラブルシュートを参考にして、システムの診断を行なって回復手順を試してみてください。
ブラウザアクセス時のシステムステータス
エンドポイント /.status にブラウザでアクセスすると、以下のような画面が表示されます。
")
これは、全てのコンテナが正常に動作しているときの表示になります。
一方で、異常や警告が発生しているコンテナがあると、以下のように当該コンテナが赤(異状)や黄色(警告)の表示になります。
")
各コンテナの領域をクリックすると以下のように詳細な情報が表示されますが、その内容は次に示す API アクセス時のレスポンスと同じです。
")
ここまではステータスコードとしては 200 となる例を示していました。重要なコンテナ (redis, postgres) が動作していない場合はステータスコードが 503 となり、以下のように画面の表示上でもステータスコードを確認することができます。
")
API アクセス時のシステムステータス
エンドポイント /.status に API アクセスすると、JSON 形式のレスポンスを得ることができます。
API アクセスするには、リクエストのヘッダに Accept: application/json を含めてください。または、クエリ文字列に
format=json を含めて /.status?format=json にアクセスする方法もあります。
API アクセスでは、各コンテナのステータスを含む情報を以下のような辞書形式で返します。
{
"redis": {
"status": <Status of Redis: "OK"|"NG"|"ERROR">
},
"postgres": {
"status": <Status of PostgreSQL: "OK"|"NG"|"ERROR">
},
"rabbitmq": {
"status": <Status of RabbitMQ: "OK"|"NG"|"ERROR">
},
"kompira": {
"status": <Status of Kompira server: "OK"|"WARNING"|"ERROR">
"detail": {
"version": <Version of kompira>,
"hostname": <Hostname of kompira>,
"proc_id": <process id>,
"started_datetime": <Date and time the kompira server started>,
"license_expire": <Date the license expires>,
"license_error": <License error> or null
}
},
"kengine": {
"status": <Status of Kompira engine: "OK"|"NG"|"ERROR">
"total_num": <Total number of kompira engines>,
"running_num": <Number of running kompira engines>,
"executor_num": <Number of active executors>,
"detail": [
{
"engine_id": <Engine ID>,
"status": <Status of engine: "STARTED"|"RUNNING"|"UNKNOWN">,
"role": <Role of engine: "leader"|"follower">,
"hostname": <Hostname of kengine>,
"executor_num": <Number of executor>,
"started_datetime": <Date and time the kompira engine started>,
"proc_id": <process id>
},
...
]
},
"jobmngrd": {
"status": <Status of Kompira jobmngrd: "OK"|"NG"|"ERROR">
"total_num": <Total number of jobmngrd>,
"active_num": <Number of active jobmngrd>,
"detail": [
{
"realm_name": <Realm name>,
"status": <Status of jobmngrd: "RUNNING"|"UNKNOWN">,
"hostname": <Hostname of jobmngrd>,
"version": <Version of jobmngrd>,
"ssl": <SSL version>,
"pid": <process id>
},
...
]
}
}
レスポンス辞書の、コンテナごとのステータス値 (.status) は、以下のような状態を示しています。
- "OK": 正常
- "WARNING": 正常(ただし警告を示す情報がある)
- kompira: ライセンスエラーが生じている。
- "NG": 異状(対象コンテナにアクセスできるが、正常性を示していない)
- redis: PING 要求に応答しない。
- postgres: クエリ "SELECT 1" に応答しない。
- rabbitmq: 接続後に内部で例外が発生している。
- kengine: 実行状態のエンジンが 1 つも存在しない、または、アクティブなエグゼキュータが 1 つも存在しない。
- jobmngrd: アクティブなジョブマネージャが 1 つも存在しない。
- "ERROR": エラー
- 対象コンテナが動作していない、または、アクセスできない。
データ管理
ここではデータ管理の手法について示します。
データのエクスポート
export_data 管理コマンドによるエクスポート
export_data 管理コマンドを用いると、指定したパス配下の Kompira オブジェクトを JSON 形式でエクスポートすることができます。 KE2.0 では kompira コンテナ上で export_data 管理コマンドを実行させるために、ホスト上では以下のように実行してください。
$ docker exec $(docker ps -q -f name=kompira) manage.py export_data [options...] <OBJECT_PATH>
デフォルトではエクスポートデータは標準出力に出力されるので、ファイルに書き出したい場合はリダイレクトを利用するなどしてください。
$ docker exec $(docker ps -q -f name=kompira) manage.py export_data <OBJECT_PATH> > exported_data.json
export_data 管理コマンドで --zip-mode オプションを指定した場合は、エクスポートデータはコンテナ側に ZIP ファイルとして書き出されることに注意してください。 エクスポートされた ZIP ファイルをホスト側で利用するには、例えば以下のようにエクスポート後にホスト側にコピーしてください。
$ docker exec $(docker ps -q -f name=kompira) manage.py export_data --zip-mode <OBJECT_PATH>
$ docker exec $(docker ps -q -f name=kompira) ls # 出力された zip ファイル名を確認
$ docker cp $(docker ps -q -f name=kompira):/opt/kompira/<FILENAME> .
export_data 管理コマンドのオプション
export_data 管理コマンドには以下のオプションがあります。
| オプション | 説明 |
|---|---|
--directory=DIRECTORY | エクスポートするパスの起点となるディレクトリを指定します(*1) |
--virtual-mode | 仮想ファイルシステムに含まれるデータも出力します |
--owner-mode | エクスポート対象となったオブジェクトの所有者(*2)も出力します |
--zip-mode | ZIP 形式で出力します |
--without-attachments | 添付ファイルデータを出力しません |
-h, --help | ヘルプメッセージを表示します |
--directoryオプションを指定していない場合は/がエクスポートの起点となります。- 所有者であるユーザオブジェクトおよびその所属グループオブジェクトが追加で出力されます。
export_dir 管理コマンドによるエクスポート
export_dir 管理コマンドを用いると、指定したパス配下の Kompira オブジェクトをオブジェクト毎に YAML ファイルとしてエクスポートすることができます。
なお、以下の型を持つオブジェクトの場合は、代表するフィールドのデータのみがファイルとして出力され、
残りのフィールドは、.<OBJECT_NAME> という名前の YAML ファイルとして、プロパティ情報とともに出力されます。
| 型名 | 代表フィールド | ファイル形式 |
|---|---|---|
| Jobflow(ジョブフロー) | source(ソース) | テキスト |
| ScriptJob(スクリプトジョブ) | source(ソース) | テキスト |
| Library(ライブラリ) | sourceText(ソーステキスト) | テキスト |
| Template(テンプレート) | template(テンプレート) | テキスト |
| Text(テキスト) | text(テキスト) | テキスト |
| Wiki(Wikiページ) | wikitext(Wikiテキスト) | テキスト |
| Environment(環境変数) | environment(環境変数) | YAML |
KE2.0 では kompira コンテナ上で export_dir 管理コマンドを実行させるために、ホスト上では以下のように実行してください。
$ docker exec $(docker ps -q -f name=kompira) manage.py export_dir [options...] <OBJECT_PATH>
export_dir 管理コマンドではコンテナ上のファイルシステムにファイルを書き出すことに注意してください。 エクスポートされたデータをホスト側で利用するには、例えば以下のようにエクスポート後にホスト側にコピーしてください。
$ docker exec $(docker ps -q -f name=kompira) manage.py export_dir --current /tmp <OBJECT_PATH>
$ docker exec $(docker ps -q -f name=kompira) ls /tmp/ # 出力されたディレクトリ名を確認
$ docker cp $(docker ps -q -f name=kompira):/tmp/<DIRNAME> .
ここでは、コンテナ上の /tmp ディレクトリにエクスポートしたのちに、ディレクトリ一式をホスト上の指定したディレクトリ (.) にコピーしています。
export_dir 管理コマンドのオプション
export_dir 管理コマンドには以下のオプションがあります。
| オプション | 説明 |
|---|---|
--directory=DIRECTORY | エクスポートするパスの起点となるディレクトリを指定します(*1) |
--property-mode | 表示名など属性も出力します |
--datetime-mode | 作成日時と更新日時も出力します |
--current=CURRENT_DIR | 出力先のディレクトリを指定します |
--without-attachments | 添付ファイルデータを出力しません |
--inline-attachments | 添付ファイルデータをYAMLファイルに含めて出力します |
--linesep=LINESEP | 代表フィールドを出力するときの改行コードを指定します(*2) |
-h, --help | ヘルプメッセージを表示します |
--directoryオプションを指定していない場合は/がエクスポートの起点となります。LINESEPにはos_linesep,lf,crlf,no_changeのいずれかを指定できます。os_linesepでは OS 標準の改行コードに、lfでは\nに、crlfでは\r\nに変換します。no_changeを指定したときは改行コードを変更しません。デフォルトではos_linesepです
注釈: --linesep は上表でファイル形式が「テキスト」のオブジェクトにのみ影響します。
データのインポート
import_data 管理コマンドによるインポート
import_data 管理コマンドを用いると、export_data 管理コマンドでエクスポートしたファイルからデータを取り込むことができます。 KE2.0 では kompira コンテナ上で import_data 管理コマンドを実行させるために、ホスト上からは以下のように実行してください。
$ docker exec $(docker ps -q -f name=kompira) manage.py import_data [options...] <FILENAME>...
ホスト上にあるエクスポートデータをインポートするには、例えば以下のようにインポート前にホスト側からコピーしてください。
$ docker cp <FILENAME> $(docker ps -q -f name=kompira):/tmp/
$ docker exec $(docker ps -q -f name=kompira) manage.py import_data /tmp/<FILENAME>
ここでは、コンテナ上の /tmp ディレクトリにエクスポートデータをコピーしてから、import_data 管理コマンドでインポートしています。
import_data 管理コマンドのオプション
import_data 管理コマンドには以下のオプションがあります。
| オプション | 説明 |
|---|---|
--user=USER | インポートするデータの所有者を USER (ユーザーIDを指定)に設定します |
--directory=ORIGIN-DIR | インポート先の起点となるディレクトリを指定します(*1) |
--overwrite-mode | 既存のオブジェクトがある場合に上書きします(*2) |
--owner-mode | インポートするデータの所有者をエクスポート時の所有者情報に設定します |
--update-config-mode | Config型オブジェクトの設定データも上書きします(*3) |
--now-updated-mode | 現在時刻をオブジェクトの更新日時に設定します |
-h, --help | ヘルプメッセージを表示します |
--directoryオプションを指定していない場合は/がインポートの起点となります。--overwrite-modeオプションを指定していない場合、インポートデータに既存のオブジェクトが含まれていてもインポートされずにスキップします。--update-config-modeオプションを指定するときは、--overwrite-modeオプションも同時に指定する必要があります
import_dir 管理コマンドによるインポート
import_dir 管理コマンドを用いると、export_dir 管理コマンドでエクスポートしたディレクトリ一式からデータを取り込むことができます。 KE2.0 では kompira コンテナ上で import_dir 管理コマンドを実行させるために、ホスト上からは以下のように実行してください。
$ docker exec $(docker ps -q -f name=kompira) manage.py import_dir [options...] <DIRNAME>...
ホスト上にあるエクスポートデータをインポートするには、例えば以下のようにインポート前にホスト側からコピーしてください。
$ docker cp <DIRNAME> $(docker ps -q -f name=kompira):/tmp/
$ docker exec $(docker ps -q -f name=kompira) manage.py import_dir /tmp/<DIRNAME>
ここでは、コンテナ上の /tmp ディレクトリにエクスポートデータをコピーしてから、import_dir 管理コマンドでインポートしています。
import_dir 管理コマンドのオプション
import_dir 管理コマンドには以下のオプションがあります。
| オプション | 説明 |
|---|---|
--user=USER | インポートするデータの所有者を USER (ユーザーIDを指定)に設定します |
--directory=ORIGIN-DIR | インポート先の起点となるディレクトリを指定します(*1) |
--overwrite-mode | 既存のオブジェクトがある場合に上書きします(*2) |
--owner-mode | インポートするデータの所有者をエクスポート時の所有者情報に設定します |
--update-config-mode | Config型オブジェクトの設定データも上書きします(*3) |
--now-updated-mode | 現在時刻をオブジェクトの更新日時に設定します |
--linesep=LINESEP | 代表フィールドを読み込むときの改行コードを指定します(*4) |
-h, --help | ヘルプメッセージを表示します |
--directoryオプションを指定していない場合は/がインポートの起点となります。--overwrite-modeオプションを指定していない場合、インポートデータに既存のオブジェクトが含まれていてもインポートされずにスキップします。--update-config-modeオプションを指定するときは、--overwrite-modeオプションも同時に指定する必要がありますLINESEPにはos_linesep,lf,crlf,no_changeのいずれかを指定できます。os_linesepでは OS 標準の改行コードに、lfでは\nに、crlfでは\r\nに変換します。no_changeを指定したときは改行コードを変更しません。デフォルトではcrlfです。
注釈: --linesep はテキスト形式のファイルにのみ影響します。
オブジェクトのコンパイル
ジョブフローオブジェクトのコンパイル
以下のコマンドを実行する。
$ docker exec $(docker ps -q -f name=kompira) manage.py compile_jobflow [options...] <JOBFLOW_PATH>
オプションの詳細については、従来と同様 --help オプションで表示される。
ライブラリオブジェクトのコンパイル
以下のコマンドを実行する。
$ docker exec $(docker ps -q -f name=kompira) manage.py compile_library [options...] <LIBRARY_PATH>
オプションの詳細については、従来と同様 --help オプションで表示される。
チャネルオブジェクトの操作
チャネルオブジェクトのメッセージを見る
以下のコマンドを実行する。
$ docker exec $(docker ps -q -f name=kompira) manage.py peek_channel [options...] <CHANNEL_PATH>
オプションの詳細については、従来と同様 --help オプションで表示される。
チャネルオブジェクトからメッセージを取り出す
以下のコマンドを実行する。
$ docker exec $(docker ps -q -f name=kompira) manage.py pop_channel [options...] <CHANNEL_PATH>
オプションの詳細については、従来と同様 --help オプションで表示される。
プロセスオブジェクト管理
manage.py process 管理コマンドを用いて、Kompira プロセスオブジェクトに対して以下のような操作を行なうことができます。
- プロセスの一覧表示
- プロセスの個数表示
- プロセスの削除
- プロセスの中止
- プロセスの停止
- プロセスの続行
このとき、操作の対象とするプロセスを絞り込む条件を指定することができます。
- プロセスの状態
- 実行しているジョブフロー
- スケジュール起動のプロセスかどうか
- 起動オブジェクトが指定されたプロセスかどうか
- 実行したユーザ
- 開始日時および終了日時
- 実行時間
- コンソール出力に含まれる文字列
process 管理コマンドの実行
process 管理コマンドは以下のように kompira コンテナで実行してください。
$ docker exec $(docker ps -q -f name=kompira) manage.py process [options...]
プロセス操作オプション
Kompira プロセスに対して行う操作を指定するオプションを以下に示します。
| オプション | 説明 |
|---|---|
-L, --list | プロセスの一覧を表示します。デフォルトではアクティブ状態のプロセスを表示します。 |
-C, --count | プロセスの個数を表示します。デフォルトでは全ての状態のプロセスの個数を表示します。 |
-D, --delete | プロセスを削除します。アクティブ状態のプロセスは対象外となります。 |
-T, --terminate | プロセスを中止します。既に終了しているプロセスは対象外となります。 |
-S, --suspend | プロセスを停止します。既に終了しているまたは停止中のプロセスは対象外となります。 |
-R, --resume | プロセスを続行します。既に終了しているまたは停止中でないプロセスは対象外となります。 |
操作を指定するオプションはいずれか1つのみ指定可能で、複数指定した場合は最後のオプションが適用されます。 上記のいずれも指定しなかった場合は、プロセスの一覧表示を行ないます。
大量のプロセスが処理対象となるような場合に、メモリや CPU などのリソース負荷が大きくなる場合がありますのでご注意ください。
プロセス情報の変更を伴う操作(削除、中止、停止、続行)が指定された場合は、実際に制御を適用するかの確認(yes/no の入力)が行なわれます。
制御前の確認を行なわずに適用したい場合は -y オプションを指定してください。制御を適用せずに動作を確認したい場合は --dry-run オプションを指定してください。
| オプション | 説明 |
|---|---|
-y, --noinput | 確認を行なわずに制御を適用する |
--dry-run | 変更を伴う処理を実際には適用しない |
プロセス絞り込みオプション
操作対象とする Kompira プロセスを絞り込む条件を指定するオプションを以下に示します。
| オプション | 説明 |
|---|---|
-i PID, --pid PID | プロセス ID が PID であるプロセス(複数指定可能) |
-a, --all | 全ての状態のプロセス |
--active | アクティブ状態 (NEW, READY, RUNNING, WAITING のいずれか) のプロセス |
--finish | 終了状態 (ABORTED, DONE のいずれか) のプロセス |
--status {NEW,READY,RUNNING,WAITING,ABORTED,DONE} | 指定した状態のプロセス(複数指定可能) |
--suspended | 停止中のプロセス |
--not-suspended | 停止中でないプロセス |
--parent PARENT | 親プロセス ID が PARENT であるプロセス(複数指定可能) |
--anyones-child | 任意の親プロセスを持つプロセス |
--min-children MIN_CHILDREN | 子プロセスの個数が MIN_CHILDREN 以上あるプロセス |
--job JOB | 開始ジョブフローが JOB に正規表現でマッチするプロセス |
--current-job CURRENT_JOB | 実行中ジョブフローが CURRENT_JOB に正規表現でマッチするプロセス |
--scheduled | スケジューラによって起動されたプロセス |
--not-scheduled | スケジューラ以外で起動したプロセス |
--scheduler-id SCHEDULER_ID | ID が SCHEDULER_ID のスケジュールによって起動されたプロセス(複数指定可能) |
--scheduler-name SCHEDULER_NAME | 名称が SCHEDULER_NAME に正規表現でマッチするスケジュールによって起動されたプロセス |
--invoked | 起動オブジェクトが記録される方式で実行されたプロセス |
--not-invoked | 起動オブジェクトが記録されない方式で実行されたプロセス |
--invoker INVOKER | 起動オブジェクトが INVOKER (abspath) であるプロセス(複数指定可能) |
--invoker-type INVOKER_TYPE | 起動オブジェクトの型が INVOKER_TYPE (abspath) であるプロセス(複数指定可能) |
--user USER | 実行ユーザの名称が USER に一致するプロセス(複数指定可能) |
--started-since STARTED_SINCE | 開始日時が STARTED_SINCE 以降のプロセス |
--started-before STARTED_BEFORE | 開始日時が STARTED_BEFORE より前のプロセス |
--finished-since FINISHED_SINCE | 終了日時が FINISHED_SINCE 以降のプロセス |
--finished-before FINISHED_BEFORE | 終了日時が FINISHED_BEFORE より前のプロセス |
--elapsed-more ELAPSED_MORE | 経過時間(秒数)が ELAPSED_MORE 以上長いプロセス |
--elapsed-less ELAPSED_LESS | 経過時間(秒数)が ELAPSED_LESS より短いプロセス |
--console CONSOLE | コンソール出力に CONSOLE を含むプロセス |
--head HEAD | 絞り込み結果の先頭 HEAD 件を処理対象とします |
--tail TAIL | 絞り込み結果の末尾 TAIL 件を処理対象とします |
-r, --reverse | 並び順を逆にします |
--order ORDER | ORDER で指定した順番で並べます |
- 複数指定可能な絞り込みオプションを複数回指定した場合は、それらを OR 条件として絞り込みます。
- 異なる種類の絞り込みオプションを複数指定した場合は、それらを AND 条件として絞り込みます。
- オプションの日時はジョブフローの
datetime()組み込み関数が認識できる形式で指定できます。
その他のオプション
| オプション | 説明 |
|---|---|
--format {table,json,export} | プロセスの一覧表示を行なうときの形式 |
--datetime-format DATETIME_FORMAT | 日時情報を表示するときの形式 |
バックアップとリストア
【1.6】バックアップ
Kompiraの全てのデータをバックアップするための手順について説明します。
Kompiraはデータベース上以外に、サーバ上の :ref:file_hierarchy に挙げられているパスのデータを使用します。
Kompiraのデータをバックアップする際は、export_dataコマンドによるKompiraオブジェクトのバックアップに
加えて、必要に応じてサーバ上のファイルバックアップも行う必要があります。
Kompiraオブジェクトとライセンスファイルのバックアップを行う場合の例を以下に示します。
$ mkdir -p /tmp/kompira_backup
$ cd /tmp/kompira_backup
$ /opt/kompira/bin/manage.py export_data / --virtual-mode > backup.json
$ cp /var/opt/kompira/kompira.lic ./
$ cd /tmp
$ tar zcf kompira_backup.tar.gz ./kompira_backup
アカウント管理
ここではアカウント管理について示します。
アカウントロック
アカウントがロックされるとロックされたユーザの情報表示画面の下部に警告メッセージとともにアクセス元のIPアドレスの一覧が表示されます。 ユーザの情報表示画面に表示されるロック解除ボタンを押すことで、当該ユーザのアカウントロックを解除することができます。
また、管理コマンドを用いることで履歴の確認やロックの解除を行なうこともできます。
アカウントロックの履歴表示
axes_list_attempts 管理コマンドを実行するとログインに失敗した履歴の一覧が表示されます。
docker exec $(docker ps -q -f name=kompira) manage.py axes_list_attempts
なお、ロックを解除すると該当する履歴は削除されます。
アカウントロックの解除
以下の管理コマンドを実行してロック解除することができます。
axes_reset 管理コマンドで全てのアカウントロックを一斉に削除します。
docker exec $(docker ps -q -f name=kompira) manage.py axes_reset
axes_reset_ip 管理コマンドは指定した IP アドレスからのアカウントロックを解除します。
docker exec $(docker ps -q -f name=kompira) manage.py axes_reset_ip [ip ...]
axes_reset_username 管理コマンドは指定したユーザのアカウントロックを解除します。
docker exec $(docker ps -q -f name=kompira) manage.py axes_reset_username [username ...]
ログ管理
コンテナログ管理
各コンテナのメインのログは docker 標準のロギング機構によって、コンテナごとにホスト上のボリューム内に記録されます。
動作中コンテナのログの確認
docker により記録されているコンテナごとのログは docker logs コマンドで確認することができます。 たとえば動作中の kengine コンテナのログは以下のようにコマンドを実行するとコンソールに表示されます。
$ docker logs $(docker ps -q -f name=kengine)
コンテナの標準出力と標準エラー出力はそれぞれ記録されていて、docker logs コマンドではその出力が再現されます。 less コマンドなどで両方のログ出力を確認したい場合は、標準エラー出力を標準出力にリダイレクトして出力させると確認しやすくなります。
$ docker logs $(docker ps -q -f name=kengine) 2>&1 | less -RS
ログの分量が多いようなときに、最新 N 行分のログだけ確認したい場合は -n オプションで取得する行数を指定できます。
$ docker logs $(docker ps -q -f name=kengine) -n 10
動作中コンテナのログ出力を継続的に確認したい場合は、-f オプションをつけて実行してみてください。
$ docker logs $(docker ps -q -f name=kengine) -n 10 -f
...
...
※ CTRL+C で中止できます
タイムスタンプを指定することで、過去の特定時間帯のログを取得することができます。
# [特定のノード]$ docker logs <CONTAINER_ID> --since <TIMESTAMP> --until <TIMESTAMP>
# <CONTAINER_ID>: 対象コンテナのコンテナ ID(docker ps -q などで取得できます)
# --since: Show logs since timestamp (e.g. "2013-01-02T13:23:37Z") or relative (e.g. "42m" for 42 minutes)
# --until: Show logs before a timestamp (e.g. "2013-01-02T13:23:37Z") or relative (e.g. "42m" for 42 minutes)
$ docker logs $(docker ps -q -f name=kengine) --since 10m --until 5m
停止中コンテナのログの確認
停止中のコンテナのログを確認したい場合は、docker ps コマンドではコンテナ ID が取得できないので、別の手法を用いる必要があります。
別の方法としては例えば docker container ls -a コマンドで、停止中のコンテナも含めてその一覧を得る方法があります。
$ docker container ls -a -f name=kengine
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
31fc2ccc0c5f kompira-enterprise:2.0.0b1_31f7c1f2 "docker-entrypoint.s…" 2 minutes ago Exited (0) About a minute ago ke2-kengine-1
これを利用すれば停止中のコンテナのログを確認することもできます。
$ docker logs $(docker container ls -a -q -f name=kengine)
なお、コンテナが削除されるとログも削除されて確認できなくなるので注意してください。 コンテナの状態に関わらずログを確認できるようにしたい場合は、ログを docker 外部で記録することを検討してください。
コンテナログの一括取得
すべてのコンテナの最近の一定期間分のログを取得してファイルに書き出したいという場合は、例えば以下のように docker container コマンドの結果をもとにコンテナごとに docker logs コマンドでログを取得してファイルに出力してください。
$ docker container ls -a --format '{{.ID}} {{.Names}}' | while read id name; do docker logs --since "24h" --timestamps $id 2>&1 | gzip > "${name%.*}-${id}.log.gz"; done
この例では docker container ls コマンドに -a オプションを付けることで停止中のコンテナも対象にしています。また、docker logs コマンドに --since オプションで最近 24 時間分のログを取得対象にしているのと、--timestamps オプションでタイムスタンプを出力するようにしています。取得したログは gzip コマンドで圧縮して、<CONTAINER_NAME>-<ID>.log.gz というファイル名で書き出しています。
これを実行すると、例えば以下のように複数の圧縮ログファイルが得られます。
$ ls -l *.log.gz
-rw-r--r--. 1 root root 887 Aug 1 10:22 ke2_jobmngrd.2-34f59028949c.log.gz
-rw-r--r--. 1 root root 1558 Aug 1 10:22 ke2_kengine.2-188b800bdd72.log.gz
-rw-r--r--. 1 root root 1554 Aug 1 10:22 ke2_kengine.2-d84d727936cf.log.gz
-rw-r--r--. 1 root root 1561 Aug 1 10:22 ke2_kengine.2-eb46166069dc.log.gz
-rw-r--r--. 1 root root 1770 Aug 1 10:22 ke2_kengine.2-f5e6171597bd.log.gz
-rw-r--r--. 1 root root 1555 Aug 1 10:22 ke2_kengine.2-f7af3854014b.log.gz
-rw-r--r--. 1 root root 10798 Aug 1 10:22 ke2_kompira.1-01971df8db91.log.gz
-rw-r--r--. 1 root root 3655 Aug 1 10:22 ke2_nginx.1-6b9aa454d7d6.log.gz
-rw-r--r--. 1 root root 7815 Aug 1 10:22 ke2_rabbitmq.1-2704436f57df.log.gz
※ コンテナ名の部分はシステム構成によって変わります。また、kompira 以外のコンテナを動作させている場合は、そのログも出力されることに注意してください。
サービスログ管理
Docker Swarm クラスタ構成では docker service logs コマンドを用いることで、全てのノードからサービス単位(同じコンテナの集まり)のログをまとめて確認することができます。
$ docker service logs [OPTIONS] サービス名
このときサービス名を指定する必要がありますが、以下のコマンドでサービス名の一覧を確認することができます。
# コマンド形式: [いずれかのホスト]$ docker service ls --format "{{.Name}}"
$ docker service ls --format "{{.Name}}"
ke2_jobmngrd
ke2_kengine
ke2_kompira
ke2_nginx
ke2_rabbitmq
ke2_redis
サービスのログ表示コマンドの使い方についてはマニュアルを参照してください。
$ man docker-service-logs
以下では、よくある使い方をいくつか紹介します。
最新 N 行分のログ確認
サービス名を指定すると全てのノードのログを取得できますが、分量が多すぎる場合があります。 最新のいくつかのログだけ確認したい場合は、-n オプションで各ノードから取得する行数を指定することができます。
# コマンド形式: [いずれかのホスト]$ docker service logs <SERVICE_NAME> -n <LINE_COUNT>
# <SERVICE_NAME> : 対象のサービス名
# <LINE_COUNT>: 取得したい最新のログの行数
$ docker service logs ke2_rabbitmq -n 5
ke2_rabbitmq.2.b609jwku5xyf@ke2-rhel89-swarm-3 | 2024-10-10 08:53:47.285515+09:00 [notice] <0.86.0> alarm_handler: {set,{system_memory_high_watermark,[]}}
ke2_rabbitmq.1.5p18r2gjy2go@ke2-rhel89-swarm-2 | 2024-10-08 15:50:27.468114+09:00 [info] <0.369961.0> closing AMQP connection <0.369961.0> (10.0.1.24:37178 -> 10.0.1.9:5672, vhost: '/', user: 'guest')
ke2_rabbitmq.1.5p18r2gjy2go@ke2-rhel89-swarm-1 | 2024-10-08 15:50:39.421148+09:00 [info] <0.370010.0> accepting AMQP connection <0.370010.0> (10.0.1.24:57152 -> 10.0.1.9:5672)
ke2_rabbitmq.1.5p18r2gjy2go@ke2-rhel89-swarm-2 | 2024-10-08 15:50:39.466520+09:00 [info] <0.370010.0> closing AMQP connection <0.370010.0> (10.0.1.24:57152 -> 10.0.1.9:5672, vhost: '/', user: 'guest')
ke2_rabbitmq.2.b609jwku5xyf@ke2-rhel89-swarm-3 | 2024-10-10 08:57:47.297798+09:00 [notice] <0.86.0> alarm_handler: {clear,system_memory_high_watermark}
ke2_rabbitmq.2.b609jwku5xyf@ke2-rhel89-swarm-3 | 2024-10-10 08:59:47.304665+09:00 [notice] <0.86.0> alarm_handler: {set,{system_memory_high_watermark,[]}}
継続したログ確認
動作中のサービスのログを継続的に確認したい場合は、-f オプションを指定してみてください。
# [いずれかのホスト]$ docker service logs <SERVICE_NAME> -n <LINE_COUNT> -f
# 例: docker service logs ke2_rabbitmq -f
# 例: docker service logs ke2_rabbitmq -n 10 -f
$ docker service logs ke2_rabbitmq -n 5 -f
ke2_rabbitmq.2.b609jwku5xyf@ke2-rhel89-swarm-3 | 2024-10-10 08:53:47.285515+09:00 [notice] <0.86.0> alarm_handler: {set,{system_memory_high_watermark,[]}}
ke2_rabbitmq.1.5p18r2gjy2go@ke2-rhel89-swarm-2 | 2024-10-08 15:50:27.468114+09:00 [info] <0.369961.0> closing AMQP connection <0.369961.0> (10.0.1.24:37178 -> 10.0.1.9:5672, vhost: '/', user: 'guest')
ke2_rabbitmq.1.5p18r2gjy2go@ke2-rhel89-swarm-1 | 2024-10-08 15:50:39.421148+09:00 [info] <0.370010.0> accepting AMQP connection <0.370010.0> (10.0.1.24:57152 -> 10.0.1.9:5672)
ke2_rabbitmq.1.5p18r2gjy2go@ke2-rhel89-swarm-2 | 2024-10-08 15:50:39.466520+09:00 [info] <0.370010.0> closing AMQP connection <0.370010.0> (10.0.1.24:57152 -> 10.0.1.9:5672, vhost: '/', user: 'guest')
ke2_rabbitmq.2.b609jwku5xyf@ke2-rhel89-swarm-3 | 2024-10-10 08:57:47.297798+09:00 [notice] <0.86.0> alarm_handler: {clear,system_memory_high_watermark}
ke2_rabbitmq.2.b609jwku5xyf@ke2-rhel89-swarm-3 | 2024-10-10 08:59:47.304665+09:00 [notice] <0.86.0> alarm_handler: {set,{system_memory_high_watermark,[]}}
.....
.....
.....
※ CTRL+C で中止できます
タイムスタンプを指定したログ確認
過去の特定時間帯のログを確認したい場合は、タイムスタンプを指定してログを取得することもできます。
# [いずれかのホスト]$ docker service logs <SERVICE_NAME> --since <TIMESTAMP>
# <TIMESTAMP>: Show logs since timestamp (e.g. "2013-01-02T13:23:37Z") or relative (e.g. "42m" for 42 minutes)
$ docker service logs ke2_kengine --since 1m
ke2_kengine.1.md96z16qsvx2@ke2-rhel89-swarm-2 | [2024-10-10 10:46:00,005:ke-ke2-rhel89-swarm-2:kompirad:ThreadPoolExecutor-1_1] INFO: [Engine-4705] scheduled job 'プロセス生死監視' starting ...
ke2_kengine.1.md96z16qsvx2@ke2-rhel89-swarm-2 | [2024-10-10 10:46:00,015:ke-ke2-rhel89-swarm-2:Executor-0:ActorHandler] INFO: [Executor-0] execute jobflow "/user/app/AlertAutomatic/Definitions/Jobflows/SystemCtrl/MonitoringProcess" by user "root"
ke2_kengine.1.md96z16qsvx2@ke2-rhel89-swarm-2 | [2024-10-10 10:46:00,028:ke-ke2-rhel89-swarm-2:Executor-0:ActorHandler] INFO: Process(90175).start: started /user/app/AlertAutomatic/Definitions/Jobflows/SystemCtrl/MonitoringProcess (invoker=None)
ke2_kengine.1.md96z16qsvx2@ke2-rhel89-swarm-2 | [2024-10-10 10:46:00,931:ke-ke2-rhel89-swarm-2:Executor-0:MainThread] INFO: Process(90175).done: finished /user/app/AlertAutomatic/Definitions/Jobflows/SystemCtrl/MonitoringProcess [DONE] elapsed=0:00:00.902761
ke2_kengine.1.md96z16qsvx2@ke2-rhel89-swarm-2 | [2024-10-10 10:46:00,947:ke-ke2-rhel89-swarm-2:Executor-0:MainThread] WARNING: /process/id_90175.monitor: could not send mail: recipient email is not specified
ボリュームログ管理
docker はボリュームという機能でホストとコンテナ間でファイルを共有することができます。 KE2.0 ではこれを利用して、一部のコンテナでログをボリュームに記録している場合があります。
プロセスログおよび監査ログの記録場所
シングル構成ではプロセスログおよび監査ログは docker の kompira_log ボリュームに記録されます。
docker ボリュームがホスト上のどこに配置されているかは、docker volume ls コマンドで知ることができます。
例えば以下のようにコマンドを実行することで kompira_log のサーバ上での場所が分かります。
$ docker volume ls -f name=kompira_log --format="{{.Mountpoint}}"
/var/lib/docker/volumes/ke2_kompira_log/_data
docker volume コマンドで表示されたディレクトリを確認すると、プロセスログおよび監査ログが記録されているはずです。
$ sudo ls -l /var/lib/docker/volumes/ke2_kompira_log/_data
合計 4
-rw-r--r--. 1 root root 0 7月 24 11:44 audit-ap-ke2-server1.log
-rw-r--r--. 1 root root 3668 7月 24 11:44 audit-ke-ke2-server1.log
-rw-r--r--. 1 root root 0 7月 24 11:44 process-ke-ke2-server1-0.log
-rw-r--r--. 1 root root 0 7月 24 11:44 process-ke-ke2-server1-1.log
ただし、デプロイ時に環境変数 KOMPIRA_LOG_DIR でログの出力先を指定している場合は、kompira_log ボリュームではなく指定したディレクトリに記録されます。
また、Swarm クラスタ構成では setup_stack.sh 実行時に指定した共有ディレクトリ (SHARED_DIR) 配下の $SHARED_DIR/log がデフォルトの KOMPIRA_LOG_DIR となり、そこにログが記録されます。
プロセスログ管理
ジョブフロー実行時のプロセスログは、kengine コンテナが直接ログファイルとして記録を行なっています。
プロセスログは Docker のデフォルトでは kompira_log ボリュームに記録されます。または、デプロイ時に環境変数
KOMPIRA_LOG_DIR が指定されていれば、ホスト上のそのディレクトリに記録されます。
作成されるログファイル名は以下のようになります。
process-<CONTAINER_NAME>-<EXECUTOR_ID>.log
<CONTAINER_NAME>の部分はログを記録するコンテナの名称に展開されます。<EXECUTOR_ID>の部分は kengine 内部で動作しているエグゼキュータの ID に展開されます。
kompira_log ボリュームに記録されたプロセスログファイルの確認方法については、ボリュームログ管理 を参照してください。
監査ログ管理
ユーザが Kompira に対して各種操作をしたときに、その操作の種類や、認可されたかどうか、また成功したかどうか、といった情報をログに記録します。
実際に記録される監査ログファイルの仕様については 監査ログファイル を参照してください。
監査ログの対象となる操作
ブラウザでの操作や API を用いた連携操作、サーバ上の管理コマンドによる操作などが監査ログの記録対象となります。
一方で、以下については、監査ログの記録対象となりません。
- ジョブフロー動作によるデータ操作やプロセス操作
- Kompira システム外部での操作(DB管理コマンドを用いた直接的なデータ操作など)
- static コンテンツへのアクセス
操作レベルと記録レベル
ある記録対象の操作が監査ログに実際に記録されるかどうかは、その操作の種類や結果から算出される「操作レベル値」と、設定項目である「記録レベル値」によって決まります。算出された操作レベル値が設定項目の記録レベル値以上のとき、監査ログに当該エントリが出力されます。
監査ログの記録条件: 操作レベル値 ≧ 記録レベル値
操作レベル値は操作における複数の項目から算出します。いくつかの項目ごとに設定された操作レベルの基準値が決まり、その最大値が最終的な操作レベル値となります。通常この値は 1 から 3 の間の数値となります。各項目の操作レベル基準値のデフォルトについては 監査ログの項目詳細 を参照してください。
たとえば、「ブラウザ上で既存のジョブフローオブジェクトを編集した(許可され、成功した)」という場合、以下のような項目ごとの操作レベル基準値が適用されて、最終的な操作レベル値は 2 となります。
| 項目 | 値 | 操作レベル(基準値) |
|---|---|---|
interface | "web" | 1 |
class | "object" | 1 |
type | "update" | 2 |
permit | "allowed" | 1 |
result | "succeeded" | 1 |
記録レベル値のデフォルトは 2 です。詳細については 監査ログの設定 を参照してください。
監査ログファイル
ここでは監査ログファイルの仕様について示します。
監査ログの記録先
ke2-docker パッケージで KE2.0 システムを構築する場合、監査ログファイルは Docker の kompira_log ボリュームに記録されます。
または、デプロイ時に環境変数 KOMPIRA_LOG_DIR が指定されていれば、ホスト上のそのディレクトリに記録されます。
作成されるログファイル名は以下のようになります。
audit-${CONTAINERNAME}.log
${CONTAINERNAME}の部分はログを記録するコンテナの名称に展開されます。
kompira_log ボリュームに記録された監査ログファイルの確認方法については、ボリュームログ管理 を参照してください。
監査ログのファイル形式
監査ログは UTF-8 でエンコードされたテキストファイルで、1エントリを1行の JSON 形式で出力します。
監査ログの記録項目
| 項目 | 名称 | 形式 | 説明 |
|---|---|---|---|
| 操作レベル | level | 整数 | 操作レベル値 |
| 操作開始日時 | started | 日時 | 操作を開始した日時 |
| 操作終了日時 | finished | 日時 | 操作が終了した日時 |
| 操作元情報 | exec | 辞書 | 操作元 Linux プロセスの情報(辞書形式) |
| 操作ユーザ | user | 文字列 | 操作した Kompira ユーザ名 |
| 操作方式 | interface | 文字列 | ブラウザによる操作か管理コマンドによる操作かなどの区別 |
| 操作分類 | class | 文字列 | セッション操作やオブジェクト操作などの区分 |
| 操作対象 | target_path | 文字列 | オブジェクトパス(セッション操作以外の時) |
target_type | 文字列 | 型オブジェクト(オブジェクト操作時) | |
| 操作種別 | type | 文字列 | 「参照」や「削除」など操作の種類を示す区分 |
| 操作認否 | permit | 文字列 | 操作が「許可」または「拒否」されたかを示す区分 |
| 操作成否 | result | 文字列 | 操作が「成功」または「失敗」したかの記録 |
| 結果理由 | reason | 文字列 | 失敗の場合の原因(原因が分かる場合) |
| 詳細情報 | detail | 辞書 | 操作に関する詳細情報(操作ごとに異なる辞書形式) |
監査ログのサンプル
以下にブラウザで操作したときの監査ログファイル /var/log/kompira/audit-apache.log のサンプルを示します。ログは1エントリ1行で出力されていますが、ここでは分かりやすく整形して表示しています。
{
"level": 3,
"started": "2021-10-05T15:51:31.403016+09:00",
"finished": "2021-10-05T15:51:31.452097+09:00",
"exec": {
"pid": 1286192,
"name": "/usr/sbin/httpd",
"user": "apache",
"remote": "10.10.0.110"
},
"user": "root",
"interface": "web",
"class": "session",
"target_path": null,
"target_type": null,
"type": "login",
"permit": "allowed",
"result": "succeeded",
"reason": null,
"detail": {
"next_page": "/"
}
}
{
"level": 2,
"started": "2021-10-05T15:51:43.447941+09:00",
"finished": "2021-10-05T15:51:43.486984+09:00",
"exec": {
"pid": 1285426,
"name": "/usr/sbin/httpd",
"user": "apache",
"remote": "10.10.0.110"
},
"user": "root",
"interface": "web",
"class": "object",
"target_path": "/config/license",
"target_type": "/system/types/License",
"type": "read",
"permit": "allowed",
"result": "succeeded",
"reason": null,
"detail": {
"http_method": "GET",
"http_status": 200
}
}
監査ログの項目詳細
ここでは、監査ログに記録される項目についての詳細を示します。 以下の節におけるテーブルで「操作レベル」は、操作レベル基準値のデフォルトを示しています。
操作レベル (level)
操作の内容や結果によって算出された操作レベルを数値で示します。この操作レベル値が設定項目の記録レベル値以上のとき、監査ログに当該エントリが出力されます。
操作日時 (started, finished)
項目 started は操作の開始日時を、項目 finished は操作の終了日時を示します。
これらは以下のように、ローカルタイムで ISO8601 形式で記録されます。
"2021-10-01T11:45:08.977356+09:00"
操作元情報 (exec)
操作元を示す辞書には以下のような情報が記録されます。
| 項目 | 名称 | 形式 | 説明 |
|---|---|---|---|
| 操作元プロセスID | exec["pid"] | 整数 | Kompiraサーバ上の処理プロセスID |
| 操作元プロセス名 | exec["name"] | 文字列 | Kompiraサーバ上の処理プロセス名 |
| 操作元ユーザ名 | exec["user"] | 文字列 | Kompiraサーバ上の処理プロセスの実行ユーザ名 |
| 操作元アドレス | exec["remote"] | 文字列 | 操作元のIPアドレス(ブラウザ操作の場合) |
操作ユーザ (user)
操作を行った Kompira ユーザ名を記録します。ブラウザ上で Kompira にログインして操作をした場合は、そのログインユーザ名となります。サーバのコンソール上で管理コマンドによる操作を行なった場合などでは、Kompira の認証を伴っていないため空文字列になります。
操作方式 (interface)
どのような方式を用いて操作したのかの区分を記録します。
| 値 | 操作レベル | 説明 |
|---|---|---|
"web" | 1 | Webブラウザによる操作 |
"api" | 1 | REST-API による操作 |
"mng" | 2 | 管理コマンド(manage.py など)による操作 |
操作分類 (class)
何を操作したのか、その分類を示します。
| 値 | 操作レベル | 説明 |
|---|---|---|
"session" | 3 | セッション操作(ログイン・ログアウト) |
"user" | 3 | ユーザ情報操作(ユーザ追加・削除、パスワード変更など) |
"group" | 3 | グループ情報操作 |
"object" | 1 | オブジェクト操作 |
"task" | 1 | タスク操作 |
"incident" | 1 | インシデント操作 |
"process" | 1 | プロセス操作 |
"schedule" | 1 | スケジュール操作 |
"packages" | 1 | システムパッケージ情報操作 |
操作対象 (target_path, target_type)
何を操作したのか、その具体的な対象を示します。
操作分類が session 以外のときは、操作対象をそのパスで識別することができます。以下のようにパスを項目 target_path として記録します。
"/system/user/id_1"
さらに、オブジェクト操作の場合では、その型オブジェクトのパスを項目 target_type に記録します。
"/system/types/Directory"
操作種別 (type)
どのような操作をしたのかという種類を記録します。
| 値 | 操作レベル | 操作例 |
|---|---|---|
"login" | 3 | ログイン |
"logout" | 3 | ログアウト |
"create" | 3 | オブジェクトの新規作成 |
"rename" | 3 | オブジェクトの名称変更 |
"copy" | 3 | オブジェクトのコピー |
"move" | 3 | オブジェクトの移動 |
"export" | 3 | エクスポート |
"import" | 3 | インポート |
"execute" | 3 | ジョブフローやスクリプトジョブの実行 |
"suspend" | 3 | プロセスの停止 |
"resume" | 3 | プロセスの続行 |
"terminate" | 3 | プロセスの中止 |
"read" | 1 | オブジェクトの参照 |
"list" | 1 | オブジェクトの一覧 |
"search" | 1 | オブジェクトの検索 |
"new" | 1 | 新規オブジェクトの編集(作成前) |
"edit" | 1 | 既存オブジェクトの編集(更新前) |
"confirm" | 1 | オブジェクト操作の確認(削除前) |
"update" | 2 | オブジェクトの更新 |
"clear" | 2 | チャネルのメッセージクリアや管理領域のクリア |
"recv" | 2 | チャネルからのメッセージ受信 |
"send" | 2 | チャネルへのメッセージ送信 |
"delete" | 3 | オブジェクトの削除 |
いくつかの操作種別は特定の操作分類でのみ利用されます。たとえばログインやログアウトは操作分類が session のときだけです。
ある操作種別が複数の操作分類で利用される場合はありますが、操作分類ごとに異なる操作レベル基準値を設定することはできません。
操作の結果 (permit, result)
操作の結果としてその認否と成否が記録されます。
項目 permit は操作が許可されたかどうかを示します。例えばオブジェクト操作では設定されたパーミッションによって、操作が許可されたり拒否されたりします。
| 値 | 操作レベル | 説明 |
|---|---|---|
"allowed" | 1 | 操作が許可された |
"denied" | 3 | 操作が拒否された |
項目 result は操作に成功したかどうかを示します。
| 値 | 操作レベル | 説明 |
|---|---|---|
"succeeded" | 1 | 操作に成功した |
"failed" | 1 | 操作に失敗した |
詳細情報 (detail)
操作ごとに追加の詳細情報を辞書形式で記録します。
※ 詳細情報については、監査ログ機能がリリースされた後も仕様が調整される可能性がありますのでご注意ください。
ログイン
| 項目 | 説明 |
|---|---|
next_page | ログイン後に遷移するページ |
invalid_password | 不正パスワード(認証エラー時) |
REST-API
| 項目 | 説明 |
|---|---|
invalid_token | 不正APIトークン(認証エラー時) |
エクスポート
| 項目 | 説明 |
|---|---|
export_format | エクスポート形式('json' or 'dir') |
export_options | エクスポート時に指定したオプション |
export_paths | エクスポート対象のパス |
export_counters | エクスポート結果のカウンタ情報 |
インポート
| 項目 | 説明 |
|---|---|
import_format | インポート形式('json' or 'dir') |
import_options | インポート時に指定したオプション |
import_sources | インポートしたファイル名 |
import_counters | インポート結果のカウンタ情報 |
オブジェクトの検索
| 項目 | 説明 |
|---|---|
search_params | 検索パラメータ |
オブジェクトの新規作成
| 項目 | 説明 |
|---|---|
create_name | 新規作成するオブジェクトの名称 |
create_type | 新規作成するオブジェクトの型オブジェクトのパス |
ジョブフローやスクリプトジョブの実行
| 項目 | 説明 |
|---|---|
execute_pid | 実行したプロセスID |
execute_params | 実行時に指定したパラメータ |
execute_form | 実行に利用したフォームのパス(フォームから実行した場合) |
execute_table | 実行に利用したテーブルのパス(テーブルから実行した場合) |
オブジェクトの名称変更
| 項目 | 説明 |
|---|---|
rename_to | 変更する名前 |
オブジェクトのコピー
| 項目 | 説明 |
|---|---|
copy_objects | コピー元オブジェクトのリスト |
copy_rename | コピー時に指定したオブジェクトの名称 |
オブジェクトの移動
| 項目 | 説明 |
|---|---|
move_objects | 移動元オブジェクトのリスト |
move_rename | 移動時に指定したオブジェクトの名称 |
オブジェクトの削除
| 項目 | 説明 |
|---|---|
delete_objects | 削除したパスまたはオブジェクトIDのリスト |
delete_file | 削除した添付ファイルのファイル名 |
チャネルへのメッセージ送信
| 項目 | 説明 |
|---|---|
send_form | 送信に利用したフォームのパス(フォームから送信した場合) |
管理コマンド: compile_jobflow / compile_library
| 項目 | 説明 |
|---|---|
compile_paths | コンパイル対象として指定したパスのリスト |
compile_result | コンパイル結果(個数情報) |
管理コマンド: license_info / license_update
| 項目 | 説明 |
|---|---|
license_id | ライセンスID |
license_path | 導入したライセンスファイル名(license_update した場合) |
管理コマンド: process
| 項目 | 説明 |
|---|---|
process_query | プロセスオブジェクトの検索クエリ |
process_count | 検索されたプロセスの個数 |
process_listed | 表示したプロセスの個数 |
process_deleted | 削除したプロセスの個数 |
process_terminated | 終了させたプロセスの個数 |
process_suspended | 停止させたプロセスの個数 |
process_resumed | 続行させたプロセスの個数 |
その他の詳細情報
| 項目 | 説明 |
|---|---|
http_method | HTTP 操作時のメソッド名 |
http_status | HTTP 操作時のステータスコード |
target_attr | 操作対象の属性名 |
target_index | 操作対象のインデックス値 |
bulk_deleted | 一括削除時の詳細情報 |
セキュリティ管理
SSL 証明書管理
KE 2.0 システムでは HTTPS 接続および AMQPS 接続を行なうために、SSL 証明書が必要になります。 ke2-docker パッケージのデプロイ手順では、自己署名 SSL 証明書を作成しています。
注意: 自己署名 SSL 証明書を適用することで暗号化通信には対応していますが、セキュリティ上のリスクがあることは理解しておいてください。特に外部からのアクセスを許可するようなシステム構成の場合には、正式な SSL 証明書の発行と適用を検討してください。
SSL 証明書ファイルの作成
ke2-docker パッケージに付属の create-cert.sh スクリプトを実行すると、自己署名 SSL 証明書を作成します。
$ ../../../scripts/create-cert.sh
ssl ディレクトリに以下のファイルが生成されます。
| ファイル名 | 説明 |
|---|---|
local-ca.crt | 作成する SSL 証明書に署名する CA 証明書 |
local-ca.key | local-ca.crt の秘密鍵ファイル |
local-ca.srl | local-ca.crt で発行済みシリアル番号を保存するファイル |
server.crt | nginx/rabbitmq コンテナが利用するサーバ SSL 証明書(local-ca.crt によって署名されています) |
server.csr | server.crt を生成する時の CSR ファイル |
server.ext | server.crt に設定する拡張情報ファイル |
server.key | server.crt の秘密鍵ファイル |
- create-cert.sh は rabbitmq コンテナに含まれる openssl コマンドを利用して、自己署名 SSL 証明書を作成しています。
- create-cert.sh で作成される CA 証明書および SSL 証明書の、秘密鍵種別は RSA (2048bit)、有効期間は 3650 日です。
- サーバ証明書 server.crt の Common Name (CN) および Subject Alternative Names (SANs) には、create-cert.sh スクリプトを実行したホストの hostname コマンドで取得したホスト名が設定されます。
各コンテナでの SSL 証明書の適用
ke2-docker でデプロイした各コンテナについては、create-cert.sh スクリプトで作成した SSL 証明書 (server.crt) を適用するように設定を行なっています。 各コンテナでの設定内容は以下のようになっています。
nginx コンテナ
nginx コンテナでは、SSL 証明書を利用した HTTPS 接続ができるように、以下のような設定を行なっています。
- SSL証明書ファイル一式を nginx コンテナの
/etc/nginx/sslディレクトリにバインドするようにしています。 /etc/nginx/sslに配置された SSL 証明書を利用するように、ke2-docker 付属の nginx.conf で設定しています。
rabbitmq コンテナ
rabbitmq コンテナでは、SSL 証明書を利用した AMQPS 接続ができるように、以下のような設定を行なっています。
- 起動時に、SSL証明書ファイル一式を rabbitmq コンテナの
/etc/rabbitmq/sslディレクトリにコピーするようにしています。 /etc/rabbitmq/sslに配置された SSL 証明書と CA 証明書を利用するように、ke2-docker 付属の rabbitmq-ssl.conf で設定しています。- rabbitmq-server で SSL 証明書による認証ができるように rabbitmq_auth_mechanism_ssl プラグインを有効化しています。
更新した SSL 証明書の再適用
SSL 証明書ファイル (server.crt) および秘密鍵ファイル (server.key) を更新(上書き)したときは、各コンテナに更新された SSL 証明書を改めて適用する必要があります。
注意: クラスタ構成の場合は、この再適用の手順をすべてのノードで実施してください。
もっとも簡単な方法としてはコンテナの再起動になります。 これはコンテナが起動するたびに、上記の「各コンテナでの SSL 証明書の適用」が更新された SSL 証明書を対象に同様に適用されることを意味しています。
一方で、コンテナを再起動せずに、更新された SSL 証明書を適用させたいという場合もあります。 その場合は、動作中のコンテナごとに SSL 証明書をリロードさせる必要があります。
ke2-docker パッケージに付属の reload-cert.sh スクリプトを実行すると、動作中の各コンテナに対して SSL 証明書のリロードを指示します。 これにより更新された SSL 証明書を適用させることが出来ることになります。
$ ../../../scripts/reload-cert.sh
リロードを指示したあとに、ブラウザでアクセスして SSL 証明書が更新されていることを確認してください(例えば有効期限が伸びているはずです)。
reload-cert.sh スクリプトは 2.0.3.post1 以降で対応しています。
この reload-cert.sh スクリプトが各コンテナごと実施している適用手順について、以下に説明します(reload-cert.sh を利用する場合は、個別の適用手順を実施する必要はありません)。
nginx コンテナ
nginx コンテナに対しては、以下の手順で更新された SSL 証明書を適用することができます。
- nginx コマンドで reload を指示する。
ホスト上で実行するコマンドとしては以下のようになります。
$ docker exec -it $(docker ps -q -f name=nginx) nginx -s reload
rabbitmq コンテナ
rabbitmq コンテナに対しては、以下の手順で更新された SSL 証明書を適用することができます。
- 更新された SSL 証明書を rabbitmq-server/erlang がアクセスできる場所にコピーする。
- erlang が保持している SSL 証明書キャッシュをクリアする。
ホスト上で実行するコマンドとしては以下のようになります。
$ docker exec -it $(docker ps -q -f name=rabbitmq) sh -c "/bin/cp -f -a -r -T /run/.kompira_ssl /etc/rabbitmq/ssl && chown -R rabbitmq:rabbitmq /etc/rabbitmq/ssl"
$ docker exec -it $(docker ps -q -f name=rabbitmq) rabbitmqctl eval "ssl:clear_pem_cache()."
正式な SSL 証明書の適用
「各コンテナでの SSL 証明書の適用」で示したとおり、各コンテナはホストの ssl ディレクトリにある SSL 証明書ファイルを利用するように設定されています。 ke2-docker パッケージのデプロイ手順では自己署名 SSL 証明書を作成していますが、 外部より正式に発行された SSL 証明書ファイルと秘密鍵ファイルを同じ場所に配置してからコンテナを起動すれば、 正式な SSL 証明書を各コンテナに適用できることにもなります。
このとき、正式な SSL 証明書ファイルと秘密鍵ファイルを、ssl ディレクトリに以下のとおり同じ名前で配置する必要があることには注意してください。
| ファイル名 | 説明 |
|---|---|
server.crt | nginx/rabbitmq コンテナが利用する正式に発行された SSL 証明書 |
server.key | 正式に発行された server.crt の秘密鍵ファイル |
正式な SSL 証明書を発行する手続き等については、ご利用になる SSL 証明書発行ベンダーにお問い合わせください。
一例として、無料で利用できる Let's Encrypt による SSL 証明書の発行と適用については、その手順を「Let's Encrypt による SSL 証明書の発行と適用」で紹介します。
独自 CA 証明書の適用
ユーザーの環境によっては、独自の認証局 (CA) によって発行された自己署名 SSL 証明書が適用されたサーバーが運用されていて、コンテナからそのようなサーバーへ HTTPS 接続を行いたいというニーズがあるかもしれません。例えば、ジョブフローで urlopen() を用いてそうしたサーバに (verify=trueで) HTTPS アクセスさせたい、または、自己署名 SSL 証明書で HTTPS 運用しているリポジトリサーバに対してリポジトリオブジェクトを用いて連携したい、などが考えられます。
ですが、自己署名 SSL 証明書で運用しているサーバへの HTTPS アクセス時には、SSL 証明書の検証エラーが起きることが想定されます。 これはセキュリティ上当然の挙動であり、意図されたものです。
その対策としては、各コンテナに独自 CA 証明書を適用しておくことで、その CA で発行された SSL 証明書が適用されたサーバへの HTTPS アクセスにおいて、証明書の検証が正常にパスするようにすることができます。
注意: ただし、一般的にはセキュリティ強度を下げる行為(例えば中間者攻撃のリスクなどが高まる)と捉えられるため、各ユーザ組織におけるセキュリティポリシーと照らし合わせて、リスクを十分に評価し、慎重に検討してください。
その上で、各コンテナに独自 CA 証明書を適用する方法については、以下で説明します。
独自 CA 証明書ファイルの適用手順
「SSL 証明書ファイルの作成」で説明したように、ke2-docker パッケージに付属の create-cert.sh スクリプトを実行すると、ssl ディレクトリに以下のファイルが生成されます。この ssl ディレクトリ内にさらに ca-certificates というディレクトリを作成し、そこに適用したい CA 証明書ファイルを配置してください。このとき CA 証明書ファイルの拡張子は .crt としてください。
ssl/ca-certificatesssl/ca-certificates/*.crt
このように CA 証明書ファイルを配置したうえでコンテナを起動すると、コンテナ内部でここに配置した CA 証明書ファイルを自動的に信頼ストアに取り込みます。
この「独自 CA 証明書ファイルの適用手順」は 2.0.3.post1 以降で対応しています。
注意: この手順はコンテナ起動時の適用にしか対応していません。独自CA証明書を更新した場合はコンテナを再起動してください。
コンテナ起動時の信頼ストアの自動更新
コンテナ起動時の CA 証明書ファイルの信頼ストアへの取り込みは、具体的には内部で以下のような処理を行なっています(ユーザが実行する必要はありません)。
- ホスト上の
ssl/ca-certificates/*.crtに配置された CA 証明書ファイルを、コンテナ内のローカル CA 証明書ディレクトリ/usr/local/share/ca-certificates/にコピーします。 update-ca-certificatesコマンドを実行して、証明書を信頼ストアに追加します。
update-ca-certificates コマンドによって、すべての CA 証明書がマージされた /etc/ssl/certs/ca-certificates.crt というファイルが更新されます。 HTTPS 接続を行なう場面でこの ca-certificates.crt を CA 証明書として利用すれば、追加した独自 CA 証明書によって発行された SSL 証明書を持つサーバへの HTTPS 接続において、証明書の検証がパスすることになります。
先述したジョブフローの urlopen() やリポジトリサーバの連携における HTTPS アクセスでは、内部的に Python の requests モジュールが利用されています。
requests モジュールは環境変数 REQUESTS_CA_BUNDLE で CA 証明書を指定することができるようになっています(参考)。
kompira, kengine, jobmngrd コンテナでは、環境変数 REQUESTS_CA_BUNDLE をデフォルトで /etc/ssl/certs/ca-certificates.crt と設定するようにしています。
これによりこれらのコンテナにおける requests モジュールによる HTTPS アクセスにおいて、独自 CA 証明書ファイルが適用できるようになっています。
Let's Encrypt による SSL 証明書の発行と適用
ここでは Let's Encrypt による SSL 証明書の発行と適用の手順について説明します。
注意: この手順ではインターネットからホストサーバの HTTP 80番ポートにアクセスできる必要がありますので、ご注意ください。
証明書の自動発行のための ACME クライアントとしては、certbot コンテナ を利用します。 なお、certbot の詳細な使い方については本ドキュメントでは省略します。公式ドキュメント を参照してください。
SSL 証明書の発行と適用までの流れは以下のようになります。
- 証明書を配置する ssl ディレクトリ配下に
letsencryptというディレクトリを作成して、そこに ACME クライアントである certbot で SSL 証明書の発行を行ないます。 letsencryptディレクトリ配下に発行された SSL 証明書ファイルと秘密鍵ファイルを、ssl ディレクトリのserver.crtやserver.keyからシンボリックリンクで参照させるようにします。- これにより、各コンテナは Let's Encrypt より発行された SSL 証明書を適用できることになります。
※ 以降の説明で <DOMAIN_NAME> とある部分は SSL 証明書を発行したい対象のドメイン名 (FQDN) に置き換えてください。
SSL 証明書の新規発行
ホストサーバ上で各コンテナが停止している状態で、以下のように certbot を用いてスタンドアローンモードで証明書を発行します。
$ docker run -it --rm -p 80:80 \
-v "$(readlink -m ../../../ssl/letsencrypt/etc):/etc/letsencrypt" \
-v "$(readlink -m ../../../ssl/letsencrypt/var/lib):/var/lib/letsencrypt" \
-v "$(readlink -m ../../../ssl/letsencrypt/var/log):/var/log/letsencrypt" \
certbot/certbot certonly --standalone \
--preferred-challenges=http \
- このときインターネットからホストサーバの HTTP 80番ポートにアクセスできる必要があることに注意してください。
- また、nginx コンテナが起動していると80番ポートを利用していてエラーになるため、すべてのコンテナを停止した状態で実施することをお勧めします。
- 以後のやりとりの詳細は certbot のバージョンによって変わる可能性があります。
certbot certonly コマンドを実行すると、登録するメールアドレスを尋ねられますので入力してください。 メールアドレスの登録をスキップする場合はそのままエンターを押してください(SSL証明書は発行されます)。
Enter email address or hit Enter to skip.
(Enter 'c' to cancel):
ACME サーバーに登録するには利用規約に同意する必要があります。利用規約に同意するかどうかを「Do you agree?」と尋ねていますので、同意する場合は
Y と入力してください。同意しない場合は N と入力してください(SSL証明書は発行されずにコマンドが終了します)。
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Please read the Terms of Service at:
https://letsencrypt.org/documents/LE-SA-v1.5-February-24-2025.pdf
You must agree in order to register with the ACME server. Do you agree?
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
(Y)es/(N)o:
メールアドレスを入力している場合、Certbotを開発している非営利団体である Electronic Frontier Foundation (EFF)
とあなたのメールアドレスを共有してもよいかを尋ねていますので、同意する場合は Y と入力してください。共有を望まない場合は N
と入力してください(SSL証明書は発行されます)。
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Would you be willing, once your first certificate is successfully issued, to
share your email address with the Electronic Frontier Foundation, a founding
partner of the Let's Encrypt project and the non-profit organization that
develops Certbot? We'd like to send you email about our work encrypting the web,
EFF news, campaigns, and ways to support digital freedom.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
(Y)es/(N)o:
最後に SSL 証明書を発行する対象のドメイン名を尋ねられますので入力してください。
Please enter the domain name(s) you would like on your certificate (comma and/or
space separated) (Enter 'c' to cancel):
ここまでの入力が完了すると SSL 証明書の発行手続きが開始されます。無事に SSL 証明書が発行されると、証明書が fullchain.pem に、秘密鍵が privkey.pem に保存されます。
Requesting a certificate for <DOMAIN_NAME>
Successfully received certificate.
Certificate is saved at: /etc/letsencrypt/live/<DOMAIN_NAME>/fullchain.pem
Key is saved at: /etc/letsencrypt/live/<DOMAIN_NAME>/privkey.pem
This certificate expires on YYYY-MM-DD.
These files will be updated when the certificate renews.
NEXT STEPS:
- The certificate will need to be renewed before it expires. Certbot can automatically renew the certificate in the background, but you may need to take steps to enable that functionality. See https://certbot.org/renewal-setup for instructions.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
If you like Certbot, please consider supporting our work by:
* Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate
* Donating to EFF: https://eff.org/donate-le
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
なお、上記のような入力・確認手順を省略したい場合は、certbot certonly コマンドに例えば以下のようにオプションを追加して実行してください。
--agree-tos --no-eff-email -m "<EMAIL_ADDRESS>" -d "<DOMAIN_NAME>"
これらのオプションは以下を意味します。また、メールアドレスやドメイン名は実際の値に置き換えてください。
--agree-tos: 利用規約に合意する--no-eff-email: EFF にメールアドレスは共有しない-m: メールアドレスの指定(<EMAIL_ADDRESS>の部分は実際のメールアドレスに置き換えてください)-d: ドメイン名の指定(<DOMAIN_NAME>の部分は実際のドメイン名に置き換えてください)
SSL 証明書の適用
certbot で Let's Encrypt より SSL 証明書の発行に成功した場合、letsencrypt/etc/live/<DOMAIN_NAME>/
ディレクトリ配下に SSL 証明書と秘密鍵ファイルが保存されています。これらのファイルを nginx/rabbitmq
コンテナから参照できるように、以下のようにシンボリックリンクを張ります。
$ ln -s -f ./letsencrypt/etc/live/<DOMAIN_NAME>/fullchain.pem ../../../ssl/server.crt
$ ln -s -f ./letsencrypt/etc/live/<DOMAIN_NAME>/privkey.pem ../../../ssl/server.key
注意: ここで、既存の SSL 証明書と秘密鍵をシンボリックリンクで置き換えていることに注意してください。既存のファイルを残しておきたい場合は、事前に別の場所にバックアップするなどしてください。
各コンテナを起動すると Let's Encrypt より発行された SSL 証明書が適用されているはずですので、Web ブラウザで kompira サーバに HTTPS アクセスして確認してみてください。
なお、この手順は初回発行時に必要になりますが、以下で説明する「SSL 証明書の更新」の際には不要です。
SSL 証明書の更新
SSL 証明書には有効期限があり(Let's Encrypt の場合は通常 90 日間)、有効期限が切れる前に更新する必要があります。 certbot には発行済みの SSL 証明書を更新する renew というコマンドがあり、以下のように certbot コンテナを利用して SSL 証明書を更新することができます。
$ docker run -it --rm \
-v "$(readlink -m ../../../ssl/letsencrypt/etc):/etc/letsencrypt" \
-v "$(readlink -m ../../../ssl/letsencrypt/var/lib):/var/lib/letsencrypt" \
-v "$(readlink -m ../../../ssl/letsencrypt/var/log):/var/log/letsencrypt" \
certbot/certbot renew
重要: これでホスト上の SSL 証明書ファイルと秘密鍵ファイルは更新されますが、各コンテナに対して「更新した SSL 証明書の再適用」を実施することを忘れないようにしてください。
なお、certbot で SSL 証明書を更新しようとしても、現在適用している SSL 証明書の有効期限がまだ十分に(30日以上)残っているときは、以下のように
Certificate not yet due for renewal というメッセージが表示されて SSL 証明書の更新はスキップされます。
:
Processing
/etc/letsencrypt/renewal/<DOMAIN_NAME>
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Certificate not yet due for renewal
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
The following certificates are not due for renewal yet:
/etc/letsencrypt/live/<DOMAIN_NAME>/fullchain.pem expires on 2025-07-29 (skipped)
No renewals were attempted.
有効期限が残っていても SSL 証明書を強制的に更新したいときは、certbot に --force-renewal オプションを付けて実行してください。
$ docker run -it --rm \
-v "$(readlink -m ../../../ssl/letsencrypt/etc):/etc/letsencrypt" \
-v "$(readlink -m ../../../ssl/letsencrypt/var/lib):/var/lib/letsencrypt" \
-v "$(readlink -m ../../../ssl/letsencrypt/var/log):/var/log/letsencrypt" \
certbot/certbot renew --force-renewal
暗号化秘密鍵の管理
パスワードフィールドの暗号化には暗号化秘密鍵が必要になります。 この暗号化秘密鍵はシステムの初回起動時にランダムに自動生成されて秘密鍵ファイルに記録されています。
ここでは、この秘密鍵の管理手順について示します。
秘密鍵の変更
パスワードフィールドの暗号化に使用する秘密鍵を変更するには、管理コマンド manage.py change_secretkey を実行したあとに、kompira および kengine コンテナを再起動します。
注意: 秘密鍵を変更した後は kompira および kengine コンテナを再起動する必要があります。そのため、実行中のジョブフローがある場合は全て異常終了することに注意してください。可能であれば実行中のジョブフローが存在しないときに実施するようにしてください。
change_secretkey の実行
change_secretkey を実行すると、データベースに暗号化されて保存されている全てのパスワードデータを、新しい秘密鍵で再暗号化して保存し直します。
change_secretkey コマンドの形式は以下の通りです。新しい秘密鍵は文字列で <NEW_SECRETKEY> の部分に指定してください。
$ docker exec $(docker ps -q -f name=kompira) manage.py change_secretkey [options...] <NEW_SECRETKEY>
change_secretkey コマンドには以下のオプションがあります。
| オプション | 説明 |
|---|---|
--no-backup | 変更前の鍵をバックアップしません。 |
--force | 途中で再暗号化に失敗したパスワードデータがあっても、再暗号化を続行します。 |
注釈: 秘密鍵の文字列はコンテナから見える
/var/opt/kompira/.secret_keyに保存されますが、ホスト上では構成によって異なるパスに存在することになります。
秘密鍵変更後のコンテナ再起動
秘密鍵を変更した後は、kompira および kengine コンテナを再起動してください。 この手順を実行すると kengine コンテナが再起動するため、実行中のジョブフローは全て異常終了することに注意してください。
シングル構成の場合
シングル構成においては、以下の手順で kompira, kengine コンテナを再起動してください。
$ docker restart $(docker ps -q -f name=kompira -f name=kengine)
クラスタ構成の場合
Swarm クラスタ構成においては、いずれかの Swarm マネージャノード上で、以下の手順で全ノードの kompira, kengine コンテナを再起動してください。
[ke2-server1]$ docker service update --force ke2_kompira
[ke2-server1]$ docker service update --force ke2_kengine
資格情報管理
KE2.0 システムで利用する各種ユーザ名・パスワード(資格情報)の管理について示します。
KE2.0 を構成する各サービス(PostgreSQL / RabbitMQ)には、それぞれ独立した認証情報が存在します。ke2-docker で初期構築するときのデフォルト値は互換性のための仮の値であり、本番運用前に必ず変更してください。本章では、各構成での資格情報の所在、設定方法、変更手順、および本番運用前に確認すべきチェックリストを示します。
注: 本ページは現時点で
single/basic/single/extdb/cluster/swarmおよび外部連携 (extra/jobmngrd,kompira_sendevt) 構成を対象としています。cloud/azureci構成は別途の追加リリースで案内予定です。
1. 資格情報の所在マップ
ke2-docker で構成する KE2.0 が扱う主な資格情報と、構成パターンごとの所在を以下に示します。
| 資格情報 | single/basic | single/extdb | cluster/swarm |
|---|---|---|---|
| KE2.0 の root アカウント | UI で変更(全構成共通) | 同左 | 同左 |
Kompira 接続ユーザ(PostgreSQL の kompira) | 環境変数 DATABASE_USER / DATABASE_PASSWORD / DATABASE_NAME | 環境変数 DATABASE_URL で直接指定(必須) | setup_stack.sh の DATABASE_URL で直接指定(Pgpool VIP 経由) |
| RabbitMQ の内部接続ユーザ | 環境変数 AMQP_USER / AMQP_PASSWORD(既定 guest / guest) | 同左 | setup_stack.sh の環境変数 AMQP_USER / AMQP_PASSWORD(既定 guest / guest) |
| RabbitMQ の外部接続ユーザ | rabbitmqctl add_user で別途追加 | 同左 | 同左 |
| Pgpool / レプリ系ユーザ | — | — | setup_pgpool.sh の既定(kompira / pgpool / postgres / repl) |
暗号化秘密鍵 (.secret_key) | コンテナ内 /var/opt/kompira/.secret_key に保存(暗号化秘密鍵の管理 を参照) | 同左 | 共有ディレクトリ ${SHARED_DIR}/var/.secret_key |
| SSL 証明書 | ssl/ ディレクトリ(SSL 証明書の管理 を参照) | 同左 | 共有ディレクトリ ${SHARED_DIR}/ssl |
2. 初期セットアップ時の指定方法
2.1 single/basic 構成
内部 postgres / rabbitmq コンテナを含むオールインワン構成です。DATABASE_USER / DATABASE_PASSWORD / DATABASE_NAME / AMQP_USER / AMQP_PASSWORD を環境変数で指定すると、ke2-docker の compose ファイルがそれらの値を:
POSTGRES_USER/POSTGRES_PASSWORD/POSTGRES_DB(postgres コンテナの初期化)RABBITMQ_DEFAULT_USER/RABBITMQ_DEFAULT_PASS(rabbitmq コンテナの初期化)DATABASE_URL/AMQP_URL(kompira / kengine / jobmngrd の接続情報)
すべてに反映します。
$ cd ke2/single/basic
$ DATABASE_PASSWORD='<DB_PASSWORD>' AMQP_PASSWORD='<AMQP_PASSWORD>' docker compose up -d
注 (変更対象の範囲): 上記の起動例ではパスワードのみを差し替えていますが、
DATABASE_USER/DATABASE_NAME/AMQP_USERの既定値 (kompira/kompira/guest) も同様に環境変数で変更できます。本番運用では §3 のとおり全項目を独自値に変更することを推奨しますが、パスワードのみの変更でも初期セットアップ要件は満たせるため、上記は最小ステップとして示しています。注 (URL 安全でない文字の扱い):
DATABASE_USER/DATABASE_PASSWORD/DATABASE_NAME/AMQP_USER/AMQP_PASSWORDを個別変数で直接指定する場合、いずれの値も RFC 3986 unreserved set (英数字と-_.~) のみ を使用してください (compose が組み立てる URL の userinfo / path に未エンコードのまま埋め込まれるため、パスワード以外の項目も対象)。URL 安全でない文字 (@:/%や空白等) を含む値を使う場合は、パーセントエンコード済みのDATABASE_URL/AMQP_URLを直接指定してください。詳細は §5 URL 安全でない文字を含む資格情報の扱い を参照。
2.2 single/extdb 構成
外部の PostgreSQL を利用する構成です。DATABASE_URL の指定が必須となります。
$ cd ke2/single/extdb
$ DATABASE_URL='pgsql://<DB_USER>:<DB_PASSWORD>@<DB_HOST>:<DB_PORT>/<DB_NAME>' docker compose up -d
DATABASE_URL 未指定で起動すると docker compose config 段階で即エラー停止します。
DATABASE_URLを直接指定する場合は、URL 安全でない文字を含むユーザ名・パスワード・DB 名 (userinfo / path のいずれの部分) もあらかじめ URL エンコードして埋め込む必要があります(後述)。
2.3 cluster/swarm 構成
PostgreSQL/Pgpool-II クラスタを利用する Swarm 構成です。KE2.0 のコンテナ(kompira / kengine / jobmngrd)は Pgpool-II の仮想 IP (VIP) 経由でデータベースに接続します。setup_stack.sh の実行時に、この VIP を指す DATABASE_URL を環境変数で指定します。
注 (データベースクラスタの配置): PostgreSQL/Pgpool-II クラスタは、Swarm ホスト上に同居させる構成(各 Swarm ホストで
setup_pgpool.shを実行)と、Swarm とは別のホスト群に構築する構成(データベース専用ホストでsetup_pgpool.shを実行)のどちらでも構いません(システム設計次第)。いずれの場合も、KE2.0 コンテナから Pgpool VIP に到達できることが前提です。本章で「Pgpool-II ノード」と記す場合は、同居・別居のいずれかにかかわらず Pgpool-II を実行しているホストを指します(資格情報の変更作業はこのホスト上で行います)。
$ cd ke2/cluster/swarm
$ DATABASE_URL='pgsql://<DB_USER>:<DB_PASSWORD>@<PGPOOL_VIP>:9999/<DB_NAME>' SHARED_DIR=/mnt/gluster ./setup_stack.sh
$ docker stack deploy -c docker-swarm.yml ke2
この構成の PostgreSQL/Pgpool-II クラスタ側のユーザ(kompira / pgpool / postgres / repl)のパスワードは、クラスタ構築時に setup_pgpool.sh で設定します。本番運用では初期構築時に強いパスワードを指定してください(環境変数 PG_KOMPIRA_PASS などで指定します。手順は 構築ガイド > Pgpool-II の準備 を参照)。デフォルトのまま構築してしまった場合は、§4.3 の手順で変更してください。
2.4 外部連携構成(extra/jobmngrd / kompira_sendevt)
外部 jobmngrd や kompira_sendevt から KE2.0 本体に AMQPS 接続する場合、KE2.0 側で rabbitmqctl add_user により専用ユーザを事前に追加します。手順は 構築ガイド > 外部連携構成 を参照してください。
3. デフォルト値の一覧
ke2-docker で初期構築するときに環境変数を指定しなかった場合の デフォルト値(仮の値) を以下に示します。これらは互換性のために残されたもので、本番運用ではすべて変更してください(特にパスワード (<DB_PASSWORD> / <AMQP_PASSWORD>) は推測されにくい十分に強いパスワードを設定してください)。
| 環境変数 | デフォルト | 適用先 |
|---|---|---|
DATABASE_USER | kompira | PostgreSQL 接続ユーザ + 内部 postgres の初期ユーザ |
DATABASE_PASSWORD | kompira | 同 パスワード |
DATABASE_NAME | kompira | 同 データベース名 |
AMQP_USER | guest | RabbitMQ 接続ユーザ + 内部 rabbitmq の初期ユーザ |
AMQP_PASSWORD | guest | 同 パスワード |
加えて、cluster/swarm 構成の setup_pgpool.sh は以下のデフォルト値で各種 PostgreSQL ユーザを作成します。本番運用ではこれらも変更必須です。初期構築時に環境変数(PG_KOMPIRA_PASS など)で強いパスワードを指定するのが確実です(構築ガイド > Pgpool-II の準備 参照)。構築後に変更する場合は §4.3 を参照してください。
| ユーザ | パスワード | 用途 |
|---|---|---|
kompira | kompira | Kompira アクセス用 |
pgpool | pgpool | Pgpool-II のレプリ遅延チェック・ヘルスチェック専用 |
postgres | postgres | オンラインリカバリの実行ユーザ |
repl | repl | PostgreSQL レプリケーション専用 |
4. パスワードの変更手順
4.1 KE2.0 root アカウント
ブラウザでログイン後、画面右上のユーザメニューから「パスワード変更」を選択して変更します(または管理画面の「アカウント設定」から)。詳細は アカウント管理 を参照してください。
4.2 Kompira 接続ユーザ(single/basic・single/extdb)
対象構成: 本節は single/basic・single/extdb 構成向けです。cluster/swarm 構成は手順が異なります(Pgpool-II の
pool_passwd同期が必要)ので §4.3 を参照してください。
PostgreSQL 側で Kompira 接続ユーザ(既定 kompira)のパスワードを更新したあと、ke2-docker の接続情報を同期させて kompira / kengine / jobmngrd を再起動します。
注意: 実行中ジョブフローがある場合は kengine 再起動で異常終了するため、可能なら停止状態で実施してください。
# (1) PostgreSQL 側でパスワード変更
# - single/basic の場合: 内部 postgres コンテナに psql で接続して対話的に変更
# <DB_USER> / <DB_NAME> は構成で実際に使っている値に置き換える。
$ docker exec -it $(docker ps -q -f name=postgres) \
psql -U '<DB_USER>' -d '<DB_NAME>' -c '\password <DB_USER>'
# - psql プロンプトでパスワードを 2 回入力。`\password` は対話入力なので
# SQL リテラルとしてのエスケープ (シングルクオート等) は不要。
# - 非対話で実行したい場合は `ALTER USER <DB_USER> WITH PASSWORD '...'` も使えるが、
# 新パスワードに `'` を含む場合は SQL リテラル内で `''` にエスケープする必要がある。
# - single/extdb の場合: 外部 PostgreSQL に直接接続して同様に変更 (\password または ALTER USER)
# (2) ke2-docker の接続情報を更新
# - .env を使っている場合: DATABASE_PASSWORD と DATABASE_URL を新パスワードで書き換え
# - 環境変数を使っている場合: 次回 docker compose up 時に新パスワードを指定
# (3) kompira / kengine / jobmngrd を再起動
$ docker compose up -d --force-recreate kompira kengine jobmngrd
4.3 Pgpool / レプリケーション系ユーザのパスワード変更(swarm 構成)
cluster/swarm 構成の PostgreSQL/Pgpool-II クラスタ側のユーザ(kompira / pgpool / postgres / repl)のパスワードを構築後に変更する手順です。
可能なら初期構築時に設定してください。 クラスタ構築時に
setup_pgpool.shの環境変数(PG_KOMPIRA_PASSなど)で強いパスワードを指定すれば、以下の変更作業は不要になります(構築ガイド > Pgpool-II の準備 参照)。以下は、すでにデフォルト値で構築してしまった場合の変更手順です。
Pgpool-II は、クライアントおよびバックエンドの認証に認証情報ファイル pool_passwd(scram-sha-256 用に AES 暗号化) を使用します。そのため、PostgreSQL 側のパスワードを変更したら、同じ内容を全 Pgpool-II ノードの pool_passwd にも反映しなければなりません。
重要(この 2 つを守らないと認証不能になります):
- PostgreSQL 側(
ALTER USER)と Pgpool-II 側(pool_passwd)は必ずセットで更新する。 片方だけだと、新旧どちらのパスワードでも接続できなくなります。pool_passwdの更新は全ノードで行う。 1 台でも古いままだと、そのノードが担当したときに認証が失敗します。
ここでは例として kompira ユーザのパスワードを変更します(他のユーザも同様の手順です)。
(1) PostgreSQL 側のパスワードを変更する(Pgpool VIP 経由でプライマリに接続します。プライマリに反映すればレプリケーションでスタンバイにも伝播します)。新パスワードをコマンド履歴やプロセス一覧に残さないよう、\password で対話的に設定します(' を含むパスワードでも SQL エスケープが不要で安全です)。
$ psql -h <PGPOOL_VIP> -p 9999 -U postgres
postgres=# \password kompira
# プロンプトに従い新しいパスワードを 2 回入力する
(2) 全 Pgpool-II ノードで pool_passwd を更新する。 各ノードで postgres ユーザとして pg_enc を実行し、プロンプトに新パスワードを入力します(コマンド引数にパスワードを書かないため安全です)。
# 全 Pgpool-II ノードで実行する (同居構成なら各 Swarm ホスト、別居構成なら各 DB ホスト)
$ sudo -u postgres pg_enc -m -k /var/lib/pgsql/.pgpoolkey -u kompira -p
db password: <NEW_PASSWORD を入力>
(3) 全 Pgpool-II ノードで設定を再読み込みする(再起動は不要です)。
# 全 Pgpool-II ノードで実行する (同居構成なら各 Swarm ホスト、別居構成なら各 DB ホスト)
$ sudo systemctl reload pgpool
(4) 変更したユーザに応じた追加作業:
kompira(KE2.0 の Kompira 接続ユーザ): KE2.0 コンテナがこのユーザで DB に接続するため、新パスワードを反映したDATABASE_URLでsetup_stack.shを再実行し、docker stack deploy -c docker-swarm.yml ke2でスタックを再デプロイします。パスワードに URL で安全でない文字を含む場合は §5 に従ってパーセントエンコードしてください。pgpool(Pgpool-II のヘルスチェック/レプリ遅延チェック用): PCP コマンド用の認証ファイルpcp.confも全ノードで更新が必要です。パスワードをコマンド引数に書くとシェル履歴・プロセス一覧に残る(pg_md5自身も引数指定を非推奨としています)ため、pg_md5 -p(プロンプトで新パスワードを入力)の出力を/etc/pgpool-II/pcp.confのpgpool:<md5>行に反映します。repl(レプリケーション専用):replはpool_passwdには含まれません。スタンバイのレプリケーション接続情報(primary_conninfo/.pgpass)の更新が必要になるため、可能な限り初期構築時に設定しておくことを推奨します。
変更後は、§7 のチェックリストや show pool_nodes(全ノードが up)で正常性を確認してください。
4.4 RabbitMQ ユーザ
内部 RabbitMQ の接続ユーザ(既定 guest)のパスワードを変更する手順です。構成により手順が異なります。
single/basic・single/extdb 構成:
# (1) RabbitMQ 側でパスワードを変更
$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl change_password '<AMQP_USER>' '<NEW_PASSWORD>'
# (2) ke2-docker の AMQP_PASSWORD / AMQP_URL を新パスワードで更新したのち、接続側を再起動
$ docker compose up -d --force-recreate kompira kengine jobmngrd
cluster/swarm 構成: RabbitMQ は 3 ノードのクラスタとして動作しますが、ユーザ情報はクラスタ全体で共有されるため、いずれか 1 つの rabbitmq コンテナで変更すれば全ノードに反映されます。そのうえで、各サービスの AMQP_URL を更新するために setup_stack.sh を新パスワードで再実行し、スタックを再デプロイします。
# (1) いずれかの Swarm ホストで RabbitMQ のパスワードを変更 (クラスタ全体に伝播する)
$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl change_password '<AMQP_USER>' '<NEW_PASSWORD>'
# (任意) 各ホストで反映を確認する
$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl authenticate_user '<AMQP_USER>' '<NEW_PASSWORD>'
# (2) AMQP_PASSWORD を新パスワードにして docker-swarm.yml を再生成し、再デプロイする
# (DATABASE_URL / SHARED_DIR などは初期構築時と同じ値を指定する)
$ cd ke2/cluster/swarm
$ AMQP_USER='<AMQP_USER>' AMQP_PASSWORD='<NEW_PASSWORD>' \
DATABASE_URL='pgsql://<DB_USER>:<DB_PASSWORD>@<PGPOOL_VIP>:9999/<DB_NAME>' \
SHARED_DIR=/mnt/gluster ./setup_stack.sh
$ docker stack deploy -c docker-swarm.yml ke2
注: 上記は新パスワードをシングルクオートで囲む形式のため、シェル特殊文字 (
#/ 空白 /$等) を含むパスワードでも安全にコピペできます。ただし新パスワード自体に'(シングルクオート) を含む場合は閉じてしまうため、'\''でエスケープするか、stdin 経由で渡すなど別の手段を使ってください。詳細は §5 シェル例で'を含む値を扱う場合の対処 を参照。
外部接続用に追加したユーザの場合も同様に rabbitmqctl change_password で変更します(この場合 AMQP_URL の更新は不要で、外部接続クライアント側の設定を新パスワードに合わせます)。
5. URL 安全でない文字を含む資格情報の扱い
DATABASE_URL / AMQP_URL に埋め込むユーザ名・パスワード・DB 名 (パス部分) は、いずれも RFC 3986 (URI: Generic Syntax) に従う必要があります。RFC 3986 §2.3 で「unreserved」と定義された英数字および - _ . ~ 以外の文字を含む場合、%XX 形式でパーセントエンコードします。本節はパスワードに限らず、ユーザ名・DB 名にも同様に適用されます (DATABASE_URL / AMQP_URL の userinfo は RFC 3986 §3.2.1、path は §3.3 に従って解釈されます)。
主要文字のエンコード対応表:
| 文字 | エンコード後 | 文字 | エンコード後 |
|---|---|---|---|
@ | %40 | ? | %3F |
: | %3A | # | %23 |
/ | %2F | % | %25 |
+ | %2B | & | %26 |
= | %3D | (空白) | %20 |
実例: 実パスワード p@ss:w0rd を DATABASE_URL に埋め込む場合は、pgsql://user:p%40ss%3Aw0rd@host:5432/db のように p@ss:w0rd → p%40ss%3Aw0rd に変換します。
環境変数別の挙動
| 環境変数 | URL 安全でない文字を含む値の扱い |
|---|---|
DATABASE_USER / DATABASE_PASSWORD / DATABASE_NAME (個別変数経由) | 未エンコードのままだと compose が組み立てる DATABASE_URL が壊れます。RFC 3986 unreserved set (英数字と -_.~) のみを使用してください。URL 安全でない文字を含む値は、パーセントエンコード済みの DATABASE_URL を直接指定してください |
AMQP_USER / AMQP_PASSWORD (個別変数経由) | 上記の DB 系個別変数と同様に compose が組み立てる AMQP_URL に未エンコードのまま埋め込まれるため、unreserved set のみ使用してください。URL 安全でない文字を含む値は、パーセントエンコード済みの AMQP_URL を直接指定してください。この場合、最終的に kompira コンテナ側で正しく解釈させるには コンテナイメージ v2.0.5.post2 以降が必要 です (それ以前は AMQP_URL の userinfo を URL デコードしないため) |
DATABASE_URL / AMQP_URL (直接指定) | URL 安全でない文字を含むユーザ名・パスワード・DB 名はあらかじめパーセントエンコードして埋め込んでください (userinfo / path のいずれの部分も対象)。受け取り側 (django-environ / kompira) が URL デコードして使うため、エンコード済みであれば動作します (AMQP_URL の場合のみコンテナイメージ v2.0.5.post2 以降が必要) |
コンテナイメージのバージョン指定について: 上記表で
AMQP_USER/AMQP_PASSWORD/AMQP_URLの URL 安全でない文字対応に コンテナイメージ v2.0.5.post2 以降が必要 と記載した制約は、デプロイ時に使用するイメージのバージョンが要件を満たしていない場合に発現します。利用イメージのタグ指定方法はKOMPIRA_IMAGE_NAME/KOMPIRA_IMAGE_TAGを参照してください (環境変数リファレンス側に記載されているデフォルトタグの例示値は更新時点で公開されていた値であり、URL 安全でない文字対応の要件を満たすにはKOMPIRA_IMAGE_TAG=2.0.5.post2以降を明示的に指定 する必要があります)。新しいタグに変更したあとはdocker compose pullを再実行してからdocker compose up -dで起動してください。
シェル例で ' を含む値を扱う場合の対処
本マニュアル全体のシェルコマンド例は、値全体をシングルクオートで囲む形 (KEY='<value>' / rabbitmqctl ... '<password>' 等) を採っています。これは # / 空白 / $ / ! 等のシェル特殊文字を含む強パスワードでも安全にコピペできるためですが、値自体に ' (シングルクオート) が含まれる場合は閉じてしまい破綻します。以下のいずれかを利用してください。
'\''でエスケープ: シングルクオートを閉じる ' → \ でエスケープした ' → 開き直す 'の 3 文字'\''で逐次切替する。例: 実パスワードp'ssを埋め込む →'p'\''ss'(シェルで解釈されるとp'ss1 つの文字列)。- パスワード変更時の代替手段:
- PostgreSQL: 上述の
\password <DB_USER>で対話設定する (SQL リテラルとしてのエスケープも不要) - RabbitMQ:
rabbitmqctl change_passwordに標準入力経由で渡すか、いったん別のパスワード (英数字のみ) に変更してから.env経由で目的のパスワードに切り替えるなど
- PostgreSQL: 上述の
.env を source で読み込む場合の注意
.env ファイル内容は set -a; source .env; set +a で読み込むと シェルスクリプトとして評価される ため、内容に任意のシェルコマンドが含まれていれば実行されます。source での読み込みは、自分で作成した、または信頼できる内容の .env のみに対して実行してください。第三者から受け取った .env などは目視確認するか、シェル評価を伴わない読み込み手段 (例: grep '^DATABASE_USER=' .env | cut -d= -f2- などで個別変数を取り出して扱う) を利用してください。
6. PostgreSQL の初回限定挙動と対処(single/basic 構成)
対象構成: 本節は 内部 postgres コンテナを使う single/basic 構成のみに該当します。single/extdb・cluster/swarm 構成では PostgreSQL は ke2-docker の外部(別ホストまたは別途構築した DB クラスタ)にあり、この挙動は発生しません(これらの構成でのパスワード変更は §4.2 / §4.3 を参照)。
PostgreSQL 公式コンテナイメージの POSTGRES_USER / POSTGRES_PASSWORD / POSTGRES_DB 環境変数は initdb 時(データボリュームが空の状態での初回起動時)のみ参照 される仕様です。既存のデータボリュームを残したまま DATABASE_USER / DATABASE_PASSWORD / DATABASE_NAME を変更しても、DB 内のユーザ・パスワード・データベース名は更新されません。
症状
.env や環境変数のパスワードだけ変更してコンテナを再起動した場合、kompira / kengine / jobmngrd のコンテナログに以下のようなエラーが記録されます。
FATAL: password authentication failed for user "kompira"
kengine は再起動ループに入ります。
対処方法
方法 A(推奨・データ保持): ALTER USER で DB 内パスワードを変更
§4.2 Kompira 接続ユーザ の手順に従って、DB 側のパスワードを ALTER USER で変更し、ke2-docker の env / .env を同期します。データはそのまま保持されます。
方法 B(破壊的・テスト環境向け): ボリュームごと完全リセット
開発・テスト環境などデータを破棄してよい場合は、以下のように docker compose down -v で関連ボリュームを削除してから再起動します。
$ docker compose down -v # PostgreSQL データを含むボリュームが削除される
$ docker compose up -d # 新しい DATABASE_PASSWORD で initdb が実行される
警告:
docker compose down -vはすべての関連ボリューム(PostgreSQL データ含む)を削除します。 バックアップなしの本番環境では絶対に実行しないでください。
7. 本番運用前のセキュリティチェックリスト
本番運用を開始する前に、以下の項目を必ず確認してください。
- KE2.0 の root アカウントのパスワードを変更したか
-
PostgreSQL の Kompira 接続ユーザのパスワードを強化したか
- 特に single/extdb・cluster/swarm 構成では必須。これらは PostgreSQL が ke2-docker の外(別ホストや Pgpool-II クラスタ経由)にあり、他システムからアクセスされうるため、弱いパスワードを残すと侵害リスクが高まる(swarm は DB を Swarm ホストに同居させる構成でも、コンテナ外からの到達性がある点は同様)
- single/basic 構成では postgres コンテナがホスト外に公開されないため重要度は下がるが、コンテナ間通信に対する最低限の強化として推奨
- 自己署名 SSL 証明書を本番証明書に置き換えたか、または自己署名のリスクを受容したか(SSL 証明書の管理 を参照)
- 外部接続を行う場合は、rabbitmq の外部接続用ユーザを追加し、強いパスワードを設定したか
-
(cluster/swarm のみ)Pgpool 系ユーザ(
kompira/pgpool/postgres/repl)に強いパスワードを設定したか(デフォルトの弱いパスワードのままにしていないか。初期構築時のPG_*_PASS指定、または §4.3 の変更手順で対応) -
.secret_keyをバックアップしたか(暗号化秘密鍵の管理 を参照)
8. 関連項目
- 暗号化秘密鍵の管理 —
.secret_keyファイルの管理とローテーション - SSL 証明書の管理 — HTTPS / AMQPS 用の SSL 証明書管理
- 構築ガイド > 外部連携構成 — 外部 jobmngrd / kompira_sendevt の rabbitmq ユーザ追加手順
- 環境変数 — ke2-docker の環境変数リファレンス
システムパッケージ管理
Kompira 環境にインストールされている Python や Web 用のパッケージの情報が以下で閲覧できます。 各パッケージ種別ごとにインストールされているパッケージのバージョンやライセンスに関する情報を確認することができます。
| パス | 説明 |
|---|---|
/system/packages/PIP | Kompira 環境で PIP で管理されている Python パッケージ情報 |
/system/packages/Web | Kompira 環境で static コンテンツとして管理されている Web 用パッケージ情報 |
注釈: システムパッケージ情報は Kompira をインストールまたはアップデートした後に kompirad が起動したタイミングで自動的に収集および更新されます。
パッケージ情報の管理
Kompira サーバ上で以下のコマンドを利用することでパッケージ情報を管理することができます。
$ docker exec $(docker ps -q -f name=kompira) manage.py packages_info [options...]
パッケージ情報の表示
オプションを省略または --show オプションを指定した場合、すでに収集されているパッケージ情報をコンソールに一覧表示します。
$ docker exec $(docker ps -q -f name=kompira) manage.py packages_info --show
パッケージ情報の一覧表示の例を以下に示します。
+------+----------------------+-----------+----------+-----------------+
| Type | Name | Installed | Latest | License |
+------+----------------------+-----------+----------+-----------------+
| pip | AMQPStorm | 2.10.8 | None | MIT License |
| pip | APScheduler | 3.10.4 | None | MIT License |
| pip | Creoleparser | 0.7.5 | None | MIT License |
| pip | Django | 4.2.14 | 5.0.7 | BSD License |
| pip | Genshi | 0.7.9 | None | BSD License |
| pip | GitPython | 3.1.43 | None | BSD License |
| pip | Jinja2 | 3.1.4 | None | BSD License |
: : : : :
パッケージ情報の収集
--collect オプションを指定した場合、インストールされているパッケージ情報を収集します。
$ docker exec $(docker ps -q -f name=kompira) manage.py packages_info --collect
このとき、各パッケージの最新バージョン情報を収集するためにインターネット接続が必要になります。
プロキシ接続が必要な場合は --proxy オプション(または https_proxy 環境変数)で指定してください。
インターネットに接続できないなど、最新バージョン情報の収集を行わない場合は --no-collect-latest オプションを追加で指定してください。
あるいは、明示的に最新バージョン情報の収集を行なうことを指定したい場合は --collect-latest オプションを追加で指定してください。
注釈: なお、収集されたパッケージ情報はコンテナ上の /var/opt/kompira/packages/ 配下に保存されます。
パッケージ情報の更新
--update オプションを指定した場合、収集済みパッケージ情報をもとに Kompira 上のシステムパッケージ情報オブジェクト(Wiki 型)を更新します。
$ docker exec $(docker ps -q -f name=kompira) manage.py packages_info --update
--update オプションと --collect オプションを併用した場合は、パッケージ情報の収集に続けてシステムパッケージ情報オブジェクトの更新を行ないます。
Python パッケージ管理
Python パッケージ (pip)のインストール先
KE2.0 では Python パッケージの参照先が、各コンテナで個別な場所と kompira および kengine コンテナ間で共有する場所があります。
- コンテナ個別:
/usr/local/lib/python3.11/site-packages/ - コンテナ共有:
/var/opt/kompira/lib/python3.11/site-packages/
ユーザーが作成するライブラリオブジェクトから参照する Python パッケージを追加する場合は、コンテナ共有な場所に配置する必要があります。 kompira コンテナの pip コマンドでインストールすると、デフォルトでコンテナ共有な場所にインストールするように構成しています。
docker exec $(docker ps -q -f name=kompira) pip install some-package
コンテナ共有ディレクトリは、kompira と kengine コンテナの両方から共有されているボリューム上にあるため、同じパッケージを両コンテナにインストールする必要はありません。
KE2.0 コンテナイメージでは、あらかじめ /usr/local/lib/python3.11/site-packages/.pth ファイルを作成してあり、そのファイルで上記パスを参照するように指定しています。
保守ガイド
ここに保守ガイドを書きます。
シングル構成の保守
以後の節では、シングル構成を保守する手順などについて示します。
各手順では共通的な準備やオプションの指定方法がありますので、以下を参考にしてください。
docker compose ファイルの指定
以後の説明ではシステム構築に用いた docker-compose.yml ファイルがあるディレクトリで docker compose コマンドを実行する前提になっています。
別のディレクトリで docker compose コマンドを実行する場合、または docker-compose.yml 以外の docker compose ファイルでシステムを構築している場合は、各 docker compose コマンドに -f <COMPOSE_FILE> オプションを付けて実行するようにしてください。
例:
$ docker compose -f /foo/bar/docker-compose-custom.yml start
システムの起動
シングル構成の起動および停止の手順について示します。
システムの起動手順
システム構築に用いた docker-compose.yml ファイルがあるディレクトリで、以下のコマンドを実行します。
$ docker compose start
なお、初回起動時には docker compose start ではなく docker compose up -d コマンドを実行しますが、これは各構成の構築手順で実施済みである前提です。
また、docker-compose.yml に restart: always という設定がある場合は、サーバ起動時に自動起動するようになっています。
全体のステータスを確認
VM 上の Docker で各コンテナが正常に動作しているか確認してください。
- ブラウザで /.status 画面を開いて全てのコンテナが正常を示している(赤い表示になっていない)ことを確認してください。
- ブラウザで Kompira にログインできることを確認してください。
- 自動起動または自動再起動するジョブフローが存在する場合は、期待通りにプロセスが開始しているかを確認してください。
システムの停止
シングル構成の停止の手順について示します。
システムの停止手順
システム構築に用いた docker-compose.yml ファイルがあるディレクトリで、以下のコマンドを実行します。
$ docker compose stop
システムの削除
シングル構成のシステムを削除する手順について示します。
コンテナの削除
以下のコマンドを実行すると、システムが停止するとともにすべてのコンテナが削除されます。
$ docker compose down
この状態ではデータ領域となるボリュームは残っていますので、再び docker compose up -d コマンドでシステムを開始すると、以前のデータにアクセスすることができます。
コンテナとボリュームの削除
以下のように -v オプションを指定して down した場合は、コンテナだけでなくボリュームも削除されます。
$ docker compose down -v
この場合は、以前のデータにアクセスすることは出来なくなりますので注意してください。
外部DBシングル構成の保守
以後の節では、シングル構成を保守する手順などについて示します。
各手順では共通的な準備やオプションの指定方法がありますので、以下を参考にしてください。
docker compose ファイルの指定
以後の説明ではシステム構築に用いた docker-compose.yml ファイルがあるディレクトリで docker compose コマンドを実行する前提になっています。
別のディレクトリで docker compose コマンドを実行する場合、または docker-compose.yml 以外の docker compose ファイルでシステムを構築している場合は、各 docker compose コマンドに -f <COMPOSE_FILE> オプションを付けて実行するようにしてください。
例:
$ docker compose -f /foo/bar/docker-compose-custom.yml start
システムの起動
外部DBシングル構成の起動および停止の手順について示します。
システムの起動手順
システム構築に用いた docker-compose.yml ファイルがあるディレクトリで、以下のコマンドを実行します。
$ docker compose start
なお、初回起動時には docker compose start ではなく docker compose up -d コマンドを実行しますが、これは各構成の構築手順で実施済みである前提です。
また、docker-compose.yml に restart: always という設定がある場合は、サーバ起動時に自動起動するようになっています。
全体のステータスを確認
VM 上の Docker で各コンテナが正常に動作しているか確認してください。
- ブラウザで /.status 画面を開いて全てのコンテナが正常を示している(赤い表示になっていない)ことを確認してください。
- ブラウザで Kompira にログインできることを確認してください。
- 自動起動または自動再起動するジョブフローが存在する場合は、期待通りにプロセスが開始しているかを確認してください。
システムの停止
シングル構成の停止の手順について示します。
システムの停止手順
システム構築に用いた docker-compose.yml ファイルがあるディレクトリで、以下のコマンドを実行します。
$ docker compose stop
システムの削除
シングル構成のシステムを削除する手順について示します。
コンテナの削除
以下のコマンドを実行すると、システムが停止するとともにすべてのコンテナが削除されます。
$ docker compose down
この状態ではデータ領域となるボリュームは残っていますので、再び docker compose up -d コマンドでシステムを開始すると、以前のデータにアクセスすることができます。
コンテナとボリュームの削除
以下のように -v オプションを指定して down した場合は、コンテナだけでなくボリュームも削除されます。
$ docker compose down -v
この場合は、以前のデータにアクセスすることは出来なくなりますので注意してください。
クラスタ構成の保守
以後の節では、クラスタ構成を保守する手順などについて示します。
クラスタの停止
クラスタ構成のシステム全体を停止させる場合の手順を示します。
注意事項
システム全体を停止する手順を実行すると以下のような影響があります。
- 実行中のジョブフローはすべて異常終了になります。自動再起動が有効なプロセスについては、システム全体を再開させた時に自動的に再起動します。
補足: 実行中のジョブフロープロセスに自動再起動が有効と設定されている場合、そのプロセスを実行中の kengine が動作しているノードを停止すると、別の動作中のノードで同じジョブフローを自動的に再起動するという動きをとります。そのため、システム全体を停止する手順としてノードを順番に停止させていく過程で、1台の停止ごとに時間があくと、ジョブフロープロセスの強制終了と自動再起動が短時間に繰り返される場合があることに注意してください。そうした振る舞いが好ましくない場合は、クラスタを停止させる前に、当該ジョブフロープロセスを手動で中止しておいてください。手動で中止したプロセスは自動再起動の対象外となります。ただし、システム全体を再開させた場合の自動的な再起動も行われませんので、必要に応じて手動で起動するようにしてください。
- 停止期間中に実行予定となっていたスケジュールは(再起動後も)実行されません。
3台構成のクラスタでは2台目のノードを停止した時点で、クラスタ構成メンバーが過半数を割るため、システムとしては正常に動作しなくなりはじめます(なお、過半数ノード停止状態でのシステム正常動作はサポート範囲外です)。ブラウザでアクセスしても「502 Bad Gateway」などのエラーになったり、docker コマンドでノード一覧を確認しようとしても以下のようにエラーになります。
$ docker node ls
Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader.
It's possible that too few managers are online. Make sure more than half of the managers are online.
こうしたエラーは想定通りとなりますので、残ったノードについても続けて停止してください。
クラスタ停止手順
クラスタを構成するノードを順番に停止させてください。
基本的に停止させるノードの順番は問いませんが、クラスタを再開するときは「ノードを停止させた逆順に開始する」ことが望ましいため、停止させたノードの順番は記録しておいてください。
各ノードを、例えば ke2-server3, ke2-server2, ke2-server1 の順で停止させた場合、クラスタを再開するときは ke2-server1, ke2-server2, ke2-server3 の順で起動することを推奨します。
各ノードの停止
クラスタを構成するホストサーバを順番にシャットダウンしてください。
$ sudo poweroff
※ poweroff コマンドが存在しないホストサーバの場合、shutdown -h now など代替のコマンドを利用してください。
または、対象ホストサーバ上で docker.socket を停止させることで、ホストサーバを停止させずにノード停止と同様の状態にすることができます。 (docker.service を停止させても、docker.socket を停止させていないと自動的に再起動することに注意してください)
$ sudo systemctl stop docker.socket
注意事項に記載のとおり、あるノードを停止したあとに過半数のノードが残っていない場合、例えば3台構成で1台になった時点で、docker node コマンドによる構成ノードの確認や、docker service ps コマンドによるコンテナの状態確認などは行えなくなりますので、ご注意ください。
必須ではありませんが、あるノードを停止したあとに、2台以上のノードが残っている段階では、停止したノードが docker node ls コマンドで STATUS が "Down" になったのを確認してから、次のノードの停止手順に進むことを推奨します。通常であればサーバをシャットダウンして数十秒程度以内に Down 状態になります。
以下の例ではノード ke2-server3 が Down 状態になっていることが分かります。
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
l96i39jjjq8ntkzu2p2vvejvf ke2-server1 Ready Active Reachable 26.1.4
sw6kopnwous6gfz0zg1qcp1ho * ke2-server2 Ready Active Leader 26.1.4
0i62egrvpwj0lpittkx9dw9na ke2-server3 Down Active Unreachable 26.1.4
クラスタの開始
全体を停止させていたクラスタ構成のシステムを開始する手順を示します。
なお、ここではノードやコンテナの構成および設定などについて、停止前から変更を加えていないことを前提としています。
注意事項
3台構成の swarm クラスタでは2台以上のノードで docker が開始しないと、クラスタノードの構成と各コンテナの起動は始まりません。 以下に説明する手順においても、途中までは各コンテナの動作は始まりませんので注意してください。
また、いくつかのコンテナには以下のような依存関係があり、依存するコンテナが正常に動作していないと起動しないようになっています。
| コンテナ | 依存するコンテナ |
|---|---|
| kompira | redis, postgres, rabbitmq |
| kengine | redis, postgres, rabbitmq |
| jobmngrd | rabbitmq |
たとえば、kompira や kengine コンテナは redis, postgres, rabbitmq コンテナに依存していますので、それらが正常に動作するまで起動に時間がかかったり、状況によってはコンテナの再起動を自動的に何度か繰り返す場合があります。通常であれば数分程度で安定しますので、一時的なコンテナの再起動などがあっても静観するようにしてください。
開始失敗時の対策
全てのノードを起動してから、5分以上経過してもいずれかのコンテナが正常に起動していない(コンテナの起動に失敗する、コンテナが再起動を繰り返す)ような場合は、システムに何らかの異常をきたしている可能性があります。そのような場合、以下を参考に対策してみてください。
- 一度クラスタ全体を停止させてから、クラスタ全体の開始を再度試してみてください。
- それでも状況が改善しない場合は、トラブルシュートを参考にして、システムの診断を行なって回復手順を試してみてください。
- それでも状況が改善しない場合は、サポート窓口またはコミュニティサイトにお問い合わせください。
クラスタ開始手順
クラスタを構成するノードを順番に起動させてください。
【要確認】このとき、可能であれば最後に停止させたノードから起動させてください。
【要確認】なお、各ミドルウェア (glusterfs, docker など) がすべて自動起動するように構成されている場合は、クラスタを構成する全てのノードを一度に起動させても問題ありませんが、各ノード起動による状態の変遷を確認しながらクラスタを開始することを推奨します。
各ノードを、ここでは ke2-server1, ke2-server2, ke2-server3 の順で起動するとした場合、以下のような流れになります。
- ke2-server1 起動:
- ノードの正常起動を確認
- ※ Pgpool-II/PostgreSQL の起動とオンラインリカバリ (primary ノードの起動)
- ke2-server2 起動:
- ノードの正常起動を確認
- 共有ファイルシステムのマウント
- ※ Pgpool-II/PostgreSQL の起動とオンラインリカバリ (standby ノードの起動)
- docker の起動 (共有ファイルシステムとデータベースを確認してから、ke2-server1 もここで起動します)
- クラスタノードのステータスを確認 (2台が Ready になっている)
- コンテナの開始を確認 (2台のノードでコンテナが開始している)
- ke2-server3 起動:
- ノードの正常起動を確認
- 共有ファイルシステムのマウント
- ※ Pgpool-II/PostgreSQL の起動とオンラインリカバリ (standby ノードの起動)
- docker の起動
- クラスタノードのステータスを確認 (3台が Ready になっている)
- コンテナの開始を確認 (全てのノードでコンテナが開始している)
- 全体のステータスを確認
※ 手順「pgpool-II/PostgreSQL の起動とオンラインリカバリ」は、外部データベースを利用した構成では不要です。
ノードの正常起動を確認
クラスタを構成するノードが正常に起動していることを、必要に応じて確認してください。
- SSH またはコンソールで対象ノードにログインできる。
- ホスト名およびネットワークアドレスが正しく構成されている。
- 所属ネットワークへの導通(例えばデフォルトゲートウェイへの ping)が確認できる。
- 2台目以降のノードを起動した場合は、クラスタを構成するノード間の導通についても確認する。
共有ファイルシステムのマウント
Kompira クラスタが利用している共有ファイルシステムをマウントしてください。ここでは glusterfs を利用して構成している場合の例を示します。
ただし、起動ノードが 1 台の段階ではマウント処理はできません。2台のノード起動後にマウントするようにしてください。
-
glusterd サービスを起動してください。
-
glusterd サービスの起動自体はノードが 1 台の段階でも実施することができます。
$ sudo systemctl start glusterd -
なお GlusterFS の準備 を参考に glusterfs を構築している場合は自動起動しているはずです。
-
-
glusterfs ボリュームをマウントしてください。
-
自動マウントする設定をしている場合でも、マウントされていることを必ず確認してください。
-
マウントされていない場合は、例えば mount コマンドを用いて手動でマウントしてください(マウントポイントは構成に合わせてください)。
$ sudo mount /mnt/gluster
-
少なくとも 2台の glusterfs ノードが起動していない段階では、マウントに失敗することに注意してください。
$ sudo mount /mnt/gluster
Mount failed. Check the log file for more details.
Pgpool-II/PostgreSQL の起動とオンラインリカバリ
注意: 外部データベースを利用してシステムを構成している場合は、この手順はスキップしてください。ただし、クラスタを開始するときは、事前に外部データベースが正常に動作していて接続可能な状態であることを確認するようにしてください。
Kompira クラスタを構成しているノード上で(docker コンテナ外部で) Pgpool-II/PostgreSQL クラスタも構成している場合は、docker を起動する前に Pgpool-II/PostgreSQL の起動とオンラインリカバリを実施してください。
- 1台目のノードを起動した段階:
-
PostgreSQL を起動してください。
- 【重要】postgresql が primary となるノード(例えば最後に停止したノード)を、1台目のノードとして起動してください。
- または、このノードの postgresql が primary になるように起動してください。
- 例えば、pgsql12 以降では $PGDATA/standby.signal を削除してから起動してください。
-
Pgpool-II を起動してください。
$ sudo systemctl start pgpool -
詳細については Pgpool-II の準備 の「Pgpool-II の起動」を参考にしてください。
-
- 2台目以降のノードを起動した段階:
-
Pgpool-II を起動してください。
$ sudo systemctl start pgpool -
Pgpool-II で当該ノードの postgresql に対するオンラインリカバリを実施してください。ここで、$CLUSTER_VIP は Pgpool-II で使用する仮想IPアドレスを、
<NODE_ID>はオンラインリカバリする対象のノードIDを指定してください。$ pcp_recovery_node -h $CLUSTER_VIP -p 9898 -U pgpool -n <NODE_ID> -W -
詳細については Pgpool-II の準備 の「スタンバイサーバのオンラインリカバリ」を参考にしてください。
-
docker の起動
起動したノードで docker が起動していない場合(または自動起動しないように設定している)は、以下のように開始してください。 なお、Swarm クラスタの準備 を参考にクラスタを構築している場合は、docker は自動起動するようになっています。
$ sudo systemctl start docker
共有ファイルシステムやデータベースが外部構成でも自動起動する設定にもなっていない(自動起動しないようにしている)場合は、docker についても自動起動しないように構成することも検討してみてください。docker を含めて2台以上のノードが起動してから正常なクラスタ動作を開始できるサービスが多いので、2台のノードを起動してから各サービスを手動で開始する手順をとることで、各手順ごとに状態を確認しながら作業することが出来るようになります。
クラスタノードのステータスを確認
2台以上のノードを起動して docker を開始したら、docker node ls コマンドを用いてクラスタノードの状態を確認してください。 ただし、ステータスが取得できるようになるのに、ノード起動後少し時間がかかる場合があるので注意してください。
例えば、2台目のノードを起動したあと以下のように 2 台の STATUS が "Ready" になり、そのうち一台の MANAGER STATUS が "Leader" になるはずです。また、まだ起動していない3台目のノードについては、STATUS が "Down" となり MANAGER STATUS が "Unreachable" となっていることが分かります。
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
l96i39jjjq8ntkzu2p2vvejvf * ke2-server1 Ready Active Reachable 26.1.4
sw6kopnwous6gfz0zg1qcp1ho ke2-server2 Ready Active Leader 26.1.4
0i62egrvpwj0lpittkx9dw9na ke2-server3 Down Active Unreachable 26.1.4
3台目のノードを起動したあとであれば、以下のようにすべてのノードの STATUS が "Ready" になるはずです。
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
l96i39jjjq8ntkzu2p2vvejvf * ke2-server1 Ready Active Reachable 26.1.4
sw6kopnwous6gfz0zg1qcp1ho ke2-server2 Ready Active Leader 26.1.4
0i62egrvpwj0lpittkx9dw9na ke2-server3 Ready Active Reachable 26.1.4
なお、1台目のノードを起動しただけの時点では、マネージャノード数が足りずに以下のようにエラーになります。
$ docker node ls
Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader.
It's possible that too few managers are online. Make sure more than half of the managers are online.
コンテナの開始を確認
各ノードでクラスタノードの状態を確認できたら、docker service ps コマンドを用いてコンテナの開始状況を確認してください。このコマンドは終了しているコンテナの情報も表示するため、ここでは以下のように実行中となるはずのコンテナだけを表示して確認しています。
$ docker service ps -f desired-state=running $(docker service ls -q)
なお、このコマンドは docker が正常に開始している任意のノードで実行できます。
例えば、2台目のノードを起動したあとにコンテナが正常に起動を開始している状況の例を以下に示します。3台目のノードが起動していないために、NODE は空欄になっており(当該コンテナがどこでも起動していない)、ERROR には "no suitable node" などのエラーが表示されていることがわかります。
$ docker service ps -f desired-state=running $(docker service ls -q)
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
i85kdpqhato3 ke2_jobmngrd.1 kompira.azurecr.io/kompira-enterprise:latest Running Pending 3 minutes ago "no suitable node (max replica…"
24z2rcnhc4ll ke2_jobmngrd.2 kompira.azurecr.io/kompira-enterprise:latest ke2-server2 Running Running 3 minutes ago
2xo9xug784u3 ke2_jobmngrd.3 kompira.azurecr.io/kompira-enterprise:latest ke2-server1 Running Running 3 minutes ago
vg0zk3qsc446 ke2_kengine.1 kompira.azurecr.io/kompira-enterprise:latest Running Pending 3 minutes ago "no suitable node (max replica…"
gdvrufzwbov5 ke2_kengine.2 kompira.azurecr.io/kompira-enterprise:latest ke2-server1 Running Running 3 minutes ago
v5cewfo0ewme ke2_kengine.3 kompira.azurecr.io/kompira-enterprise:latest ke2-server2 Running Running 3 minutes ago
bs2c7tfddwy7 ke2_kompira.1 kompira.azurecr.io/kompira-enterprise:latest ke2-server2 Running Running 3 minutes ago
g2cp91cwhxd3 ke2_kompira.2 kompira.azurecr.io/kompira-enterprise:latest ke2-server1 Running Running 3 minutes ago
mc45a9ilfmg6 ke2_kompira.3 kompira.azurecr.io/kompira-enterprise:latest Running Pending 3 minutes ago "no suitable node (max replica…"
j47uexpxtz8k ke2_nginx.1 registry.hub.docker.com/library/nginx:1.27-alpine Running Pending 3 minutes ago "no suitable node (host-mode p…"
szgmu5n2f3t7 ke2_nginx.2 registry.hub.docker.com/library/nginx:1.27-alpine ke2-server2 Running Running 2 minutes ago *:443->443/tcp,*:443->443/tcp,*:80->80/tcp,*:80->80/tcp
k32ba9qgcuyj ke2_nginx.3 registry.hub.docker.com/library/nginx:1.27-alpine ke2-server1 Running Running 3 minutes ago *:80->80/tcp,*:80->80/tcp,*:443->443/tcp,*:443->443/tcp
zeazgzl9ch9w ke2_rabbitmq.1 registry.hub.docker.com/library/rabbitmq:3.13-alpine Running Pending 3 minutes ago "no suitable node (max replica…"
yfvlqgh9urr2 ke2_rabbitmq.2 registry.hub.docker.com/library/rabbitmq:3.13-alpine ke2-server2 Running Running 3 minutes ago
khp2uezdem9z ke2_rabbitmq.3 registry.hub.docker.com/library/rabbitmq:3.13-alpine ke2-server1 Running Running 3 minutes ago
s7c9pqm0gf7g ke2_redis.1 registry.hub.docker.com/library/redis:7.2-alpine ke2-server1 Running Running 3 minutes ago
2台目のクラスタが正常に起動したとしても各コンテナは順次起動していきます。 そのため早すぎる段階でコマンドを実行しても、すべてのコンテナが開始していない場合があります(コマンド実行結果の一覧に表示されない)ので注意してください。
$ docker service ps -f desired-state=running $(docker service ls -q)
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
i85kdpqhato3 ke2_jobmngrd.1 kompira.azurecr.io/kompira-enterprise:latest Running Pending 2 seconds ago "no suitable node (max replica…"
v5cewfo0ewme ke2_kengine.3 kompira.azurecr.io/kompira-enterprise:latest ke2-server2 Running Running less than a second ago
mc45a9ilfmg6 ke2_kompira.3 kompira.azurecr.io/kompira-enterprise:latest Running Pending 2 seconds ago "no suitable node (max replica…"
yfvlqgh9urr2 ke2_rabbitmq.2 registry.hub.docker.com/library/rabbitmq:3.13-alpine ke2-server2 Running Running less than a second ago
3台目のノードを起動したあとに全てのコンテナが起動を開始している状況の例を以下に示します。全てのコンテナの行で NODE がいずれかのノードのホスト名を示していて、ERROR 列はすべて空欄になっていることが分かります。
$ docker service ps -f desired-state=running $(docker service ls -q)
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
3ruhydde239r ke2_jobmngrd.1 kompira.azurecr.io/kompira-enterprise:latest ke2-server3 Running Running 31 seconds ago
24z2rcnhc4ll ke2_jobmngrd.2 kompira.azurecr.io/kompira-enterprise:latest ke2-server2 Running Running 4 minutes ago
2xo9xug784u3 ke2_jobmngrd.3 kompira.azurecr.io/kompira-enterprise:latest ke2-server1 Running Running 4 minutes ago
zl3f74s8xtfh ke2_kengine.1 kompira.azurecr.io/kompira-enterprise:latest ke2-server3 Running Running 31 seconds ago
gdvrufzwbov5 ke2_kengine.2 kompira.azurecr.io/kompira-enterprise:latest ke2-server1 Running Running 4 minutes ago
v5cewfo0ewme ke2_kengine.3 kompira.azurecr.io/kompira-enterprise:latest ke2-server2 Running Running 4 minutes ago
bs2c7tfddwy7 ke2_kompira.1 kompira.azurecr.io/kompira-enterprise:latest ke2-server2 Running Running 4 minutes ago
g2cp91cwhxd3 ke2_kompira.2 kompira.azurecr.io/kompira-enterprise:latest ke2-server1 Running Running 4 minutes ago
2kiwn6dvorv5 ke2_kompira.3 kompira.azurecr.io/kompira-enterprise:latest ke2-server3 Running Running 31 seconds ago
mqod5o21dvrp ke2_nginx.1 registry.hub.docker.com/library/nginx:1.27-alpine ke2-server3 Running Running 28 seconds ago *:443->443/tcp,*:443->443/tcp,*:80->80/tcp,*:80->80/tcp
szgmu5n2f3t7 ke2_nginx.2 registry.hub.docker.com/library/nginx:1.27-alpine ke2-server2 Running Running 4 minutes ago *:443->443/tcp,*:443->443/tcp,*:80->80/tcp,*:80->80/tcp
k32ba9qgcuyj ke2_nginx.3 registry.hub.docker.com/library/nginx:1.27-alpine ke2-server1 Running Running 4 minutes ago *:80->80/tcp,*:80->80/tcp,*:443->443/tcp,*:443->443/tcp
q007y2p80gs8 ke2_rabbitmq.1 registry.hub.docker.com/library/rabbitmq:3.13-alpine ke2-server3 Running Running 31 seconds ago
yfvlqgh9urr2 ke2_rabbitmq.2 registry.hub.docker.com/library/rabbitmq:3.13-alpine ke2-server2 Running Running 4 minutes ago
khp2uezdem9z ke2_rabbitmq.3 registry.hub.docker.com/library/rabbitmq:3.13-alpine ke2-server1 Running Running 4 minutes ago
s7c9pqm0gf7g ke2_redis.1 registry.hub.docker.com/library/redis:7.2-alpine ke2-server1 Running Running 4 minutes ago
なお、1台目のノードを起動しただけの時点では、マネージャノード数が足りずに以下のようにエラーになります。
$ docker service ps -f desired-state=running $(docker service ls -q)
Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.
"docker service ps" requires at least 1 argument.
See 'docker service ps --help'.
Usage: docker service ps [OPTIONS] SERVICE [SERVICE...]
List the tasks of one or more services
全体のステータスを確認
全てのノードが起動できたら、クラスタを構成する各コンテナが正常に動作しているか確認してください。
- ブラウザで /.status 画面を開いて全てのコンテナが正常を示している(赤い表示になっていない)ことを確認してください。
- ブラウザで Kompira にログインできることを確認してください。
- 自動起動または自動再起動するジョブフローが存在する場合は、期待通りにプロセスが開始しているかを確認してください。なお、システムが正常な場合、(3台構成の場合) 2台目のノードを起動した時点で、このプロセスの自動起動処理は開始しています。
全てのノードが正常起動して、全てのコンテナが正常に動作していれば、クラスタ開始の成功となります。
ノードの停止
クラスタ構成において運用状態のまま一部のノードを停止させる手順を示します。
なお、ここでは一部のノードを停止する前は、全てのノード・全てのコンテナが正常に動作していることを前提としています。
制限事項
クラスタ構成においてシステムの運用を継続しつつ一部のノードを停止させたい場合、「停止させるノードは1台まで」 にしてください。
※ 5台以上の多ノード構成の場合は2台まで停止できる可能性がありますが、現時点でサポート対象となるのは1台までの停止です。
注意事項
ノードを停止させると、実行中のジョブフローの動作などに影響を与える場合があります。 可能であればジョブフローが全て停止している状態で実施されることをお勧めします。
- 【重要】当該ノードで redis コンテナが動作していた場合、ノードを停止させると redis コンテナが別のノードに移動します。このとき一時的に
redis がダウン状態になるため、以下のような影響があります。システム影響が大きいため redis
コンテナが動作しているノードの停止は十分注意して実施してください。
- ブラウザアクセスや REST-API アクセスが一時的にエラーになる場合があります。
- 実行中のジョブフロープロセスが異常終了する場合があります。
- 当該ノードの kengine コンテナ上の Executor で実行中のジョブフローは強制終了されます。
- 当該のジョブフロープロセスに「自動再起動」フラグが設定されている場合は、別のノード上で同じジョブフローが同じパラメータで新たに再起動されます。
- 【要確認】当該ノードの kengine が leader として動作 (role="leader") していた場合、ノードを停止させると leader が別のノードに移動します。
ノードの停止手順
停止対象のホストサーバをシャットダウンしてください。
$ sudo poweroff
※ poweroff コマンドが存在しないホストサーバの場合、shutdown -h now など代替のコマンドを利用してください。
または、対象ホストサーバ上で docker.socket を停止させることで、ホストサーバを停止させずにノード停止と同様の状態にすることができます。 (docker.service を停止させても、docker.socket を停止させていないと自動的に再起動することに注意してください)
$ sudo systemctl stop docker.socket
確認手順
クラスタの過半数のノードが正常に動作している場合、システムとしては正常に動作します。 一部のノードを停止したあとに、残ったノードでシステムが正常に動作しているかを確認してください。
- ブラウザで /.status 画面を開いて全てのコンテナが正常を示している(赤い表示になっていない)ことを確認してください。
- ブラウザで Kompira にログインできることを確認してください。
- 自動再起動が有効に設定されたジョブフロープロセスが実行中であった場合、別のノードで同じジョブフローが新たに開始していることを確認してください。
注意事項にあるように redis コンテナが移動するケースなどで、一時的にエラーが発生することがありますが、通常であれば時間経過とともに安定します。
停止失敗時の対策
一部のノードを停止したあとにエラーが発生するようになり、5分以上経過してもシステムが正常な状況に回復しないような場合は、システムに何らかの異常をきたしている可能性があります。そのような場合、以下を参考に対策してみてください。
ノードの起動
クラスタ構成において運用状態のまま停止させていた一部ノードを起動する手順を示します。
なお、ここではクラスタを構成する過半数のノードが起動していて、全てのコンテナが正常に動作していることを前提としています。
起動手順
前提条件から、3台構成のクラスタで言えば2台のノードでシステムが正常動作中で、最後の3台目を起動するのと同じ状況ですので、クラスタの開始 の3台目のノードの開始と同様の手順になります。
- ke2-server3 起動:
- ノードの正常起動を確認
- 共有ファイルシステムのマウント
- ※ Pgpool-II/PostgreSQL の起動とオンラインリカバリ (standby ノードの起動)
- docker の起動
- クラスタノードのステータスを確認 (3台が Ready になっている)
- コンテナの開始を確認 (全てのノードでコンテナが開始している)
- 全体のステータスを確認
ここでは簡略化した説明に留めますので、詳しくは クラスタの開始 を参照してください。
ホストサーバの起動
停止させていたホストサーバを起動してください。
共有ファイルシステムのマウント
Kompira クラスタが利用している共有ファイルシステム (glusterfs など) をマウントしてください。 ここでは glusterfs を利用して構成している場合の例を示します。
glusterd サービスを起動して、glusterfs ボリュームをマウントしてください(マウントポイントは構成に合わせてください)。
$ sudo systemctl start glusterd
$ sudo mount /mnt/gluster
pgpool-II/PostgreSQL の起動とオンラインリカバリ
注意: 外部データベースを利用してシステムを構成している場合は、この手順はスキップしてください。
pgpool サービスを起動して、起動したノードの postgresql に対するオンラインリカバリを実施してください。ここで、$CLUSTER_VIP は Pgpool-II で使用する仮想IPアドレスを、<NODE_ID> はオンラインリカバリする対象のノードIDを指定してください。
$ sudo systemctl start pgpool
$ pcp_recovery_node -h $CLUSTER_VIP -p 9898 -U pgpool -n <NODE_ID> -W
docker の起動
docker サービスを起動してください。
$ sudo systemctl start docker
クラスタノードのステータスを確認 (3台が Ready になっている)
docker node ls コマンドを用いてクラスタノードの状態を確認してください。
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
l96i39jjjq8ntkzu2p2vvejvf * ke2-server1 Ready Active Reachable 26.1.4
sw6kopnwous6gfz0zg1qcp1ho ke2-server2 Ready Active Leader 26.1.4
0i62egrvpwj0lpittkx9dw9na ke2-server3 Ready Active Reachable 26.1.4
コンテナの開始を確認 (全てのノードでコンテナが開始している)
docker service ps コマンドを用いて全てのノードで全てのコンテナの開始していることを確認してください。
$ docker service ps -f desired-state=running $(docker service ls -q)
全体のステータスを確認
ノードが起動できたら、クラスタを構成する各コンテナが正常に動作しているか確認してください。
- ブラウザで /.status 画面を開いて全てのコンテナが正常を示している(赤い表示になっていない)ことを確認してください。
- ブラウザで Kompira にログインできることを確認してください。
コンテナの移動
ke2-docker を用いて構成した Docker swarm クラスタ構成では、明示的にコンテナを移動する操作を行なう必要はありません。 まず、ほとんどのコンテナは全てのノードでレプリカされて、全てがアクティブとして動作するため、コンテナを移動する意味はありません。
KE2.0 の時点では唯一、redis コンテナについては 単一のノードでのみ動作するように構成されています。そのため redis コンテナについてはどのノードで動作しているのか、動作するノードが移動するケースについて、また、強制的に動作ノードを移動させたい場合の手法について説明します。
redis コンテナを実行しているノードの確認
現在どのノードで redis コンテナが動作しているかについては、docker service ps コマンドを用いて確認することができます。
$ docker service ps ke2_redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
j002f9kno7ma ke2_redis.1 registry.hub.docker.com/library/redis:7.2-alpine ke2-server1 Running Running 25 hours ago
g7lg28hnfupv \_ ke2_redis.1 registry.hub.docker.com/library/redis:7.2-alpine ke2-server1 Shutdown Failed 25 hours ago "No such container: ke2_redis.…"
ngwsnwc20fqk \_ ke2_redis.1 registry.hub.docker.com/library/redis:7.2-alpine ke2-server1 Shutdown Failed 25 hours ago "No such container: ke2_redis.…"
コマンドを実行して表示される結果の DESIRED STATE が "Running" となっている行の NODE で、現在 redis コンテナを実行しているノードが確認できます。以下のようにいくつかオプションを付けて実行すると、当該するノードの情報だけ表示することができます。
$ docker service ps -f desired-state=running --format "{{.Node}}" ke2_redis
ke2-server1
redis コンテナが移動するタイミング
クラスタが開始したとき(2台目のノードが開始したとき)いずれかのノードで redis コンテナが起動します。基本的に redis コンテナはそのノードから移動せずに動作しつづけますが、以下のようなときには別のノードに移動して動作を再開する場合があります。
- redis コンテナがダウンしたとき(移動せず同じノードで再起動となる場合もあります)
- redis コンテナが動作しているノードがダウンしたとき
- 強制的に redis コンテナを移動させたとき
redis コンテナの移動方法【非推奨】
Docker swarm クラスタにおいて、あるコンテナを指定したノードに移動させる決まった手順はありません。以下のように docker service update コマンドを用いることで、redis コンテナの状態更新が行なわれて、その結果として別のノードに移動する場合があります(同じノードでの再起動となる場合もあります)。
$ docker service update --force ke2_redis
ただし、redis コンテナが移動(もしくは再起動)すると動作中のジョブフローが異常終了するなどの影響が起きる場合がありますので、特別な理由がない限り redis コンテナの移動は控えることを推奨します。
システムの削除
クラスタ構成のシステムを削除する手順について示します。
クラスタの削除手順
Swarm クラスタのいずれかのマネージャーノード上(以下の例では ke2-server1)で、docker stack rm ke2
コマンドを実行してください。
[ke2-server1]$ docker stack rm ke2
Removing service ke2_jobmngrd
Removing service ke2_kengine
Removing service ke2_kompira
Removing service ke2_nginx
Removing service ke2_rabbitmq
Removing service ke2_redis
Removing config swarm_rabbitmq-config-cluster
Removing config swarm_kompira-config
Removing config swarm_rabbitmq-config-auth
Removing config swarm_kompira-audit
Removing config swarm_rabbitmq-config-ssl
Removing config swarm_bootstrap-rabbitmq
Removing config swarm_nginx-config
Removing network swarm_default
このコマンドを実行すると、クラスタで動作している全てのコンテナが停止して、クラスタスタックと構成サービスの定義などが削除されます。停止したあとに
docker stack ls, docker service ls, docker config ls
コマンドを実行すると、いずれも空になっているはずです。
$ docker stack ls
NAME SERVICES
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
$ docker config ls
ID NAME CREATED UPDATED
この状態になると、ノードを再起動したり docker サービスを再起動しても、Kompira サービスは起動しません。
なお、この時点では Swarm クラスタ構成自体は残っています。
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
l96i39jjjq8ntkzu2p2vvejvf * ke2-server1 Ready Active Reachable 26.1.4
sw6kopnwous6gfz0zg1qcp1ho ke2-server2 Ready Active Leader 26.1.4
0i62egrvpwj0lpittkx9dw9na ke2-server3 Ready Active Reachable 26.1.4
そのため、Swarm クラスタ構成の セットアップ手順 からデプロイしなおすことが出来ます。
コンテナの削除手順
クラスタが停止してもコンテナが残っている場合があります。docker container ls -a
コマンドで停止したものも含めてコンテナの一覧を確認できます。
$ docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
059775d2d864 kompira.azurecr.io/kompira-enterprise:latest "docker-entrypoint.s…" 5 days ago Dead ke2_kompira.3.chic2oqd0l46t6c6i3q1yd5rk
残っているコンテナを削除したい場合は、docker container prune コマンドで一括削除できます。
本当に削除するか確認されるので、実行する場合は y を入力してください。
$ docker container prune
WARNING! This will remove all stopped containers.
Are you sure you want to continue? [y/N] y
Deleted Containers:
059775d2d864483ba451d268b41e70c8761c9efaf559e7979e65253e91568926
Total reclaimed space: 803.1kB
この手順は、クラスタを構成する各ノードで実施してください。
イメージの削除手順
クラスタを停止してもコンテナイメージは残っています。docker image ls -a コマンドで全てのコンテナイメージの一覧を確認できます。
$ docker image ls -a
REPOSITORY TAG IMAGE ID CREATED SIZE
kompira.azurecr.io/kompira-enterprise <none> 95fb2b1e3ef0 7 days ago 503MB
kompira.azurecr.io/kompira-enterprise <none> 2fc0e8aea9b4 7 days ago 503MB
kompira-enterprise 2.0.1a1_62f84257 f60f16a921fb 7 days ago 503MB
kompira-enterprise 2.0.1a1_66ee42a9 c702af2baab6 7 days ago 503MB
kompira.azurecr.io/kompira-enterprise <none> 3efb4ead515c 8 days ago 503MB
kompira-enterprise 2.0.0_a4071bf5 eac7265ec11b 2 weeks ago 503MB
kompira-enterprise 2.0.0_8875d278 75f9622860d7 2 weeks ago 503MB
registry.hub.docker.com/library/rabbitmq <none> 0ca98669e517 2 weeks ago 141MB
kompira-enterprise 2.0.0_a3309cf7 0d540ff81113 3 weeks ago 503MB
registry.hub.docker.com/library/rabbitmq <none> 2262fa9f479a 4 weeks ago 141MB
registry.hub.docker.com/library/rabbitmq <none> 4083c19b838f 5 weeks ago 141MB
kompira-enterprise 2.0.0_56cb960d 868774a8f9bf 5 weeks ago 504MB
registry.hub.docker.com/library/nginx <none> c7b4f26a7d93 6 weeks ago 43.2MB
registry.hub.docker.com/library/nginx <none> 0f0eda053dc5 6 weeks ago 43.3MB
kompira.azurecr.io/kompira-enterprise <none> de61c5570c0d 7 weeks ago 504MB
registry.hub.docker.com/library/rabbitmq <none> 5d6e30bc0bea 8 weeks ago 141MB
registry.hub.docker.com/library/nginx <none> 1ae23480369f 3 months ago 43.2MB
registry.hub.docker.com/library/redis <none> ab3bbb60f1b6 4 months ago 40.7MB
registry.hub.docker.com/library/redis <none> 97ed3031282d 4 months ago 40.7MB
残っているコンテナイメージを削除したい場合は、docker image prune -a コマンドで一括削除できます。
本当に削除するか確認されるので、実行する場合は y を入力してください。
$ docker image prune -a
WARNING! This will remove all images without at least one container associated to them.
Are you sure you want to continue? [y/N] y
Deleted Images:
untagged: registry.hub.docker.com/library/nginx@sha256:a5127daff3d6f4606be3100a252419bfa84fd6ee5cd74d0feaca1a5068f97dcf
deleted: sha256:c7b4f26a7d93f4f1f276c51adb03ef0df54a82de89f254a9aec5c18bf0e45ee9
deleted: sha256:df45629925efee5af98c24cd09fa6eb06f53bf8a31eb6255e25efd729c902e1e
deleted: sha256:e9d09343f346fd7a1ae6dde03c9d2a948dba60c99be0083f703c10acb691a29b
:
untagged: kompira.azurecr.io/kompira-enterprise@sha256:c40e73309d67cf98eedd111ef783e1350379c280440718b1ec57de8c4e8839a2
deleted: sha256:2fc0e8aea9b48d0f98b64480eb13792baa3da0cddb3716e676a04e0b5f274923
deleted: sha256:27161d5e2678b37f620e2273bdefd619791dc937b711a03c163f6e8fd4a37155
deleted: sha256:d940d53c7b474ee3fdbcc9f1830eb2bb0a2d69f3c35511e491b1228a47c4fe9e
:
Total reclaimed space: 5.414GB
この手順は、クラスタを構成する各ノードで実施してください。
ボリュームの削除手順
クラスタを停止しても名前付きボリュームは残っています。docker volume ls コマンドでボリュームの一覧を確認できます。
$ docker volume ls
DRIVER VOLUME NAME
local swarm_kompira_rmq
残っているボリュームを削除したい場合は、docker volume prune -a コマンドで一括削除できます。
本当に削除するか確認されるので、実行する場合は y を入力してください。
$ docker volume prune -a
WARNING! This will remove all local volumes not used by at least one container.
Are you sure you want to continue? [y/N] y
Deleted Volumes:
swarm_kompira_rmq
Total reclaimed space: 1.141MB
この手順は、クラスタを構成する各ノードで実施してください。
ネットワークの削除
クラスタを停止しても Docker のネットワーク定義は残っています。docker network ls コマンドでネットワークの一覧を確認できます。
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
d43ebc7d365d bridge bridge local
937af22066a7 docker_gwbridge bridge local
a2a80d3dca46 host host local
uswsxaj23dbt ingress overlay swarm
c0fa71959a20 none null local
docker network prune コマンドで、カスタム定義されたネットワークを削除することができます。ただし Kompira 2.0
ではカスタム定義しているネットワークはありませんので、通常は実際に削除されるネットワークはないはずです。
$ docker network prune
WARNING! This will remove all custom networks not used by at least one container.
Are you sure you want to continue? [y/N] y
トラブルシュートガイド
Kompira 2.0 システムが正常に動作していないと考えられるとき、正常な状態に回復させるには問題の原因を特定する必要があります。
その前提として、システムを構成する各コンテナがどのような役割を担い、他のコンテナとどう連携しているか、また障害時の影響範囲を理解しておくことが重要です。
対象とする構成と表記
本ガイドが対象とする構成は、標準構成一覧 に定義された次の構成です(構成の分類とその配下の個別構成)。
- オンプレシングル構成 — 1 台のホストで docker compose により動作させる構成。配下に 標準シングル構成(ローカル postgres)と 外部DBシングル構成(外部 postgres)があります。
- オンプレクラスタ構成 — 配下の Swarmクラスタ構成 は、3 台以上のノードで Docker Swarm により動作させ、外部 DB(Pgpool-II)と GlusterFS を用いる構成です。
クラウド構成は準備中のため、本ガイドの対象外です。
構成の表記について
本ガイドでは、内容に応じて構成の表記を使い分けます。
- 複数の個別構成で対処が共通する場合は、グループ名で示します(例: オンプレシングル構成 = 標準シングル構成 + 外部DBシングル構成)。
- 構成によって対処が異なる場合は、個別構成名(標準シングル構成 / 外部DBシングル構成 / Swarmクラスタ構成)で示します。
なお、対応構成の追加にトラブルシュート情報の整備が追いつかない場合など、構成によってカバーする範囲に差が生じることがあります。
調べ方(3 つの入口)
状況に応じて、以下のいずれかの入口から調査を始めてください。いずれも最終的には 原因と対処(コンポーネント別) にたどり着きます。
- 症状から探す — 「コンテナが停止している」「再起動を繰り返す」など、観測している症状から調べる → 症状から探す
- ログ・エラーから探す — 手元にエラーログやエラーメッセージがある場合は、原因と対処(コンポーネント別) のページ右上の検索でエラーメッセージを検索すると該当箇所に直接たどり着けます
- 構成から探す — 自分の構成で起こりうる障害・固有の注意点から調べる → 構成から探す
原因箇所の見当がついていない場合は、順を追って診断する初期診断手順から始めてください。
障害時の初期診断手順
ここでは障害時における基本的な初期診断の手順を示します。複雑な状況では原因特定が容易ではなく、ここに示した手順であらゆる状況に対応できるわけではないことに注意してください。
- ブラウザによる診断手順 — ユーザのブラウザ操作で実施できる診断(system-status 画面、基本操作、ジョブフロー動作確認)
- コマンドによる診断手順 — 管理者がホストサーバにログインして実施する診断
原因と対処
各コンポーネントのログに記録されるエラーから、原因と対処を調べます。
解決しない場合
本ガイドの診断・対処で解決しない場合は、サポートへ問い合わせる前に必要な情報を収集してください。
各コンテナの役割と障害時の影響範囲
Kompira 2.0 システムはいくつかのコンテナで構成されていて、それらが協調動作することでシステムとして正常に動作することができます。 コンテナはそれぞれ役割を持っており、コンテナに障害が起きたときはそれぞれ異なる影響を受けることになります。 また、いくつかのコンテナは他のコンテナに依存しているものもあり、そうしたコンテナでは依存先コンテナで障害があるとその影響を受ける場合もあります。
Kompira を構成する各コンテナについて、その依存するコンテナおよび障害時の主な影響について以下にまとめます。
| コンテナ | 依存するコンテナ | コンテナ障害時の主な影響 |
|---|---|---|
| redis | システム全体 | |
| postgres | システム全体 | |
| nginx | ブラウザアクセス、REST-APIアクセス | |
| rabbitmq | 各コンテナの連携動作、kompira_sendevt からのメッセージ受信 | |
| kompira | redis, postgres, rabbitmq | ブラウザアクセス、REST-APIアクセス、管理コマンドの実行 |
| kengine | redis, postgres, rabbitmq | ジョブフローの実行 |
| jobmngrd | rabbitmq | リモートジョブの実行 |
影響範囲となっている役割や機能に関して、正常に動作していないと考えられるような場合は、当該のコンテナに何らかの問題が生じているという推測はできます。 Kompira システムに問題があった場合にトラブルシュートを実施することに備えて、事前に各コンテナの役割や障害時の主な影響範囲について理解を深めておくことをお勧めします。
以下に各コンテナの役割と障害時の典型的な影響範囲について示しますが、実際にはある状況が複数の障害や影響を同時に引き起こすようなことも多いです。 トラブルシュートにあたってはこれらは基本的な情報としてとらえて、個別には複雑な状況が起きうることを想定しておいてください。
redis の役割と影響範囲
Kompira オブジェクトアクセスなど各種データ処理のキャッシュ機構を担うため、redis コンテナの正常性は非常に重要です。 redis がダウンしている、または、他コンテナからアクセスできない状態になると、システム全体に影響があります。
- ブラウザ操作時に応答が返らなくなる、または内部処理エラーになります。
- ジョブフローの動作が停止する、または内部処理エラーになります。
postgres の役割と影響範囲
全ての Kompira オブジェクトの保存先となるため、postgres コンテナの正常性は非常に重要です。 postgres がダウンしている、または、他コンテナからアクセスできない状態になると、redis 同様にシステム全体に影響があります。
nginx の役割と影響範囲
nginx コンテナは外部からの HTTP/HTTPS アクセスを受け付ける役割を担います。nginx の障害時には、以下のような影響があります。
- 外部から HTTP/HTTPS アクセスが出来なくなります。
- 外部からの HTTP/HTTPS アクセスは接続エラーや接続タイムアウトなどになります。
rabbitmq の役割と影響範囲
rabbitmq は各コンテナ間の連携動作をサポートするため、障害時の影響は以下のように多岐にわたります。
- kompira と kengine の連携が出来なくなります。
- ブラウザ操作からジョブフローの実行など、kengine に対する処理指示ができなくなります。
- Kompira オブジェクト更新時にそれに伴う kengine との連携処理ができなくなります。
- kengine と jobmngrd の連携ができなくなります。
- ジョブフローによるリモートジョブなどの実行ができなくなります。
- 外部に配置した kompira_jobmngrd とも連携できなくなります。
- kompira_sendevt からのメッセージを受信できなくなります。
kompira の役割と影響範囲
kompira コンテナは外部インターフェース経由のアプリケーション処理を担います。
- nginx が受け付けた HTTP/HTTPS リクエストに応じた、ブラウザ操作および REST-API アクセスが出来なくなります。
- 外部からの HTTP/HTTPS アクセスは 50x エラーやレスポンスタイムアウトになります。
- kompira コンテナ上での manage.py 管理コマンドの実行ができなくなります。
kengine の役割と影響範囲
kengine コンテナはジョブフローなどプロセスの動作を担います。kengine の障害時には以下のような影響があります。
- ジョブフローおよびスクリプトジョブの実行ができなくなります。
- kompira_sendevt からのメッセージを受信できなくなります。
ただしジョブフローの実行などは、実際には kengine 上で動作する Executor がその役割を担っています。 Executor はライセンスやシステム構成によって、一つの kengine 上で複数の Executor が動作する場合があります。これは、一部の Executor のみで障害が発生しているようなケースでは、一部のジョブフローは実行できているが、別の一部のジョブフローの実行が出来なくなる、といった状況を生み出す可能性もあることに注意してください。
また kengine には "leader" または "follower" という役割があり、システム全体で一つの kengine だけが leader となります。leader となる kengine が存在しないような状況では、さらに以下のような影響があります。
- 不要になったプロセス情報が回収されずに残り続けます。
- スケジュールやメールチャネルの再割り当てがなされずに、正常に機能しなくなります。
- ジョブマネージャ情報が更新されなくなります。
jobmngrd の役割と影響範囲
jobmngrd コンテナはリモートジョブの実行を担うため、障害時には以下のような影響があります。
- 実行ジョブを用いた ["command args..."] などのコマンド実行ができなくなります。
- スクリプトジョブの実行ができなくなります。
- その他のリモートジョブである、セッションジョブ、ファイル転送ジョブなども実行できなくなります。
クラスタ構成など jobmngrd が複数存在するような構成で一部の jobmngrd で障害が発生しているようなケースでは、一部のリモートジョブは実行できるが、別の一部のリモートジョブが実行できない、といった状況を生み出す可能性もあることに注意してください。
症状から探す
観測している症状から、考えられる原因と対処にたどり着くための入口です。
- コンテナが停止している — system-status 画面でコンテナが
NG(赤)になっている、
docker psでコンテナがExitedになっているなど - コンテナが異常・再起動を繰り返す — コンテナの
STATUSが頻繁に変わる、Restartingと表示される、ジョブフロー実行時にエラーになるなど - 応答が遅い・高負荷で不安定 — コンテナは正常だが、高負荷で画面・API が遅い/一部が失敗する
system-status 画面(
/.status)の表示から調べる場合は、システムステータスによる診断手順 を参照してください。NG 表示の組み合わせから原因候補を引く早見表があります。
手元にエラーログ・エラーメッセージがある場合は、原因と対処(コンポーネント別) のページ右上の検索でエラーメッセージを検索すると該当箇所に直接たどり着けます。
コンテナが停止している
コンテナが停止すると、停止したコンテナの役割に応じてシステムに影響が出ます(各コンテナの障害時の影響範囲)。
まず、どのコンテナが停止しているかを確認します。
# シングル構成
$ docker ps --all
# Swarmクラスタ構成
$ docker service ls
KE2 構成に関係するコンテナの STATUS が Exited(クラスタではサービスの REPLICAS
が不足)になっていれば、そのコンテナが停止しています。以下、コンテナ別に一次対処と詳細な原因調査へのリンクを示します。
一次対処で復旧しない、または再起動を繰り返す場合は コンテナが異常・再起動を繰り返す も参照してください。
redis が停止している
system-status 画面では redis が ERROR(503)となり、システム全体に影響します(ブラウザ操作の応答なし、ジョブフロー停止)。

一次対処
# オンプレシングル構成
$ docker ps -a -f name=redis
$ docker restart <REDIS_CONTAINER_ID> # STATUS が Up 以外のとき
# Swarmクラスタ構成(redis はいずれか 1 ノードで実行。docker service ps ke2_redis で詳細確認)
$ docker service ls
詳細な原因と対処: redis 名前解決エラー(Error -2 connecting to redis:6379)
postgres が停止している(標準シングル構成)
system-status 画面では postgres が ERROR(503)となり、システム全体に影響します(KE2 APP にログインできなくなります)。

一次対処
$ docker ps -a -f name=postgres
$ docker restart <POSTGRES_CONTAINER_ID> # STATUS が Up 以外のとき
詳細な原因と対処: ローカル DB 停止(nc: bad address 'postgres')
外部DBシングル構成・Swarmクラスタ構成では postgres は外部にあります。データベースの原因と対処 を参照してください。
rabbitmq が停止している
コンテナ間連携ができなくなり、ジョブフロー実行やリモートジョブが実行できなくなります。
一次対処
$ docker ps -a -f name=rabbitmq
$ docker restart <RABBITMQ_CONTAINER_ID> # STATUS が Up 以外のとき
詳細な原因と対処
- オンプレシングル構成: rabbitmq 名前解決エラー(nc: bad address 'rabbitmq')
- Swarmクラスタ構成: rabbitmq の原因と対処
kompira が停止している
特定のホストサーバで KE2 APP にアクセスすると「502 Bad Gateway」が表示されます。

一次対処
$ docker ps -a -f name=kompira
$ docker restart <KOMPIRA_CONTAINER_ID> # STATUS が Up 以外のとき
復旧しない場合は KE2 APP を再起動する を試してください。
nginx が停止している
特定のホストサーバで KE2 APP にアクセスすると「This site can't be reached」が表示されます。

一次対処
$ docker ps -a -f name=nginx
$ docker restart <NGINX_CONTAINER_ID> # STATUS が Up 以外のとき
復旧しない場合は KE2 APP を再起動する を試してください。
jobmngrd が停止している
リモートジョブ(実行ジョブ・スクリプトジョブ・セッションジョブ・ファイル転送ジョブ)が実行できなくなります。
一次対処
$ docker ps -a -f name=jobmngrd
$ docker restart <JOBMNGRD_CONTAINER_ID> # STATUS が Up 以外のとき
詳細な原因と対処: jobmngrd の原因と対処(AMQP connection timeout)
コンテナが異常・再起動を繰り返す
コンテナが起動しているものの、異常な状態や再起動を繰り返している場合があります。以下のコマンドを数回実行し、STATUS の Up
期間が一致せず頻繁に変わる場合(Restarting と表示される場合もある)は、そのコンテナが頻繁に再起動されています。
# シングル構成
$ docker ps
# Swarmクラスタ構成(CURRENT STATE が短期間で Shutdown/Failed を繰り返す)
$ docker service ps <SERVICE_NAME>
rabbitmq が再起動を繰り返す
ブラウザでアクセスすると、エンジンとジョブマネージャがともに停止しているエラーが表示される場合があります。

この場合、次のいずれかが考えられます。
- rabbitmq が正常に動作できていないため、kengine / jobmngrd がともに正常に起動できなくなっている
- rabbitmq は正常だが、kengine と jobmngrd にそれぞれ問題があって両方とも停止している
kengine や jobmngrd が依存している rabbitmq が正常に動作しているかを先に確認してください。
- Swarmクラスタ構成: rabbitmq の原因と対処(Mnesia 破損 / Partial partition / Waiting for Mnesia tables / erl_crash / pre_vote など)を参照してください。
- オンプレシングル構成: 現時点では個別の調査手順を提供していません。問い合わせ前に情報を収集のうえ、サポートへお問い合わせください。
rabbitmq が正常に動作しているようであれば、kengine / jobmngrd コンテナの異常を確認してください。
kengine が再起動を繰り返す
Swarmクラスタ構成
docker ps で kengine の STATUS が頻繁に変わります。/system/info を確認すると kengine のステータスが
unknown と表示され engine 毎に変わる一方、/.status では normal と表示されることがあります。

しかしジョブフローを実行するとエラーが発生します。

kengine ログには Message not delivered: NO_ROUTE (312) や
[AMQPConnector] AMQP connection error: connection closed が記録されることがあります。これは
RabbitMQ
クラスタの設定が変わってしまい、クラスタ全体が不安定になっている場合に発生します。rabbitmq の原因と対処
を参照してください。
オンプレシングル構成
現時点では個別の調査手順を提供していません。問い合わせ前に情報を収集のうえ、サポートへお問い合わせください。
redis / kompira / nginx / jobmngrd が再起動を繰り返す
- jobmngrd(オンプレシングル構成): jobmngrd の原因と対処 を参照してください。
- redis(Swarmクラスタ構成): redis はいずれか 1
ノードで実行されるサービスで、ノード障害時に別ノードへ切り替わります。
docker service ps ke2_redisでCURRENT STATEが短期間でShutdownを繰り返す場合は不安定です。redis 名前解決エラー の「Swarmクラスタ構成」の対処を参照してください。 - 上記以外(redis / kompira / nginx のシングル構成など)については、現時点では個別の調査手順を提供していません。問い合わせ前に情報を収集のうえ、サポートへお問い合わせください。
応答が遅い・高負荷で不安定
コンテナは動作しているのに、高負荷時に応答が遅い・一部の操作が失敗する場合の入口です。
まず、次を除外してください(これらが原因のことが多いため)。
- コンテナが停止している / コンテナが異常・再起動を繰り返す
- ホストサーバのリソース状況の確認(CPU・メモリ・ディスクの逼迫)
コンテナが正常でリソースにも余裕があるのに遅い・失敗する場合は、以下の観測から環境変数の調整を検討します。
| 観測できるシグナル | 調整の指針 |
|---|---|
画面・API が 500 エラー、ログに FATAL: sorry, too many clients already | データベース接続数の上限超過 |
高負荷で画面・API 全体が遅い/応答が返らない(.wait / .recv を HTTP 経由で多用) | Web ワーカ枯渇 |
| 特定の重い操作だけ約 300 秒で失敗する・504 になる | タイムアウト |
詳細と調整方法は 高負荷時のチューニング(環境変数) を参照してください。
構成から探す
ご利用の構成で起こりうる障害と、その構成に固有の注意点をまとめた入口です。自分の構成を選んでください。
- 標準シングル構成 — 1 台のホストで docker compose により全コンテナ(ローカル postgres を含む)を動作させる構成
- 外部DBシングル構成 — 1 台のホストで docker compose により動作させ、postgres は外部に配置する構成
- Swarmクラスタ構成 — 3 台以上のノードで Docker Swarm により動作させ、外部 DB(Pgpool-II)と GlusterFS を用いる構成
各ページは原因と対処(コンポーネント別)へのリンク集です。詳細な手順はリンク先を参照してください。
標準シングル構成で起こりうる障害
1 台のホストで docker compose により全コンテナを動作させる構成です。postgres
もローカルのコンテナ(ke2-postgres-1)として動作します(全 7 コンテナ: nginx / redis / kompira / kengine
/ postgres / rabbitmq / jobmngrd)。
起こりうる障害と対処
- redis が停止している → redis 名前解決エラー
- postgres が停止している → ローカル DB 停止(nc: bad address 'postgres')
- rabbitmq が停止している → rabbitmq 名前解決エラー
- rabbitmq のアラーム → ディスクリソース制限アラーム / メモリリソース制限アラーム
- kompira / nginx が停止している
- jobmngrd が停止している → jobmngrd の原因と対処
- docker デーモンが不安定
この構成に固有の注意点
- 単一ホストのため、ホストサーバのリソース不足(CPU/メモリ/ディスク)が全コンポーネントに影響します。ホストサーバのリソース状況の確認 を定期的に行ってください。
- postgres はローカルコンテナです。DB 障害時は外部 DB ではなくコンテナの状態を確認してください。
- 全体的に復旧しない場合は KE2 APP を再起動する。
外部DBシングル構成で起こりうる障害
1 台のホストで docker compose により動作させ、postgres は外部に配置する構成です(全 6 コンテナ: nginx / redis / kompira / kengine / rabbitmq / jobmngrd)。
起こりうる障害と対処
- redis が停止している → redis 名前解決エラー
- rabbitmq が停止している → rabbitmq 名前解決エラー
- rabbitmq のアラーム → ディスクリソース制限アラーム / メモリリソース制限アラーム
- 外部 DB へ到達不可 → Host is unreachable
- 外部 DB が停止 → Connection refused
- 読み取り専用トランザクション → cannot execute UPDATE in a read-only transaction
- pgpool 利用時のノード間不整合 → unable to read message kind
- jobmngrd が停止している → jobmngrd の原因と対処
- docker デーモンが不安定
この構成に固有の注意点
- postgres は外部にあります。DB 障害時は、KE2 APP ホストサーバと外部 DB 間のネットワーク導通と外部 DB へのアクセスを確認してください。
- 全体的に復旧しない場合は KE2 APP を再起動する。
Swarmクラスタ構成で起こりうる障害
3 台以上のノードで Docker Swarm により動作させ、外部 DB(Pgpool-II)と GlusterFS を用いる構成です。各ノードで nginx / kompira / kengine / rabbitmq / jobmngrd が動作し、いずれか 1 ノードで redis が動作します。
起こりうる障害と対処
- redis のフェイルオーバー/不安定 → redis 名前解決エラー(Swarmクラスタ構成の対処)
- rabbitmq クラスタの障害 → rabbitmq の原因と対処(Mnesia 破損 / Partial partition / Waiting for Mnesia tables / erl_crash / pre_vote)
- rabbitmq が再起動を繰り返す / kengine が再起動を繰り返す
- 外部 DB(Pgpool)障害 → データベースの原因と対処(Host is unreachable / unable to read message kind / read-only / Connection refused)
- 静的ファイル(GlusterFS)エラー → KeyError: 'staticfiles'
- docker/swarm の障害 → docker の原因と対処(ネットワーク問題 / 高遅延 / node underweighting / ノードダウン / Gluster マウントなど)
この構成に固有の注意点
- 冗長化されているため、一部ノードの障害ではシステム全体としては正常動作が期待できます。system-status 画面で一部コンテナが NG でも HTTP ステータスが 200 となる場合があります。
- クラスタ固有の診断は クラスタノードの診断手順(swarm ノードのステータス / glusterfs の正常性)を参照してください。
- 全体的に復旧しない場合は KE2 APP を再起動する。重大な場合は rabbitmq のボリュームを削除する手順 が必要になることがあります。
ブラウザによる診断手順
ユーザによるブラウザ操作で実施できる基本的な診断手順を以下に示します。
参考: 各診断手順について、状況によってはその結果が成功と失敗を繰り返すような場合も想定されます。システムとしては正常に動作していないと考えられる場合は、診断結果の1回の成功だけで問題ないとは判断せずに、何度か試すようにしてみてください。
これらの診断で問題や原因箇所が見いだせない場合は、ブラウザ操作だけでは判断がつきません。 次の、コマンドによる診断手順に進んでください。
システムステータスによる診断手順
ブラウザで Kompira の /.status にアクセスしてシステムステータスを確認してください。
このシステムステータスのエンドポイントは KE v2.0.1 以降で利用できます。
format=jsonパラメータを付けて/.status?format=jsonにアクセスすると、結果を JSON 形式で得られます。
NG 表示パターンから原因候補を引く(早見表)
system-status 画面の NG 表示の組み合わせから、原因候補に直接たどり着けます。
| system-status 画面の表示 | 原因候補 |
|---|---|
redis が ERROR、kompira / kengine / jobmngrd が Dependent services (redis) are not running | redis が停止している |
postgres が ERROR、kompira / kengine / jobmngrd が Dependent services (postgres) are not running | postgres が停止している / データベース障害 |
| rabbitmq が ERROR(kengine / jobmngrd も ERROR になる場合あり) | rabbitmq が停止している |
| rabbitmq はアラーム、外形的に kengine / jobmngrd が ERROR | ディスクリソース制限アラーム / メモリリソース制限アラーム |
| HTTP 502 となる | kompira が停止している |
| kengine / jobmngrd が頻繁に変動する | コンテナが異常・再起動を繰り返す |
ステータスコードが 200(NG のコンテナがない場合)

ホストサーバおよび各コンテナは外形的には正常に動作していると考えられます。クラスタ構成の場合、kengine と jobmngrd を拡張し、3 台が正常に動作しているか確認することをおすすめします。
ステータスコードが 200(NG のコンテナがある場合)
1 つ以上のコンテナが NG として赤く表示される場合があります。
一部のコンテナで異常が発生していてもシステムとして正常動作が期待できる場合、HTTP ステータスは 200 となります。たとえばクラスタ構成では、冗長化されている kengine や rabbitmq が一部で異常でも過半数で動作していればシステム全体としては正常とみなします。
(例1) rabbitmq と kengine に異常がある場合

(例2) rabbitmq と kengine と jobmngrd に異常がある場合

(例3) 赤く異常を示している箇所をクリックすると詳細情報が表示されます

異常を示しているコンテナがある場合は、上記の早見表または コンテナが停止している から、それぞれのコンテナの調査に進んでください。
ディスクやメモリなどのリソースが不足し rabbitmq がアラームを発している場合は、外形的には kengine と jobmngrd がエラーとして表示されることがあります。この場合は ディスクリソース制限アラーム / メモリリソース制限アラームを調査してください。
ステータスコードが 502 となる場合

kompira コンテナに異常が生じている可能性があります。以下を確認してください。
ステータスコードが 503 となる場合
redis に障害が生じている場合

redis が停止している を調査してください。
postgres に障害が生じている場合

postgres が停止している を調査してください。
ブラウザでの基本操作による診断手順
ログインできるかの確認
ブラウザで Kompira にログインできるかを確認してください。
成功する場合
ログインに成功する場合は、nginx, redis, postgres, kompira コンテナは正常に動作していると考えられます。
⇒ 次の診断に進んでください。
失敗する場合
⇒ 応答がない場合 (This site can't be reached)に進んでください。
ログインに失敗する場合(パスワード間違いを除く)は、DB 障害が起きている可能性があります。
まだ解決できない場合は、以下も確認してください。
正常に画面表示ができるかの確認
ウェブサイトの UI が崩れている、またはリソースアクセスが 500 エラーとなる場合

クラスタ構成においては、以下を確認してください。
DB の更新操作が頻繁に失敗する場合
KE2 APP にアクセスはできるが、DB を更新しようとすると頻繁に操作が失敗する場合があります(ジョブフロー操作時など)。DB セッションの中断や DB 内の問題が原因のことがあります。
- 読み取り専用トランザクション
- pgpool 利用時: pgpool ノード間の不整合
ブラウザ画面表示の応答性が悪い場合
外部 DB として Pgpool を利用している場合は、KE2 APP ホストサーバと外部データベース間のネットワーク導通の確認 も確認してください。
コンテナもリソースも正常なのに高負荷で遅い・一部が失敗する場合は、環境変数の調整で改善できることがあります。応答が遅い・高負荷で不安定 を参照してください。
応答がない場合 (This site can't be reached)

様々な要因が考えられますので、以下の調査を実施してください。
- ホストサーバの正常性の確認
- ホストサーバのリソース状況の確認
- ネットワーク導通の確認
- docker の正常動作の確認
- クラスタ構成の場合、swarm ノードのステータスの正常性確認
- Docker コンテナで利用のリソース状況の確認
- nginx が停止しているかを確認してください。
ジョブフローの動作確認による診断手順
ジョブフローを実行できるかの確認
ブラウザから以下のようなジョブフローを実行できるか、成功するかを確認してください。
- 基本的には常に成功するジョブフロー
- リモートジョブを含まない ジョブフロー
- 既存の Kompira オブジェクトに影響を与えないジョブフロー
もっとも単純には、次のジョブフローを実行してみてください。
print('OK')
ジョブフローが実行できない場合
いくつかの要因が考えられます。
- ライセンスが有効か、期限内かを確認してください。
- 実行中プロセス数が制限を超えていないか確認してください。
- すでにジョブフロープロセスが多数動作しているなら、ジョブフローの実行自体はできています(次の診断へ)。ただし多数動作していること自体が想定外であれば、ジョブフローの設計や実装に問題がある可能性があります。
上記に該当しない場合は、rabbitmq や kengine コンテナで障害が起きている可能性があります。
ジョブフローの実行はできるが異常終了する場合
まずジョブフロー自体に問題がないか確認してください(プロセスログの確認、実装上エラーになる状況でないか)。該当しない場合は、rabbitmq / kengine コンテナのいずれかで障害が起きている可能性があります。
クラスタ構成の場合は、以下に該当するか調査してください。
ジョブフローが正常終了する場合
rabbitmq, kengine コンテナは正常に動作していると考えられます。⇒ 次の診断に進んでください。
失敗する場合、または成否が安定しない場合
rabbitmq, kengine コンテナのいずれかで障害が起きている可能性があります。⇒ コンテナの診断手順を進んでください。
リモートジョブが実行できるかの確認
ブラウザから以下のようなリモートジョブを実行できるか確認してください。
- 基本的には常に成功するジョブフロー
- リモートジョブを含む ジョブフロー
- 既存の Kompira オブジェクトに影響を与えないジョブフロー
もっとも単純には、次のジョブフローを実行してみてください。
['echo OK']
成功する場合
rabbitmq, kengine, jobmngrd コンテナは正常に動作していると考えられます。⇒ 次の診断に進んでください。
失敗する場合、または成否が安定しない場合
- ジョブフロー自体に問題がないか確認してください。
- rabbitmq, kengine, jobmngrd コンテナのいずれかで障害が起きている可能性があります。
コマンド操作による診断手順
管理者によるコマンド操作によって実施できる診断手順を以下に示します。この診断手順ではホストサーバに SSH でログインして操作する必要があります。
一部は「ブラウザ操作による診断手順」と診断内容が重複しているものもあります。また診断手順によっては管理者権限が必要になりますのでご注意ください。
問題箇所の推定が出来ていない場合は、上から順次実施してみてください。
- ホストサーバの診断手順
- Swarmクラスタ構成の場合、クラスタノードの診断手順
- コンテナの診断手順
ホストサーバの診断手順
コマンド操作によって実施できるホストサーバの診断手順を示します。一部は「ブラウザによる診断手順」と内容が重複します。
なお、この診断手順ではホストサーバに SSH でログインして操作する必要があります。診断手順によっては管理者権限が必要になりますのでご注意ください。
ホストサーバの正常性の確認
システムのホストサーバが正常に動作していることを、以下の観点で確認してください。クラスタ構成の場合は全てのノードの状態を確認してください。
- SSH またはコンソールで対象ノードにログインできる。
- ホスト名およびネットワークアドレスが正しく構成されている。
- 所属ネットワークへの導通(例えばデフォルトゲートウェイへの ping)が確認できる。
いずれかの確認で問題がある場合は、Kompira システム以前に、まずホストサーバについて適切な保守対応を実施して正常化を行なってください。
ホストサーバの保守手順については、本マニュアルの範囲外になります。
クラスタ構成の場合は、さらに以下も確認してください。
- 2 台目以上のノードを起動している場合は、クラスタを構成するノード間の導通も確認してください。導通が確認できない場合はクラスタが正常に動作しませんので、ネットワークの状態の確認と正常化を行なってください。
- クラスタを構成する半数以下のノードしか起動していない場合は、クラスタとして開始できません。クラスタの開始 を参考に適切にクラスタの開始を行なってください。
シングル構成でホストサーバに問題が無い場合、または、クラスタ構成で過半数のノードが正常に動作している場合は、次の診断に進んでください。
ホストサーバのリソース状況の確認
KE2 APP にパフォーマンスの低下(遅延・エラー頻発)が見られる場合、ホストサーバのリソースが過負荷になっている可能性があります。以下を確認してください。クラスタ構成の場合は全てのノードを確認してください。
- CPU 使用率
- メモリ使用率
- ディスク使用率
とくにディスク使用率については、空き容量が少なくなるとシステムが正常に動作できなくなる場合があります。例えば rabbitmq コンテナは空き容量が一定以下(デフォルト 50MB 以下)になると一部の動作を停止します。
参考: 目安としては、常に 200MB 以上の空き容量がある状況を維持してください。
リソース使用率が常に高い(例えば 90% 以上)か、増加し続けて下がらない場合、Docker や KE2 APP でさまざまなエラーが発生する可能性があります。以下では sysstat(sar)による確認手法を示しますが、監視システムの導入も検討してください。
sar コマンドが利用できない場合は、sysstat パッケージをインストールしてください。
-
CPU 使用率を確認する
数日分の平均 CPU 使用量を確認します(sysstat が以前からインストールされている前提)。
$ sar -u -f /var/log/sa/sa$(date --date="1 days ago" +%d) $ sar -u -f /var/log/sa/sa$(date --date="today" +%d)sysstat が以前からインストールされていなかった場合は最新状況を確認します。
$ sar -u 2 30 08:50:01 PM CPU %user %nice %system %iowait %steal %idle 09:00:01 PM all 2.44 1.37 1.82 0.01 0.00 94.37 Average: all 2.34 1.60 1.81 0.01 0.00 94.24%userまたは%system使用率が常に 90% を超える場合は CPU コア数を増やすことを検討してください。増加し続けて下がらない場合は、CPU を多く消費しているプロセスを特定します。$ ps aux --sort=-%cpu | head USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 2956484 1.3 1.0 108636 84416 ? Sl Oct29 18:29 kompirad: [Engine-5931] started root 4041128 0.7 3.8 2974996 299280 ? Ssl Oct27 31:20 /usr/bin/dockerd -H fd:// ...KE2 APP に関係する処理(kompirad / kompira_jobmngrd / dockerd など)で高消費の場合は、Docker コンテナで利用のリソース状況の確認 を確認してください。
特に kompirad:Executor の CPU 使用量が急増する場合は、ジョブフローの設計や実装を見直してください。
-
メモリ使用率を確認する
$ sar -r -f /var/log/sa/sa$(date --date="today" +%d) # sysstat が未導入だった場合 $ sar -r 2 30 08:50:04 PM kbmemfree kbavail kbmemused %memused kbbuffers kbcached ... 09:00:00 PM 1499600 2776648 6369344 80.94 132 1455240 ... Average: 1193391 2697519 6675553 84.83 132 1564541 ...%memusedが常に 90% を超える場合はメモリを増やすことを検討してください。増加し続けて下がらない場合は、メモリを多く消費しているプロセスを特定します。$ ps aux --sort=-%mem | head USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 4041128 0.7 3.8 2974996 299280 ? Ssl Oct27 31:28 /usr/bin/dockerd -H fd:// ... root 2957006 0.5 2.6 1344704 204640 ? Sl Oct29 7:29 /opt/erlang/.../beam.smp ... rabbit ... -
ディスクスペースを確認する
$ df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/rhel-root 38G 13G 25G 34% / localhost:/gvol0 38G 14G 25G 36% /mnt/gluster空きスペースが不足している場合は不要なファイルを削除してください。
ホストサーバが高いリソースを使用している場合、Docker デーモンが不安定になる可能性があります。その際は docker ログを確認してください。
- クラスタ構成: Docker 不安定性(node underweighting) / error while reading from stream
- シングル構成: docker デーモンが不安定
docker の正常動作の確認
全てのノードで docker が正常に動作していることを確認してください。
$ systemctl status docker.service
docker.service - Docker Application Container Engine
Active: active (running) since Tue 2024-10-01 14:53:15 JST; 1 weeks 2 days ago
Active: active (running) であれば実行中です。何らかの異常で停止している場合は Active: inactive (dead)
と表示されます。
docker.service - Docker Application Container Engine
Active: inactive (dead) since Thu 2024-10-10 16:57:52 JST; 2s ago
停止している場合は起動して再度ステータスを確認してください。
$ systemctl start docker.service
起動しても安定して動作しない場合は docker のログを確認してください。
- クラスタ構成: Docker 不安定性(node underweighting)
- シングル構成: docker デーモンが不安定
- あわせて ホストサーバのリソース状況の確認
ネットワーク導通の確認
クライアントとホスト間のネットワーク導通を確認してください。
$ ping -c 5 <HOST_SERVER_IP>
64 bytes from 10.20.47.12: icmp_seq=1 ttl=64 time=0.041 ms
...
5 packets transmitted, 5 received, 0% packet loss, time 4103ms
応答がない場合は次のように表示されます(Destination Host Unreachable など)。
From 10.20.47.12 icmp_seq=1 Destination Host Unreachable
...
5 packets transmitted, 0 received, +5 errors, 100% packet loss, time 4094ms
この場合は以下を確認してください。
- ホストサーバの正常性の確認
- KE2 APP ホストサーバのネットワークインターフェイスの状態
- KE2 APP ホストサーバの Network 設定
クラスタ構成の場合は、KE2 APP ホストサーバの全ノード間のネットワーク導通も確認してください。導通に問題があるときは docker ログにエラーが記録されている場合があります。
ping が成功していても高い遅延・パケットロスがある場合があります(ping -c 10 -i 2 <IP> で確認)。高遅延の場合、docker
ログに以下が表示される可能性があります。
ネットワークの保守手順については、本マニュアルの範囲外になります。
KE2 APP ホストサーバと外部データベース間のネットワーク導通の確認
外部DBシングル構成・Swarmクラスタ構成では外部 DB が使用されます。KE2 APP ホストサーバと外部データベース間のネットワーク接続に問題があると、kompira / kengine コンテナに直接影響します。
外部 DB サーバへ ping しても応答がない場合は、外部 DB ホストサーバの正常性・ネットワークインターフェイス・Network
設定を確認してください。KE2 のログには以下が記録される可能性があります。
- docker ログ: 外部データベースまたは Swarm ノードとの高いネットワーク遅延
- kengine ログ: 外部 DB へ到達不可(Host is unreachable)
ping が成功していても高い遅延の可能性があります(ping -c 10 -i 2 <DB_IP>)。高遅延・パケットロスがあれば解決してください。
外部 DB で Pgpool を利用している場合、Pgpool ノード間のネットワーク遅延も確認してください。問題があると KE2 に影響し、ログに以下が表示される可能性があります。
ネットワークの保守手順については、本マニュアルの範囲外になります。
外部データベースへのアクセス確認
KE2 APP のホストサーバから外部 DB にアクセスできるか確認します。
psql コマンドが利用できない場合は、CentOS/RHEL: postgresql、Debian/Ubuntu: postgresql-client をインストールしてください。
# pgpool 場合 DB IP は Virtual IP、DB PORT は既定 9999。postgres 場合は DB サーバ IP、既定 5432。USER は postgres、DATABASE は kompira。
$ psql -h <DB_IP> -p <DB_PORT> -U postgres -d kompira -c "SELECT 1;"
アクセスに失敗する場合(No route to host など)は、DB サーバダウンまたはネットワーク到達不可が考えられます。KE2
のログに以下が記録される場合があります。
DB 操作の確認
$ psql -h <DB_IP> -p <DB_PORT> -U postgres -d kompira -c "CREATE TEMP TABLE pg_temp.test_table (value TEXT); INSERT INTO pg_temp.test_table (value) VALUES ('Dummy Test Value'); SELECT * FROM pg_temp.test_table;"
問題があれば外部 DB 管理者に連絡してください。KE2 のログに以下が記録される場合があります。
外部 DB の保守手順については、本マニュアルの範囲外になります。
クラスタ構成における共有ファイルシステム glusterd の正常動作の確認
全てのノードで glusterd が正常に動作していることを確認してください。
$ systemctl status glusterd
glusterd.service - GlusterFS, a clustered file-system server
Active: active (running) since Mon 2024-09-23 19:31:39 JST; 3 weeks 3 days ago
Active: active (running) であれば実行中です。停止している場合は Active: inactive (dead)
と表示されます。停止している場合は起動して再度ステータスを確認してください。
$ systemctl start glusterd
起動しても不安定な場合は、主にホストサーバのリソースが正常かどうかを確認してください(ホストサーバのリソース状況の確認)。
クラスタの glusterfs ボリューム自体の正常性確認は クラスタノードの診断手順 を参照してください。
クラスタノードの診断手順
Swarmクラスタ構成における、共有ファイルシステム(glusterfs)と swarm ノードの診断手順を示します。
共有ファイルシステム(glusterfs)の正常性確認
glusterd の正常性確認
すべての glusterd ノードの State が Connected であることを確認してください。
$ gluster pool list
UUID Hostname State
448d38ce-bc9c-4bca-ae77-8876cbb4ab32 ke2-rhel89-swarm-1 Connected
28cdd9bc-4a49-48ac-a7ab-635f35e90bda ke2-rhel89-swarm-3 Connected
0760ce31-9b1e-4697-980e-721bbd0f4862 localhost Connected
いずれかのノードの State が Disconnected の場合は、そのホストの glusterd
サービスが正常に動作していないか、ネットワークに問題が生じている可能性があります。
$ gluster pool list
UUID Hostname State
448d38ce-bc9c-4bca-ae77-8876cbb4ab32 ke2-rhel89-swarm-1 Disconnected
28cdd9bc-4a49-48ac-a7ab-635f35e90bda ke2-rhel89-swarm-3 Connected
0760ce31-9b1e-4697-980e-721bbd0f4862 localhost Connected
この場合、以下を確認してください。
上記の対策を行なっても回復しない場合は、問い合わせ前に情報を収集のうえ、サポートへお問い合わせください。
gluster ボリュームの正常性確認
すべてのノードの gluster ボリューム状態 Status が Started であることを確認してください。
$ gluster volume info
Volume Name: gvol0
Type: Replicate
Status: Started
Number of Bricks: 1 x 3 = 3
...
ボリューム Status が Stopped の場合は、そのノードのボリュームが停止されている可能性があります。
$ gluster volume info
Volume Name: gvol0
Type: Replicate
Status: Stopped
Number of Bricks: 1 x 3 = 3
...
以下のコマンドでボリュームを起動してください。
$ gluster volume start <VOLUME_NAME>
gluster ボリュームのマウントの正常性確認
すべての glusterd ノードで gluster ボリュームがマウントされていることを確認してください。mount コマンドで
localhost:/gvol0 on /mnt/gluster の表示があるはずです。
$ mount | grep gluster
localhost:/gvol0 on /mnt/gluster type fuse.glusterfs (rw,relatime,...)
マウントされていない場合は、以下のコマンドでマウントしてください。
$ mount -t glusterfs localhost:/gvol0 /mnt/gluster
特定のノードで gluster ボリュームが正しくマウントされない場合、kompira コンテナのログにエラーが記録されることがあります。静的ファイルにアクセスできない(KeyError: 'staticfiles') を参照してください。
swarm ノードのステータスの正常性確認
docker node ls の結果から以下を確認してください。
- すべてのノードの STATUS が
Readyであること。 - すべてのノードの AVAILABILITY が
Activeであること。 - MANAGER STATUS は 1 台が
Leader、残りがReachableであること。 - すべてのノードの ENGINE VERSION が同一であること。
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
fki8ndj78y2khgyt7j6xn2duf ke2-rhel89-swarm-1 Ready Active Reachable 26.1.3
ly4ik4v3pw9rgom0htt281aus * ke2-rhel89-swarm-2 Ready Active Reachable 26.1.3
if1r8znj7v7dsym4r9ya26gmt ke2-rhel89-swarm-3 Ready Active Leader 26.1.3
マネージャーの半数以上がオンラインでない場合
docker node ls が次のようなエラーを返します。全てのノードで以下の診断を行なってください。
$ docker node ls
Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader.
It's possible that too few managers are online. Make sure more than half of the managers are online.
問題を修正後、docker node ls で STATUS / AVAILABILITY / MANAGER STATUS が正常であれば
KE2
クラスタは正常です。まだ正常でない場合は、必要なポートが開いていない可能性があります(ファイアウォールの設定)。それでも戻らない場合は各
VM を一度再起動してみてください。
クラスタが正常に戻っても KE2 APP が全体的に操作できない場合は、まずすべてのノードの gluster ボリュームの正常性確認を行ってください。そのうえで KE2 APP を再デプロイしてください。
[いずれかのノード]$ docker stack rm ke2
[いずれかのノード]$ cd ke2/cluster/swarm
[いずれかのノード]$ docker stack deploy -c docker-swarm.yml ke2
最後に KE2 APP の全体ステータス を確認してください。
いずれかのノードの MANAGER STATUS が Unreachable・STATUS が Down の場合
そのノードが停止している可能性があります。
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
fki8ndj78y2khgyt7j6xn2duf ke2-rhel89-swarm-1 Down Active Unreachable 26.1.3
ly4ik4v3pw9rgom0htt281aus * ke2-rhel89-swarm-2 Ready Active Reachable 26.1.3
if1r8znj7v7dsym4r9ya26gmt ke2-rhel89-swarm-3 Ready Active Leader 26.1.3
問題があるノードで以下の分析を行ってください。
問題が解決できない場合、必要なポートが開いていない可能性があります(ファイアウォールの設定)。それでも解決しない場合は、問題があるノードを再起動してください。docker と glusterfs の自動起動設定があれば、そのノードに関係するコンテナが自動回復します。起動後、KE2 APP の全体ステータス を確認してください。
上記の対策を行なっても回復しない場合は、問い合わせ前に情報を収集のうえ、サポートへお問い合わせください。
コンテナの診断手順
Docker コンテナで利用のリソース状況の確認
Docker コンテナのリソース状況(CPU・メモリ・PID 数)を確認してください。クラスタ構成の場合は全てのノードを確認してください。
$ docker stats --no-stream
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
b2bf672eee1e ke2_jobmngrd.3... 0.20% 36.84MiB / 7.504GiB 0.48% 6.98kB / 6.99kB 0B / 0B 8
6f1befa797c4 ke2_kengine.2... 3.04% 392.7MiB / 7.504GiB 5.11% 264kB / 236kB 16.4kB / 0B 43
31d90be86621 ke2_kompira.2... 1.57% 220.6MiB / 7.504GiB 2.87% 458kB / 520kB 328kB / 0B 16
-
いずれかのコンテナの CPU・メモリ・I/O 使用率が高い(例えば 95% 超)場合、KE2 APP の動作が非常に遅いか異常になっている可能性があります。その場合は特定のコンテナを再起動し、KE2 APP の状況を確認してください。
$ docker restart <CONTAINER_ID> -
複数コンテナで使用率が高い場合は、KE2 APP を再起動するを実施してください。
Docker コンテナの正常性の確認
Docker コンテナはさまざまな理由で異常になる可能性があります(高負荷による停止、内部エラーによる停止、外部 DB アクセス問題による停止・再起動の繰り返しなど)。
構成によって VM 上で動作するコンテナ数が異なります。
- 標準シングル構成(1 VM・7 コンテナ): nginx / redis / kompira / kengine / postgres / rabbitmq / jobmngrd
- 外部DBシングル構成(1 VM・6 コンテナ): nginx / redis / kompira / kengine / rabbitmq / jobmngrd
- Swarmクラスタ構成(3 VM): 各ノードで nginx / kompira / kengine / rabbitmq / jobmngrd、いずれか 1 ノードで redis
シングル構成での確認
実行中コンテナの一覧を確認します(標準シングル構成の例)。
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS ... NAMES
32fe4cedfab3 registry.hub.docker.com/library/nginx:1.27-alpine "/docker-entrypoint.…" 6 days ago Up 6 days ke2-nginx-1
6d63244c268c kompira.azurecr.io/kompira-enterprise:latest "docker-entrypoint.s…" 6 days ago Up 6 days ke2-kompira-1
5a8808b6f97b kompira.azurecr.io/kompira-enterprise:latest "docker-entrypoint.s…" 6 days ago Up 6 days ke2-kengine-1
c2a13a549267 kompira.azurecr.io/kompira-enterprise:latest "docker-entrypoint.s…" 6 days ago Up 6 days ke2-jobmngrd-1
9af8671ec4b8 registry.hub.docker.com/library/rabbitmq:3.13-alpine "docker-entrypoint.s…" 6 days ago Up 6 days ke2-rabbitmq-1
c53e47ff9826 registry.hub.docker.com/library/redis:7.2-alpine "docker-entrypoint.s…" 6 days ago Up 6 days ke2-redis-1
35f1ae144b49 registry.hub.docker.com/library/postgres:16.3-alpine "docker-entrypoint.s…" 6 days ago Up 6 days ke2-postgres-1
各コンテナのステータスが Up であるべきです。手動で再起動していないのに、作成からの経過時間(CREATED 列)と Up の稼働時間が大きく異なる場合は、途中で問題が発生し再起動された可能性があります。再起動回数は次で確認できます。
$ docker inspect --format='{{.RestartCount}}' <CONTAINER_ID>
Up 期間が短く頻繁に変わる場合は
コンテナが異常・再起動を繰り返す、コンテナが一覧にない(停止している)場合は
コンテナが停止している を参照してください。
クラスタ構成での確認
サービスの状態を確認します。5 つのサービスは REPLICAS が 3/3、redis サービスは 1/1 であるべきです。
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
rurnpyfpcktj ke2_jobmngrd replicated 3/3 (max 1 per node) kompira.azurecr.io/kompira-enterprise:latest
tnu0hcrabygs ke2_kengine replicated 3/3 (max 1 per node) kompira.azurecr.io/kompira-enterprise:latest
sdbpxueuch8b ke2_kompira replicated 3/3 (max 1 per node) kompira.azurecr.io/kompira-enterprise:latest
k5oo0qcki35j ke2_nginx replicated 3/3 (max 1 per node) registry.hub.docker.com/library/nginx:1.27-alpine *:80->80/tcp, *:443->443/tcp
0hcwtac3ode7 ke2_rabbitmq replicated 3/3 (max 1 per node) registry.hub.docker.com/library/rabbitmq:3.13-alpine *:5671->5671/tcp
ccind6pgdon6 ke2_redis replicated 1/1 registry.hub.docker.com/library/redis:7.2-alpine
# 特定サービスの詳細(CURRENT STATE が Shutdown/Failed を繰り返していないか確認)
$ docker service ps <SERVICE_NAME>
CURRENT STATE が Running でも短期間で Shutdown / Failed を繰り返す場合は
コンテナが異常・再起動を繰り返す、Running でない場合は
コンテナが停止している を参照してください。
KE2 APP を再起動する
さまざまな調査でも KE2 APP が正常に戻らない場合、以下の方法で再起動してください。
標準シングル構成
$ systemctl restart docker.service
その後 KE2 APP の全体ステータス を確認してください。まだ戻らない場合は ホストサーバを再起動 してみてください。
外部DBシングル構成
$ systemctl restart docker.service
その後 KE2 APP の全体ステータス を確認してください。まだ戻らない場合はホストサーバを再起動してみてください。
Swarmクラスタ構成
3 台のうち 1 台で KE2 APP の操作が停止した場合: エラーが発生している VM で docker
サービスを再起動します(systemctl restart docker.service)。起動後
ノードの KE2 APP のステータス
を確認してください。戻らない場合はその VM を再起動
してみてください。
KE2 APP の操作が全体的に停止した場合: 各 VM で docker サービスを再起動し、KE2 APP の全体ステータス を確認します。戻らない場合は全 VM を再起動、それでも戻らない場合はクラスタを再デプロイしてください。
[いずれかのノード]$ docker stack rm ke2
[いずれかのノード]$ cd ke2/cluster/swarm
[いずれかのノード]$ docker stack deploy -c docker-swarm.yml ke2
rabbitmq のボリュームを削除する手順
推奨がない場合は、この手順を実行しないでください。
RabbitMQ のボリュームが破損し、KE2 APP の操作が全体的に異常になる場合があります。クラスタ構成の障害回復手順のひとつとして、rabbitmq が利用しているボリュームを削除してからクラスタを再デプロイする方法があります。
まずクラスタを削除します。
[いずれかのノード]$ docker stack rm ke2
ボリューム名を確認し、全てのノードで rabbitmq ボリュームを削除します。
[いずれかのノード]$ docker volume ls
[すべてのノード]$ docker volume rm swarm_kompira_rmq
その後、KE2 APP を再デプロイします。
[いずれかのノード]$ cd ke2/cluster/swarm
[いずれかのノード]$ docker stack deploy -c docker-swarm.yml ke2
原因と対処(コンポーネント別)
各コンポーネントのログに記録されるエラーから、原因と対処を調べます。手元のエラーログやエラーメッセージがある場合は、本ページ右上の検索でエラーメッセージを検索すると該当箇所に直接たどり着けます。
コンポーネント別の調査
- kengine(ジョブフロー実行エンジン) — redis / rabbitmq 接続エラー
- データベース(postgres / 外部DB / pgpool) — DB 接続エラー
- rabbitmq — ディスク/メモリアラーム、クラスタ関連エラー
- kompira — 静的ファイル(GlusterFS)エラー
- jobmngrd(ジョブマネージャ) — AMQP 接続エラー
- nginx — upstream timed out
- docker — docker デーモン/Swarm 関連エラー
- 高負荷時のチューニング(環境変数) — 接続数上限・Web ワーカ枯渇・タイムアウト
ログの採取手順
Docker コンテナのログ確認手順
Docker コンテナのログを確認する手順については、以下を参照してください。
Docker Swarm 構成でサービス単位のログを確認する手順については、以下を参照してください。
なお、本セクションに記載したログのサンプルは、以下のようなホスト構成で取得したものです。
| IP | Host Name | Comment |
|---|---|---|
| 10.20.47.11 | ke2-rhel89-swarm-1 | シングル構成、外部DBシングル構成、クラスタ構成(1号機) |
| 10.20.47.12 | ke2-rhel89-swarm-2 | クラスタ構成(2号機) |
| 10.20.47.13 | ke2-rhel89-swarm-3 | クラスタ構成(3号機) |
| 10.20.47.20 | DB VIP (pgpool/postgres) | クラスタ構成、外部DBシングル構成 |
その他サービスのログ確認手順
コンテナ以外の各サービスのログを確認する方法については、OS ごとのログ管理の手順を確認してください。以下では Linux で一般的な journalctl
コマンドによる確認手順の例を示します(使い方は man journalctl を参照)。
docker サービスのログ確認
$ journalctl -u docker
# or
$ journalctl -u docker.service
# 最新 N 行のみ確認する場合は -n オプションを指定します
$ journalctl -u docker -n 10
glusterfs サービスのログ確認
$ journalctl -u glusterd
$ journalctl -u glusterd -n 10
$ journalctl -u glusterd --since today
kengine(ジョブフロー実行エンジン)の原因と対処
kengine コンテナのログに記録されるエラーから、原因と対処を調べます。
kengine が依存先(redis / rabbitmq)に接続できないときのエラーをここで扱います。データベース(postgres / 外部 DB / pgpool)への接続エラーは データベースの原因と対処 を参照してください。
redis 名前解決エラー(Error -2 connecting to redis:6379)
観測される症状・影響
redis に接続できないため、システム全体が応答しなくなります(ブラウザ操作の応答なし/内部処理エラー、ジョブフローの停止)。system-status
画面では redis が ERROR となり、kompira / kengine / jobmngrd が
Dependent services (redis) are not running となります。
- 影響範囲: redis の役割と影響範囲
- 症状から探す: コンテナが停止している(redis)
主なエラーメッセージ
redis.exceptions.ConnectionError: Error -2 connecting to redis:6379. Name does not resolve.
ログのサンプルエントリ
Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/kompira/core/cache.py", line 55, in get_object
cache.touch(key)
File "/usr/local/lib/python3.11/site-packages/django/core/cache/backends/redis.py", line 195, in touch
return self._cache.touch(key, self.get_backend_timeout(timeout))
File "/usr/local/lib/python3.11/site-packages/django/core/cache/backends/redis.py", line 115, in touch
return bool(client.expire(key, timeout))
File "/usr/local/lib/python3.11/site-packages/redis/commands/core.py", line 1762, in expire
return self.execute_command("EXPIRE", name, time, *exp_option)
File "/usr/local/lib/python3.11/site-packages/redis/client.py", line 1266, in execute_command
conn = self.connection or pool.get_connection(command_name, **options)
File "/usr/local/lib/python3.11/site-packages/redis/connection.py", line 1461, in get_connection
connection.connect()
File "/usr/local/lib/python3.11/site-packages/redis/connection.py", line 713, in connect
raise ConnectionError(self._error_message(e))
redis.exceptions.ConnectionError: Error -2 connecting to redis:6379. Name does not resolve.
原因
redis が停止している、または他コンテナから redis にアクセスできない状態になっています。Swarm クラスタ構成では、redis を実行中のノードに以下のような問題が生じると、redis が別のノードに切り替わる(フェイルオーバーする)過程でこのエラーが発生することがあります。
- 実行中ノードのダウン・再起動
- 実行中ノードのリソース使用率が高い
- swarm ノード間のネットワーク導通の問題
- 実行中ノードの docker 停止・再起動
構成別の対処
オンプレシングル構成
以下のコマンドで redis コンテナのステータスを確認してください。
$ docker ps -a -f name=redis
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c53e47ff9826 registry.hub.docker.com/library/redis:7.2-alpine "docker-entrypoint.s…" 16 minutes ago Exited (1) 12 seconds ago ke2-redis-1
ステータスが Up の場合はコンテナとしては起動しているため、コンテナ停止以外の問題が起きていると考えられます。ホストサーバや docker サービス、ネットワークなどの状態を確認してみてください。
ステータスが Up 以外の場合は、停止しているコンテナの最新の ID を指定して再起動してください。
$ docker restart <REDIS_CONTAINER_ID>
Swarmクラスタ構成
クラスタ構成では redis は 1 ノードでのみ実行されるサービスで、ノード障害時には自動的に別ノードへ切り替わります。redis サービスが不安定かどうかを確認してください。
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
...
l76bm4t1wf6n ke2_redis replicated 1/1 registry.hub.docker.com/library/redis:7.2-alpine
ke2_redis は replicated 1/1 であるべきです。不安定な場合は上のコマンドを数回実行すると 0/1, 1/1, 0/1
と変化します。詳細は以下で確認できます。
$ docker service ps ke2_redis
CURRENT STATE が短期間で Shutdown を繰り返している場合、redis が不安定です。以下の手順で対処してください。
-
swarm ノードのステータスを確認してください(swarm ノードのステータスの正常性確認)。異常があれば解決してください。
-
swarm ノードが正常な場合、redis サービスを再起動してください。
$ docker service update --force ke2_redis
解決しない場合
KE2 APP を再起動するを試してください。それでも回復しない場合は問い合わせ前に情報を収集のうえ、サポートへお問い合わせください。
rabbitmq 名前解決エラー(nc: bad address 'rabbitmq')
対象構成: オンプレシングル構成。Swarmクラスタ構成の rabbitmq 障害は rabbitmq の原因と対処 を参照してください。
観測される症状・影響
rabbitmq に接続できないため、コンテナ間の連携(ブラウザ操作からのジョブフロー実行指示、kengine と jobmngrd の連携など)ができなくなります。
- 影響範囲: rabbitmq の役割と影響範囲
- 症状から探す: コンテナが停止している(rabbitmq)
主なエラーメッセージ
nc: bad address 'rabbitmq'
ログのサンプルエントリ
nc: bad address 'rabbitmq'
nc: bad address 'rabbitmq'
nc: bad address 'rabbitmq'
nc: bad address 'rabbitmq'
nc: bad address 'rabbitmq'
原因
rabbitmq が停止している可能性があります。
解決策
以下のコマンドで rabbitmq コンテナのステータスを確認してください。
$ docker ps -a -f name=rabbitmq
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9af8671ec4b8 registry.hub.docker.com/library/rabbitmq:3.13-alpine "docker-entrypoint.s…" 16 minutes ago Exited (1) 12 seconds ago ke2-rabbitmq-1
ステータスが Up の場合はコンテナとしては起動しているため、コンテナ停止以外の問題が起きていると考えられます。ホストサーバや docker サービス、ネットワークなどの状態を確認してみてください。
ステータスが Up 以外の場合は、停止しているコンテナの最新の ID を指定して再起動してください。
$ docker restart <RABBITMQ_CONTAINER_ID>
再起動しても正常に戻らない場合は、rabbitmq コンテナ内部で動作している rabbitmq アプリをリセットしてみてください。
$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl stop_app
$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl reset
$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl start_app
解決しない場合
KE2 APP を再起動するを試してください。それでも回復しない場合は問い合わせ前に情報を収集のうえ、サポートへお問い合わせください。
データベース(postgres / 外部DB / pgpool)の原因と対処
kengine / kompira コンテナのログに記録されるデータベース接続エラーから、原因と対処を調べます。データベースの構成(ローカル postgres コンテナ/外部 DB/pgpool)によって発生するエラーと対処が異なります。
構成とデータベースの対応:
- 標準シングル構成: postgres はローカルのコンテナ(
ke2-postgres-1)- 外部DBシングル構成 / Swarmクラスタ構成: postgres は外部に配置(クラスタは pgpool 経由、既定ポート 9999)
DB 接続数の上限超過(
FATAL: sorry, too many clients already)による 500 エラーは、接続エラーではなくチューニングの問題です。データベース接続数の上限超過 を参照してください。
観測される症状・影響
データベースに接続できないため、システム全体が影響を受けます(ブラウザ操作・REST-API の応答不可、ジョブフローの停止)。
- 影響範囲: postgres の役割と影響範囲
- 症状から探す: コンテナが停止している(postgres)
ローカル DB 停止(nc: bad address 'postgres')
対象構成: 標準シングル構成(ローカル postgres コンテナ)
主なエラーメッセージ
psycopg2.OperationalError: could not translate host name "postgres" to address: Name does not resolvenc: bad address 'postgres'
ログのサンプルエントリ
psycopg2.OperationalError: could not translate host name "postgres" to address: Name does not resolve
nc: bad address 'postgres'
nc: bad address 'postgres'
nc: bad address 'postgres'
原因
postgres コンテナが停止している可能性があります。
解決策
以下のコマンドで postgres コンテナのステータスを確認してください。
$ docker ps -a -f name=postgres
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
35f1ae144b49 registry.hub.docker.com/library/postgres:16.3-alpine "docker-entrypoint.s…" 16 minutes ago Exited (1) 12 seconds ago ke2-postgres-1
ステータスが Up の場合はコンテナとしては起動しているため、コンテナ停止以外の問題が起きていると考えられます。ホストサーバや docker サービス、ネットワークなどの状態を確認してみてください。
ステータスが Up 以外の場合は、停止しているコンテナの最新の ID を指定して再起動してください。
$ docker restart <POSTGRES_CONTAINER_ID>
KE2 APP が正常に戻らない場合は、docker サービスを再起動してみてください。
$ systemctl restart docker.service
解決しない場合
問い合わせ前に情報を収集のうえ、サポートへお問い合わせください。
外部 DB へ到達不可(Host is unreachable)
対象構成: 外部DBシングル構成・Swarmクラスタ構成
観測される症状・影響
KE2 APP と外部データベースサーバ間でネットワーク接続の問題が発生しています。
主なエラーメッセージ
psycopg2.OperationalError: connection to server at "<DB_IP>", port <DB_PORT> failed: Host is unreachable
ログのサンプルエントリ
psycopg2.OperationalError: connection to server at "10.20.47.20", port 5432 failed: Host is unreachable
Is the server running on that host and accepting TCP/IP connections?
上記サンプルのポート
5432は外部 DB へ直接接続する構成での PostgreSQL 既定値です。pgpool/クラスタ経由で接続する構成では既定9999になるなど、構成により異なります。
原因
KE2 APP から外部 DB ホストサーバへ ping しても応答がない状況で発生します。
解決策
以下を確認してください。
- 外部 DB ホストサーバの正常性
- 外部 DB ホストサーバのネットワークインターフェイスの状態
- 外部 DB ホストサーバの Network 設定
あわせて KE2 APP ホストサーバと外部データベース間のネットワーク導通の確認 を実施してください。
外部 DB ホストサーバやネットワークなどの保守手順については、本マニュアルの範囲外になります。
pgpool ノード間の不整合(unable to read message kind)
対象構成: 外部DBシングル構成・Swarmクラスタ構成(pgpool 利用時)
主なエラーメッセージ
ERROR: unable to read message kind /
DETAIL: kind does not match between main(4e) slot[1] (53)
ログのサンプルエントリ
Reconnecting to the database didn't help connection to server at "10.20.47.20", port 9999 failed: ERROR: unable to read message kind
DETAIL: kind does not match between main(4e) slot[1] (53)
psycopg2.OperationalError: connection to server at "10.20.47.20", port 9999 failed: ERROR: unable to read message kind
DETAIL: kind does not match between main(4e) slot[1] (53)
原因
DB クラスタ(pgpool)利用時に、DB ノード間のネットワーク遅延や DB サーバのリソース使用率が高い場合、ノード間でデータの同期が取れず発生することがあります。
- pgpool ノード間の通信問題: ネットワークの問題により pgpool ノード間で適切な調整ができず、ノード間でデータの同期が取れない。
- pgpool ノードのリソース使用率が高い: pgpool VM で CPU・メモリ・I/O の使用率が高いと、データベース操作が遅くなりノード間で同期が取れない。
解決策
KE2 APP ホストサーバと外部データベース間のネットワーク導通の確認(pgpool ノード間のネットワーク遅延確認を含む)を実施してください。
外部 DB ホストサーバやネットワークなどの保守手順については、本マニュアルの範囲外になります。
読み取り専用トランザクション(cannot execute UPDATE in a read-only transaction)
対象構成: 外部DBシングル構成・Swarmクラスタ構成
主なエラーメッセージ
database error: cannot execute UPDATE in a read-only transaction
ログのサンプルエントリ
ERROR: Failed to start due to database error: cannot execute UPDATE in a read-only transaction
原因
データベースの不整合、または DB クラスタ(pgpool)がフェイルオーバーを実行し、アプリケーションが依然として古いプライマリノード(現在は読み取り専用モード)に接続されている可能性があります。
解決策
-
外部 DB 操作を確認してください(外部データベースへのアクセス確認 の「DB 操作の確認」)。問題があれば外部 DB 管理者に連絡してください。
-
外部 DB 操作に問題がなければ、KE2 APP 側での DB 接続セッションの問題の可能性があります。kengine を再起動してください。
外部DBシングル構成
# kengine コンテナ ID: $ docker ps -a -f name=kengine で取得できます $ docker restart <KENGINE_CONTAINER_ID>Swarmクラスタ構成
$ docker service update --force $(docker service ls | grep kengine | awk '{print $2}')
解決しない場合
docker
サービスを再起動してください(systemctl restart docker.service)。それでも回復しない場合は問い合わせ前に情報を収集のうえ、サポートへお問い合わせください。
外部 DB が停止(Connection refused)
対象構成: 外部DBシングル構成・Swarmクラスタ構成
主なエラーメッセージ
connection to server at "<DB_IP>", port <DB_PORT> failed: Connection refused
ログのサンプルエントリ
Reconnecting to the database didn't help connection to server at "10.20.47.20", port 5432 failed: Connection refused
Is the server running on that host and accepting TCP/IP connections?
上記サンプルのポート
5432は外部 DB へ直接接続する構成での PostgreSQL 既定値です。pgpool/クラスタ経由で接続する構成では既定9999になるなど、構成により異なります。
原因
データベースが停止してしまった場合に発生します。
解決策
外部データベースへのアクセス確認 を確認してみてください。
外部 DB の保守手順については、本マニュアルの範囲外になります。
rabbitmq の原因と対処
rabbitmq コンテナのログに記録されるエラーから、原因と対処を調べます。「全構成共通」のアラームと、「Swarmクラスタ構成固有」のクラスタ関連エラーに分けて示します。
- 影響範囲: rabbitmq の役割と影響範囲
全構成共通
ディスクリソース制限アラーム
主なエラーメッセージ
disk resource limit alarm set on node 'rabbit@...' /
Free disk space is insufficient
ログのサンプルエントリ
2024-09-05 12:54:04.298460+09:00 [info] <0.476.0> Free disk space is insufficient. Free bytes: 647168. Limit: 50000000
2024-09-05 12:54:04.298588+09:00 [warning] <0.472.0> disk resource limit alarm set on node 'rabbit@mq-ke2-rhel89-swarm-1'.
2024-09-05 12:54:04.298588+09:00 [warning] <0.472.0> *** Publishers will be blocked until this alarm clears ***
原因
ノード上の空きディスクスペースが設定された threshold 値(デフォルト 50MB)を下回ると、RabbitMQ がディスクリソース制限アラームを発生させ、ディスクスペースが解放されるまでパブリッシャーをブロックします。
解決策
-
RabbitMQ の
Alarmsステータスを確認します。$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl statusAlarmsが残っている場合、Free disk space alarm on node rabbit@...のように表示されます。 -
VM で利用可能なディスクスペースを確認します(
df -h)。空きが不足している場合は不要なファイルを削除し、Alarmsが(none)になることを確認します。RabbitMQ は自動的に正常に戻るはずです。 -
正常に戻らない場合、rabbitmq コンテナを再起動してください(
docker ps -a -f name=rabbitmqで ID を取得しdocker restart <CONTAINER_ID>)。
解決しない場合
KE2 APP を再起動するを試してください。
メモリリソース制限アラーム
主なエラーメッセージ
memory resource limit alarm set on node 'rabbit@...'
ログのサンプルエントリ
2024-09-25 21:42:10.868015+09:00 [warning] <0.475.0> memory resource limit alarm set on node 'rabbit@mq-ke2-rhel89-swarm-1'.
2024-09-25 21:42:10.868015+09:00 [warning] <0.475.0> *** Publishers will be blocked until this alarm clears ***
原因
RabbitMQ のための十分なメモリが空いていない場合に発生します。
解決策
- RabbitMQ の
Alarmsステータスを確認します(rabbitmqctl status)。Memory alarm on node rabbit@...のように表示されます。 - ホストサーバのメモリ使用率が高い場合は、ホストサーバのリソース状況の確認
を確認し、メモリを解放してください。
Alarmsが(none)になれば RabbitMQ は正常に戻るはずです。 - 正常に戻らない場合、rabbitmq コンテナを再起動してください。
解決しない場合
KE2 APP を再起動するを試してください。
Swarmクラスタ構成固有
以下はクラスタ構成(rabbitmq 3 ノードクラスタ)で発生するエラーです。クラスタ状態の確認には次のコマンドを用います。
$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl cluster_status
Basics
Cluster name: rabbit@mq-ke2-rhel89-swarm-1
Disk Nodes
rabbit@mq-ke2-rhel89-swarm-1
rabbit@mq-ke2-rhel89-swarm-2
rabbit@mq-ke2-rhel89-swarm-3
Running Nodes
rabbit@mq-ke2-rhel89-swarm-1
rabbit@mq-ke2-rhel89-swarm-2
rabbit@mq-ke2-rhel89-swarm-3
Alarms
(none)
Network Partitions
(none)
(以下、Versions / CPU Cores / Listeners / Feature flags などは省略)
Cluster name が存在することと、Running Nodes に 3
台あることを確認します。なければノード間通信(ネットワーク導通の確認)を確認します。Alarms
や Network Partitions に項目が出ていないかもあわせて確認します。
Mnesia データベースが破損している
主なエラーメッセージ
Mnesia function failed 99 times. Possibly an infinite retry loop; trying one last timereason: reached_max_restart_intensity
ログのサンプルエントリ
[warning] Mnesia->Khepri fallback handling: Mnesia function failed 99 times. Possibly an infinite retry loop; trying one last time
[error] exception exit: {aborted,{no_exists,[rabbit_runtime_parameters,cluster_name]}}
[error] supervisor: {<0.34209.0>,rabbit_connection_sup} errorContext: shutdown reason: reached_max_restart_intensity
原因
長時間にわたるネットワーク分断やスプリットブレインにより、Mnesia データベースが破損した場合に発生することがあります。
解決策
-
rabbitmq クラスタ状況を確認します(
rabbitmqctl cluster_status)。Running Nodesが 3 台なければ ネットワーク導通の確認 を実施してください。 -
rabbitmq をリセットします。
$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl stop_app $ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl reset $ docker exec $(docker ps -q -f name=rabbitmq) rabbitmqctl start_app -
正常に戻らない場合、rabbitmq コンテナを再起動してください(
docker restart <RABBITMQ_CONTAINER_ID>)。 -
解決できない場合は、各ノードの RabbitMQ のボリュームを削除する必要があります。RabbitMQ のボリュームを削除する手順 を参照してください。
Partial partition detected
主なエラーメッセージ
Partial partition detected /
Cluster minority/secondary status detected - awaiting recovery
ログのサンプルエントリ
[error] <0.514.0> Partial partition detected:
[error] <0.514.0> * We saw DOWN from rabbit@mq-ke2-rhel89-swarm-2
[error] <0.514.0> * We can still see rabbit@mq-ke2-rhel89-swarm-3 which can see rabbit@mq-ke2-rhel89-swarm-2
[error] <0.514.0> * pause_minority mode enabled
[warning] <0.514.0> Cluster minority/secondary status detected - awaiting recovery
原因
RabbitMQ クラスタ内で部分的なネットワーク分割(パーシャルパーティション)が検出されたために発生します。ネットワークの不具合や一部ノード間の通信断によりスプリットブレインの状態が引き起こされ、クラスタの一貫性が失われたことを意味します。
解決策
-
ノード間通信を確認します(ネットワーク導通の確認)。
-
RabbitMQ のステータスを確認します。
$ docker exec $(docker ps -q -f name=rabbitmq) rabbitmq-diagnostics -q check_running実行中なら
RabbitMQ on node rabbit@mq-<HOSTNAME> is fully booted and running、停止中なら... is not running or has not fully booted yetと表示されます。 -
ネットワークパーティションが解消されたが少数派ノードの RabbitMQ が一時停止状態の場合、停止したノードの rabbitmq を起動します(
rabbitmqctl start_app)。起動しても戻らない場合は rabbitmq コンテナを再起動(docker restart <CONTAINER_ID>)、それでも異常ならsystemctl restart docker.serviceを実行してください。
Waiting for Mnesia tables
主なエラーメッセージ
Waiting for Mnesia tables for 30000 ms, N retries leftError while waiting for Mnesia tables
ログのサンプルエントリ
[warning] <0.254.0> Error while waiting for Mnesia tables: {timeout_waiting_for_tables, ['rabbit@mq-ke2-rhel89-swarm-3','rabbit@mq-ke2-rhel89-swarm-2','rabbit@mq-ke2-rhel89-swarm-1'], ...}
[info] <0.254.0> Waiting for Mnesia tables for 30000 ms, 6 retries left
原因
ネットワークが 30 秒以上中断された、またはリモートの RabbitMQ ノードが 30 秒以上接続できない場合に発生します。
解決策
ノード間通信に一時的な問題があっても、RabbitMQ は内部的に再試行を行い自動回復する場合があります(約 9 回 × 30 秒 = 約 5 分)。多くは自動回復しますが、復旧しない場合は以下を進めてください。
- ノード間通信を確認します(ネットワーク導通の確認)。
- RabbitMQ のステータスを確認します(
rabbitmq-diagnostics -q check_running)。 - 少数派ノードの RabbitMQ が停止状態の場合、停止したノードの rabbitmq
を起動します(
rabbitmqctl start_app)。戻らない場合は rabbitmq コンテナを再起動、それでも異常なら全ノードの rabbitmq を再起動してください(docker service update --force ke2_rabbitmq)。
erl_crash / inconsistent_cluster(BOOT FAILED)
主なエラーメッセージ
Crash dump is being written to: /var/log/rabbitmq/erl_crash.dumpBOOT FAILED/inconsistent_cluster
ログのサンプルエントリ
Crash dump is being written to: /var/log/rabbitmq/erl_crash.dump...done
BOOT FAILED
===========
Error during startup: {error,
{inconsistent_cluster,
"Mnesia: node 'rabbit@mq-ke2-rhel89-swarm-1' thinks it's clustered with node 'rabbit@mq-ke2-rhel89-swarm-3', but 'rabbit@mq-ke2-rhel89-swarm-3' disagrees"}}
Runtime terminating during boot (terminating)
解決策
- ノード間通信を確認します(ネットワーク導通の確認)。
- 正常に戻らない場合、rabbitmq コンテナを再起動してください(
docker restart <CONTAINER_ID>)。それでも異常ならsystemctl restart docker.serviceを実行してください。 - 解決できない場合は、各ノードの RabbitMQ のボリュームを削除する必要があります。RabbitMQ のボリュームを削除する手順 を参照してください。
leader saw pre_vote_rpc for unknown peer
主なエラーメッセージ
leader saw pre_vote_rpc for unknown peer
ログのサンプルエントリ
[warning] <0.1454.0> queue 'default/rpc_queue' in vhost '/': leader saw pre_vote_rpc for unknown peer {'%2F_default/rpc_queue','rabbit@mq-ke2-rhel89-swarm-2'}
原因
RabbitMQ のクラスタ設定が他のノードと同じ状態になっていない場合に発生する可能性があります。
解決策
- rabbitmq クラスタ状況を確認します(
rabbitmqctl cluster_status)。Running Nodesが 3 台なければ ネットワーク導通の確認 を実施してください。 - 全てのノードの rabbitmq を再起動してください(
docker service update --force ke2_rabbitmq)。 - 解決できない場合は、各ノードの RabbitMQ のボリュームを削除する必要があります。RabbitMQ のボリュームを削除する手順 を参照してください。
kompira の原因と対処
kompira コンテナのログに記録されるエラーから、原因と対処を調べます。
静的ファイルにアクセスできない(KeyError: 'staticfiles')
対象構成: Swarmクラスタ構成(GlusterFS 利用時)
観測される症状・影響
GlusterFS ボリュームが利用できないため、kompira が静的ファイルにアクセスできず、ブラウザ画面が崩れる・内部処理エラーになる可能性があります。
- 影響範囲: kompira の役割と影響範囲
主なエラーメッセージ
KeyError: 'staticfiles'OSError: [Errno 107] Socket not connected: '/var/opt/kompira/html/staticfiles.json'
ログのサンプルエントリ
File "/usr/local/lib/python3.11/site-packages/django/core/files/storage/filesystem.py", line 68, in _open
return File(open(self.path(name), mode))
OSError: [Errno 107] Socket not connected: '/var/opt/kompira/html/staticfiles.json'
[2024-08-14 12:52:10,444:ap-ke2-rhel89-swarm-3:MainProcess:uWSGIWorker5Core0] ERROR: database error: [Errno 107] Socket not connected: '/var/opt/kompira/html/staticfiles.json'(OSError(107, 'Socket not connected'))
Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/django/core/files/storage/handler.py", line 35, in __getitem__
return self._storages[alias]
KeyError: 'staticfiles'
原因
静的ファイルを提供する GlusterFS ボリュームが利用できない、またはクラッシュした場合に発生します。kompira の Django アプリケーションがこのボリュームに格納された静的ファイルにアクセスしようとして接続できず、エラーになります。
解決策
-
KE2 APP ホストサーバでリソース使用率が高い場合、ホストサーバのリソース状況の確認 を確認してください。
-
GlusterFS のボリュームアクセスの問題が考えられます。共有ファイルシステム(glusterfs)の正常性確認 を確認してください。
-
正常に戻らない場合、kompira コンテナを再起動してください。
# kompira コンテナ ID: $ docker ps -aq -f name=kompira で取得できます $ docker restart <KOMPIRA_CONTAINER_ID>
jobmngrd(ジョブマネージャ)の原因と対処
jobmngrd コンテナのログに記録されるエラーから、原因と対処を調べます。
RabbitMQ が応答しない(AMQP connection error: connection timed out)
観測される症状・影響
jobmngrd が rabbitmq に接続できないため、リモートジョブ(実行ジョブ、スクリプトジョブ、セッションジョブ、ファイル転送ジョブなど)が実行できなくなります。
- 影響範囲: jobmngrd の役割と影響範囲
- 症状から探す: コンテナが停止している(rabbitmq)
主なエラーメッセージ
[AMQPConnector] AMQP connection error: connection timed out
ログのサンプルエントリ
[2024-10-27 11:59:36,322:jm-ke2-rhel89-swarm-1:kompira_jobmngrd:MainThread] ERROR: [AMQPConnector] AMQP connection error: connection timed out
[2024-10-27 11:59:36,323:jm-ke2-rhel89-swarm-1:kompira_jobmngrd:MainThread] INFO: [AMQPConnector] waiting 30 seconds for retry connection ...
[2024-10-27 12:00:06,323:jm-ke2-rhel89-swarm-1:kompira_jobmngrd:MainThread] INFO: [AMQPConnector] _connect start
[2024-10-27 12:00:36,325:jm-ke2-rhel89-swarm-1:kompira_jobmngrd:MainThread] ERROR: [AMQPConnector] AMQP connection error: connection timed out
原因
rabbitmq コンテナが応答していない可能性があります。
解決策
rabbitmq の状態を調査してください。
- rabbitmq 名前解決エラー(nc: bad address 'rabbitmq')(オンプレシングル構成)
- rabbitmq の原因と対処(Swarmクラスタ構成の rabbitmq 障害)
nginx の原因と対処
nginx コンテナのログに記録されるエラーから、原因と対処を調べます。
upstream timed out
観測される症状・影響
ブラウザアクセスがタイムアウトする、または 502/504 などのエラーになります。
- 影響範囲: nginx の役割と影響範囲
- 症状から探す: ブラウザでの基本操作による診断手順
主なエラーメッセージ
upstream timed out (110: Operation timed out) while reading response header from upstream
ログのサンプルエントリ
2024/09/11 20:01:43 [error] 23#23: *870 upstream timed out (110: Operation timed out) while reading response header from upstream, client: 10.0.0.2, server: 0.0.0.0, request: "GET /process?is_active=True&... HTTP/1.1", upstream: "uwsgi://10.0.2.29:8000", host: "10.20.47.11"
10.0.0.2 - - [11/Sep/2024:20:01:43 +0900] "GET /process?is_active=True&... HTTP/1.1" 504 569 "https://10.20.47.11/process?is_active=True" "Mozilla/5.0 ..." "-"
原因
kompira サービスがダウンしているか応答がない場合、nginx がこの種のエラーを発生させることがあります。
解決策
- 特定のコンテナ(kompira)によるリソースの過剰使用が考えられます。Docker コンテナで利用のリソース状況の確認 を確認してください。
- 特定のコンテナ(kompira)が停止された可能性があります。コンテナの正常性確認 を確認してください。
- コンテナやリソースは正常で、大きなエクスポートや重いクエリなど処理自体が正当に長い場合は、タイムアウトの延長を検討してください(特定の重い操作が一定時間で失敗する(タイムアウト))。
docker の原因と対処
docker(dockerd)のログに記録されるエラーから、原因と対処を調べます。「全構成共通」と「Swarmクラスタ構成固有」に分けて示します。
docker サービスのログ確認手順は ログの調査(採取手順) を参照してください。
全構成共通
docker デーモンが不安定
主なエラーメッセージ
http: superfluous response.WriteHeader call from go.opentelemetry.io/...
ログのサンプルエントリ
Oct 4 13:59:23 ke2-rhel89-swarm-1 dockerd[1512]: 2024/10/04 13:59:23 http: superfluous response.WriteHeader call from go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp.(*respWriterWrapper).WriteHeader (wrap.go:98)
原因
VM のリソース使用率が高い場合、さまざまなエラーが発生し、上記のようなログが頻繁に表示されることがあります。
解決策
リソース使用率が正常化すると、Docker で実行中のコンテナは通常自動的に回復します。問題が解決しない場合は以下を確認してください。
Swarmクラスタ構成固有
ネットワークの問題または特定ノードのインターフェイスのダウン
主なエラーメッセージ
memberlist: Failed to send UDP ping: ... network is unreachablebulk sync to node ... failed: ... network is unreachable
ログのサンプルエントリ
Sep 9 13:24:53 ke2-rhel89-swarm-3 dockerd[1441]: level=warning msg="memberlist: Failed to send UDP ping: write udp [::]:7946->10.20.47.12:7946: sendto: network is unreachable"
Sep 9 13:24:53 ke2-rhel89-swarm-3 dockerd[1441]: level=warning msg="bulk sync to node 26b516451957 failed: failed to send a TCP message during bulk sync: dial tcp 10.20.47.12:7946: connect: network is unreachable"
Sep 9 13:24:58 ke2-rhel89-swarm-3 dockerd[1441]: level=info msg="memberlist: Marking 26b516451957 as failed, suspect timeout reached (0 peer confirmations)"
解決策
ネットワークの問題が解決されると、Docker Swarm ノードは通常自動的に回復します。回復しない場合は
ネットワーク導通の確認
を実施してください。ノード間通信が正常に戻っても特定ノードで KE2 APP が正常に動作していない場合は、Docker
サービスを再起動してください(systemctl restart docker.service)。
外部データベースまたは Swarm ノードとの高いネットワーク遅延
主なエラーメッセージ
fatal task error" error="task: non-zero exit (1)NetworkDB stats ... healthscore:1 (connectivity issues)
ログのサンプルエントリ
Sep 11 18:32:17 ke2-rhel89-swarm-2 dockerd[785695]: level=warning msg="NetworkDB stats ke2-rhel89-swarm-2(a6a2e4038ef8) - healthscore:1 (connectivity issues)"
Sep 11 18:39:58 ke2-rhel89-swarm-2 dockerd[785695]: level=error msg="fatal task error" error="task: non-zero exit (1)" ...
解決策
ネットワークの問題が解決されると KE2 APP は自動的に回復します。回復しない場合は以下を確認してください。
- ネットワーク導通の確認
- KE2 APP ホストサーバと外部データベース間のネットワーク導通の確認
- 外部データベース間のネットワーク導通に問題があれば kengine が不安定の可能性があります。
docker ps -a -f name=kengineで kengine の状況を確認し、再起動を繰り返す場合は kengine コンテナを再起動(docker restart <CONTAINER_ID>)、戻らない場合はsystemctl restart docker.serviceを実行してください。
Docker 不安定性(node underweighting)
主なエラーメッセージ
underweighting node <NODE_ID> for service <SERVICE_ID> because it experienced 5 failures or rejections within 5m0sCould not parse VIP address while releasingFailed to allocate network resources for node ...
ログのサンプルエントリ
Sep 19 14:37:21 ke2-rhel89-swarm-1 dockerd[1064]: level=warning msg="underweighting node sw16fqkz94al7qwwqeksgtzeh for service m23oykzvchn3nc6n6cvsyebso because it experienced 5 failures or rejections within 5m0s"
Sep 19 14:37:21 ke2-rhel89-swarm-1 dockerd[1064]: level=error msg="error deallocating vip" error="invalid CIDR address: " ...
原因
あるノードが短期間に複数回の失敗やタスク拒否を経験したため、Docker Swarm のスケジューリングがこのノードの優先度を下げて他ノードにタスクを振り分けています。原因はノードの過負荷やネットワークの問題が考えられます。
解決策
- ホストサーバのリソース状況の確認
- ネットワーク導通の確認
- 特定ノードの Docker コンテナで利用のリソース状況の確認
- 特定ノードの KE2 APP が正常に戻らない場合、
systemctl restart docker.serviceを実行してください。
Swarm ノードダウン・VM ダウン・ネットワーク障害
主なエラーメッセージ
error sending message to peerrpc error: code = Unavailable ... no route to host
ログのサンプルエントリ
Sep 12 11:32:20 ke2-rhel89-swarm-1 dockerd[1428]: level=error msg="error sending message to peer" error="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing: dial tcp 10.20.47.12:2377: connect: no route to host\""
解決策
Swarm ノードとの高いネットワーク遅延
主なエラーメッセージ
i/o timeoutBulk sync to node ... timed out
ログのサンプルエントリ
Sep 24 09:23:31 ke2-rhel89-swarm-1 dockerd[1491]: level=error msg="Bulk sync to node 464a64613c02 timed out"
Sep 24 09:23:31 ke2-rhel89-swarm-1 dockerd[1491]: level=warning msg="memberlist: Failed fallback TCP ping: timeout 1s: read tcp 10.20.47.11:32850->10.20.47.13:7946: i/o timeout"
解決策
ネットワーク導通の確認 を確認してください。
Gluster ボリュームが正しくマウントされていない
主なエラーメッセージ
invalid mount config for type "bind": bind source path does not exist: /mnt/gluster/var
ログのサンプルエントリ
Sep 25 13:23:45 ke2-rhel89-swarm-1 dockerd[1444]: level=error msg="fatal task error" error="invalid mount config for type \"bind\": bind source path does not exist: /mnt/gluster/var" ...
解決策
共有ファイルシステム(glusterfs)の正常性確認 を確認してください。
error while reading from stream
主なエラーメッセージ
error while reading from stream" error="rpc error: code = Canceled desc = context canceled
ログのサンプルエントリ
Sep 2 08:47:39 ke2-rhel89-swarm-1 dockerd[752072]: level=error msg="error while reading from stream" error="rpc error: code = Canceled desc = context canceled"
原因
特定ノードのリソース使用率が高い場合に発生することがあります。
解決策
リソース使用率が正常化すると Docker で実行中のコンテナは通常自動的に回復します。回復しない場合は ホストサーバのリソース状況の確認 を確認してください。
高負荷時のチューニング(環境変数)
システム(コンテナ)は動作しているのに、高負荷で応答が遅い・一部が失敗する、といった場合の原因と、環境変数による調整の指針を示します。
前提として、まず コンテナが停止している / コンテナが異常・再起動を繰り返す と、ホストサーバのリソース状況の確認(CPU・メモリ・ディスクの逼迫)を除外してください。リソースに余裕があるのに遅い・失敗する場合に、本ページの調整が有効なことがあります。
各環境変数の既定値・詳細は 環境変数リファレンス を参照してください。本ページは「どの症状でどの変数を調整するか」の導線です。設定の反映方法は構成ごとの構築ガイドに従ってください。
データベース接続数の上限超過(too many clients already)
観測される症状・影響
画面や REST-API が 500 エラーになり、ログに次のエラーが記録されます。DB への新規接続が拒否され、処理が失敗します。
主なエラーメッセージ
FATAL: sorry, too many clients already
原因
同時に必要な DB 接続数が、接続先 PostgreSQL の最大接続数を超えています。必要な接続数はおおむね次の合計です。
- 処理中の Web リクエスト数(同時上限 =
UWSGI_PROCESSES×UWSGI_THREADS。アイドル時はほぼ 0) - kengine(エンジン本体 + Executor 数。1 Executor = 1 接続。並行ジョブフロー数では増えません)
- 管理・保守用のわずかな接続
調整
- 標準シングル構成(内部 postgres):
POSTGRES_MAX_CONNECTIONS(既定 100)を引き上げます。同時 K 件のブロッキング要求(.wait/.recv等)を捌く目安は K + 約 15。UWSGI_PROCESSES×UWSGI_THREADSを大きくする場合は連動して引き上げてください。 - 外部DBシングル構成・Swarmクラスタ構成:
POSTGRES_MAX_CONNECTIONSは無効です。接続先 DB サーバ側のmax_connectionsを同様に見積もってください。
POSTGRES_WORK_MEM× 同時接続数でメモリ使用量が膨らむため、接続数とあわせてホストの空きメモリにも注意してください(環境変数リファレンス)。
高負荷で画面・API 全体が遅い/応答が返らない(Web ワーカ枯渇)
観測される症状・影響
コンテナやホストのリソースは正常なのに、高負荷時に画面・API 全体の応答が遅くなる、または返らなくなります。ジョブフローの .wait / .recv を画面・API(HTTP)経由で多用しているときに顕著です。
原因
同時に処理できる HTTP リクエスト数は UWSGI_PROCESSES × UWSGI_THREADS です。待ち中心の処理(.wait / .recv など)が Web ワーカを長時間占有すると、この枠を使い切り、他の画面・API まで応答できなくなります。
調整
UWSGI_PROCESSES / UWSGI_THREADS / UWSGI_THUNDER_LOCK を調整します。
- 待ち中心の処理が原因なら
UWSGI_THREADS(スレッド数) を増やします。CPU を使い切る処理が原因ならUWSGI_PROCESSES(プロセス数) を増やします。 - スレッドを増やす場合は
UWSGI_THUNDER_LOCKをtrueにすることを推奨します(accept が公平化され、スレッドを増やした効果が出やすくなります)。 - 同時処理数を上げると DB 接続も増えるため、データベース接続数の上限超過 の見積り(
POSTGRES_MAX_CONNECTIONS≧ K + 約 15)も連動して見直してください。
特定の重い操作が一定時間で失敗する(タイムアウト)
観測される症状・影響
大きなエクスポート・重いクエリ・HTTP 経由の長い .wait / .recv など、特定の重い操作だけが約 300 秒(既定)で失敗する・504 になります。
原因
nginx から uWSGI への読み取り/送信タイムアウト(各既定 300 秒)で、応答途中のリクエストが打ち切られています。
調整
KOMPIRA_NGINX_UWSGI_READ_TIMEOUT / KOMPIRA_NGINX_UWSGI_SEND_TIMEOUT(各既定 300 秒)を、想定する最長リクエスト時間以上に延ばします。
UWSGI_HARAKIRI(処理時間のハードリミット)は既定で無効です。有効化する場合は全 HTTP リクエストが対象になるため、想定最長時間かつ上記タイムアウトの長い方以上の値にしてください。- なお、nginx の「upstream timed out」が kompira コンテナの停止・過負荷に起因する場合は、タイムアウト延長ではなく nginx の原因と対処 を参照してください。本項は「処理自体が正当に長い」場合の調整です。
サポートへの問い合わせ前に(情報収集)
本ガイドの診断・対処で解決しない場合は、サポートへ問い合わせる前に以下の情報を収集してください。原因が特定できていない場合でも、これらをそろえることで調査を進められます。
収集する情報
-
構成情報(必須)
- 構成種別: 標準シングル構成 / 外部DBシングル構成 / Swarmクラスタ構成のいずれか。分からない場合は次のコマンドで確認できます。
docker node lsが成功する(またはdocker infoにSwarm: activeがある)→ Swarmクラスタ構成- そうでなく、
docker ps -a -f name=postgresに postgres コンテナがある → 標準シングル構成 - postgres コンテナが無い(データベースが外部)→ 外部DBシングル構成
- Kompira のバージョン: 管理画面のバージョン表示、または稼働中の
kompira-enterpriseイメージのタグ(docker psの IMAGE 列)で確認できます。
- 構成種別: 標準シングル構成 / 外部DBシングル構成 / Swarmクラスタ構成のいずれか。分からない場合は次のコマンドで確認できます。
-
発生状況
- いつ発生したか、直前に行った操作や変更(アップグレード・設定変更など)
- うまくいかなかった操作や、画面に出ていたメッセージなど、気づいたこと
-
再現性
- 同じ操作をもう一度行ったときに再発するかを確認し、「再現する / 再現しない / 不明」を伝えてください。
- 再現する場合は、その操作手順(何をすると起きるか)もあわせて伝えてください。特定の時間帯・操作・対象でのみ起きる場合はその条件も。
-
システム・コンテナの状態
- system-status の出力: ブラウザで
/.status?format=jsonにアクセスし、表示された内容を保存してください(システムステータスによる診断手順 参照)。 - コンテナ/サービスの状態:
docker container ls(Swarmクラスタ構成はdocker service ls)の出力を保存してください(コンテナの診断手順 参照)。
- system-status の出力: ブラウザで
-
ログ
- 原因のコンポーネントが特定できない場合は、すべてのコンテナのログを採取してください。
- 採取手順: コンテナログ管理(Swarmクラスタ構成は サービスログ管理)
- 原因コンポーネントが分かっている場合は、そのコンポーネントのログだけでも構いません(原因と対処(コンポーネント別) 参照)
-
(あれば)画面のスクリーンショット
- ブラウザ画面に明らかな異常(エラー表示・画面崩れなど)が見えている場合のみ、その画面のスクリーンショットがあると役立ちます。
問い合わせ方法
サポート窓口および問い合わせ手順については、ご契約のサポート規約に従ってください。上記で収集した情報を添えて問い合わせると、迅速な対応につながります。